


Web Scraping with R: An Introduction
Contents
Data science, machine learning, and other analytical fields rely heavily on the processing and analysis of data to generate insights and make informed decisions. In these fields, data are often collected from various sources like websites, social media, and databases, and analyzed using statistical techniques and machine learning algorithms.
As the data that needs to be collected are often vast, web scraping becomes an important technique. It helps you to collect data from various sources on the internet and convert them into a structured format that can be used for analysis fast.
With R being a popular programming language for data analysis, you could scrape websites to collect data in the same programming language too. In this article, we’ll introduce you to web scraping in R, including various ways you can scrape a website in this programming language.
What is Web Scraping
Web scraping, also known as data scraping, is the process of automatically collecting data from websites using software tools. The software tools extract data from HTML, XML, or other formats and convert it into a structured format, such as a spreadsheet, database, or JSON file. The extracted data can be used for various purposes, including market research, competitive analysis, and content aggregation.
Web scraping is particularly useful when dealing with large datasets that would be time-consuming to collect manually. E-commerce companies may scrape competitor websites to collect pricing information and adjust their prices accordingly. News organizations may scrape multiple sources to aggregate news stories into a single location. Job search sites may scrape job boards to create a comprehensive job listing. These are just a few examples of how web scraping can be used to gather a large amount of valuable information in the shortest time possible, there are many other use cases where web scraping could come in handy.
Python vs. R: Which is Better for Scraping
Python is a popular choice for web scraping due to its rich ecosystem of web scraping libraries, such as Beautiful Soup, Scrapy, and Selenium. These libraries simplify the data scraping process and help you extract data from websites easily. Besides that, Python is also known for its ease of use and readability, making it a good choice for beginners who want to scrape a website.
R is a powerful and versatile programming language designed specifically for statistical computing and graphics. It is an essential tool for many statisticians, data analysts, and researchers in a wide range of fields, including finance, healthcare, and social science. What sets R apart from other statistical software is its ease of use. Publication-quality plots with mathematical symbols and formulae can be easily produced with their user-friendly and easy-to-learn syntax. Some users also find its syntax more straightforward than Python, making it easier for beginners to learn and use.
Both Python and R has its own strengths and weaknesses. The choice between the two ultimately depends on the specific project requirements and your personal preference.
🐻 Want to learn how to scrape a website using Python? Read Web Scraping with Python: An Introduction and Tutorial.
Web Scraping Libraries for R
One way to scrape a website in R is to use a web scraping library. While R may not have as many web scraping libraries as Python, there are still several of them that can make web scraping in R easier:
rvest
One of the most popular libraries for web scraping in R is rvest. It is inspired by popular Python scraping libraries like Beautiful Soup and RoboBrowser to make it easy to express common web scraping tasks. It allows you to use CSS selectors to refer to specific elements and rvest functions to get data out of HTML, and into R.
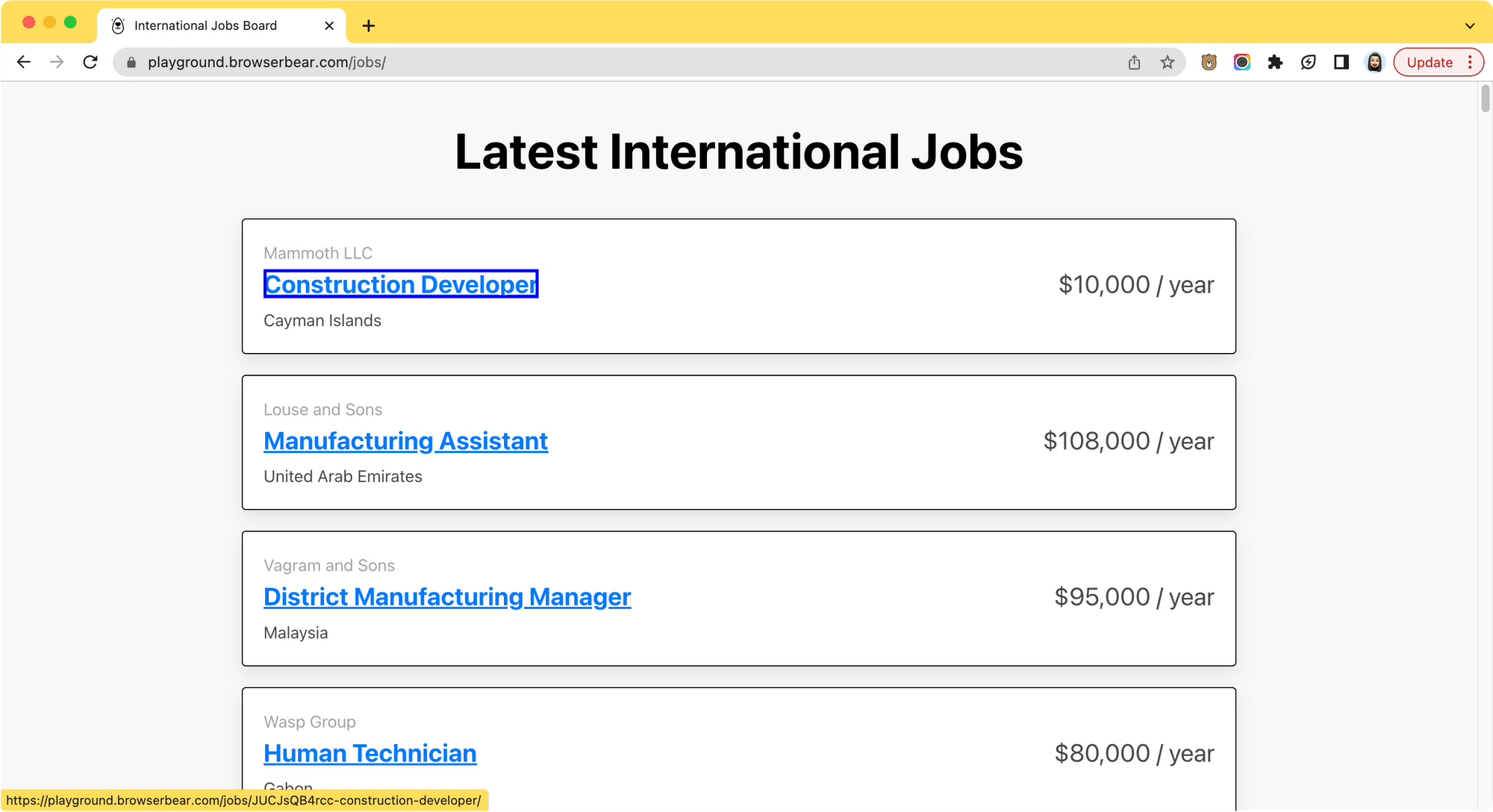
Here's an example of how to use rvest to extract the job postings from a job board:
library(rvest)
# Retrieve the HTML code
url <- "https://playground.browserbear.com/jobs/"
page <- read_html(url)
# Extract the job cards
html_card <- document %>% html_elements("h2")
# Extract the job titles
job_titles <- html_card %>% html_element("a") %>% html_text2()
# Print the titles
print(job_titles)
🐻 Bear Tips: If you’re scraping multiple pages, try using rvest with polite to ensure that you’re respecting the robots.txt and not hammering the site with too many requests.
RSelenium
RSelenium is a set of R Bindings for Selenium Remote WebDriver that works with Selenium 2.0 exclusively. It is part of the rOpenSci project, a non-profit initiative to develop R packages via community-driven learning, review, and maintenance of contributed software in the R ecosystem. Using RSelenium, you can automate browsers locally or remotely as how a real user would navigate them manually.
Here's an example of accessing an HTML element in the DOM as shown in the official documentation:
library(RSelenium)
remDr <- remoteDriver(
remoteServerAddr = "localhost",
port = 4445L,
browserName = "firefox"
)
remDr$open()
remDr$navigate("http://www.google.com/ncr")
webElem <- remDr$findElement(using = "class", "gsfi")
Rcrawler
Rcrawler is an R package that provides a set of functions for web crawling and scraping. Different from rvest which extracts data from one specific page by navigating through selectors, it automatically traverses and parses all web pages of a website, and extracts all data at once with a single command. It is a complete package that crawls, retrieves, and parses data. Besides that, you can also build a network representation of a website's internal and external links as nodes and edges using Rcrawler to study its HTML structure.
The detailed instruction on how to use the library can be found on its GitHub:
Web Scraping without a Library (Browserbear API)
The libraries above can help you scrape a website in R but they are complicated to set up. Another easier and faster method that doesn’t require installation is using an API like Browserbear.
Browserbear is a scalable, cloud-based browser automation tool that helps you to automate any browser task, including web scraping. It provides a simple user interface to help you select HTML elements on a web page using the Browserbear Helper and perform various browser actions. As you can trigger these actions by calling its API, it makes web scraping in R much easier compared to using web scraping libraries.
Next, let's see how you can use it in your R code. You will need a Browserbear account before proceeding to the next step. Create a trial account for free.
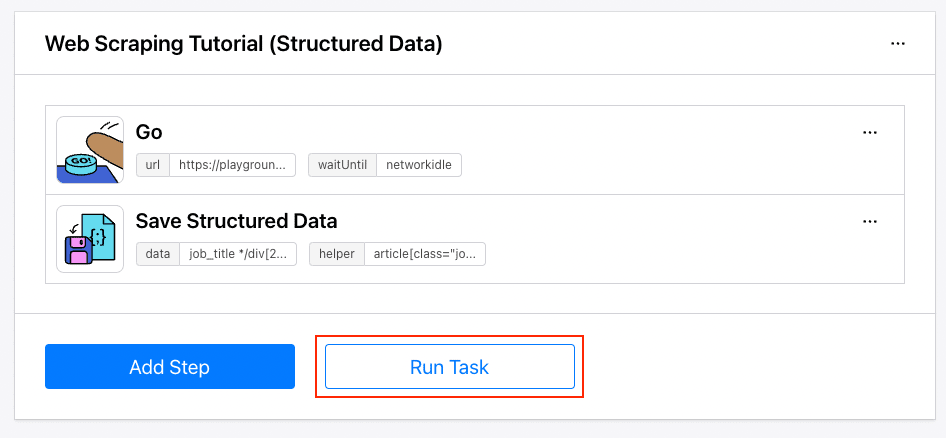
Step 1. Create a Browserbear Task
Follow the instructions in How to Scrape Data from a Website Using Browserbear to create a web scraping task in Browserbear. Alternatively, you can duplicate this ready-made task from the Task Library to your account immediately.
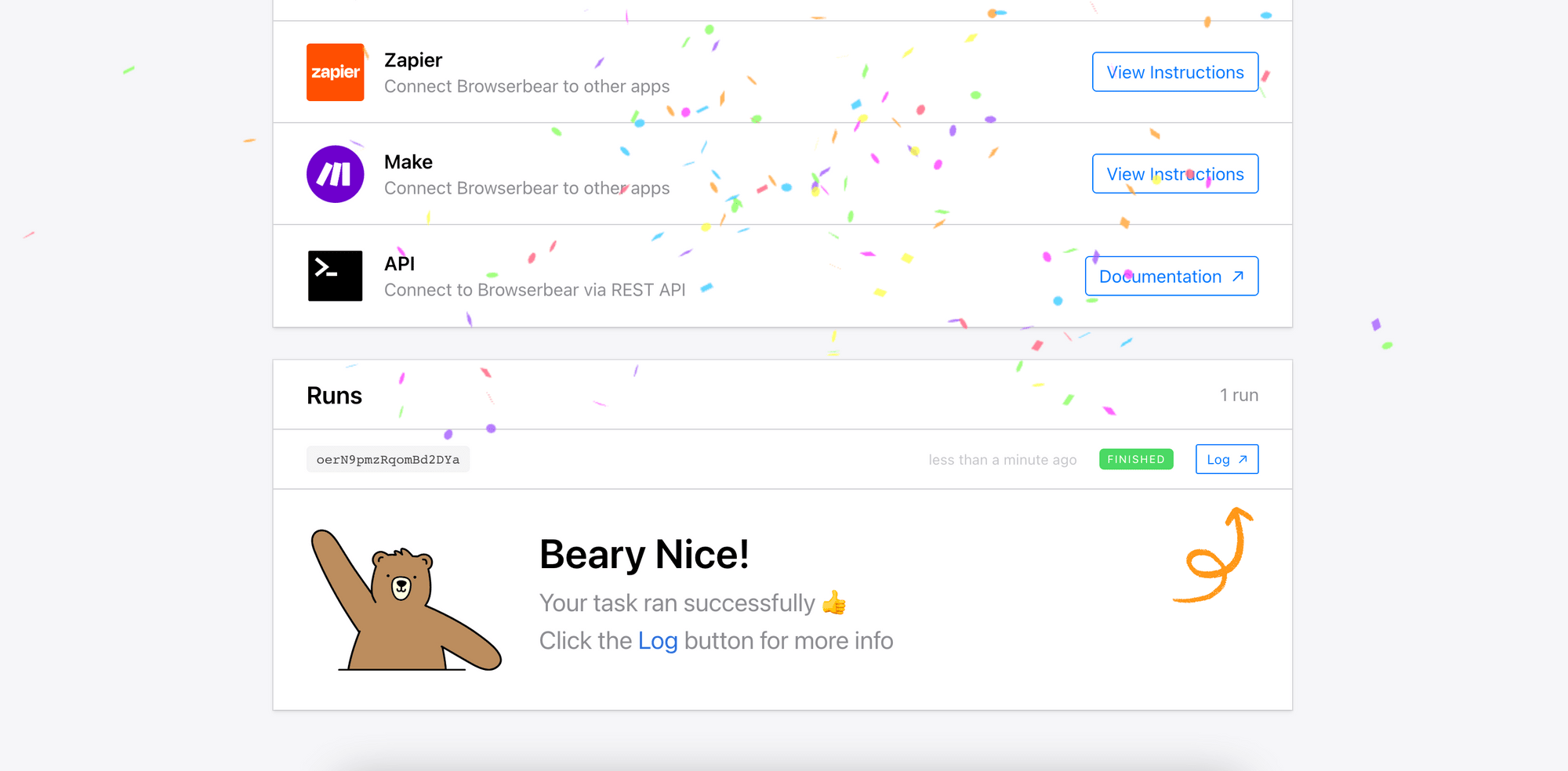
After creating the task, try running it from the dashboard.
When the run has been completed, you can view the result from the log.
Step 2. Make a POST Request to Trigger the Task
Now, we can write the code in R to trigger the task. Import the required libraries and make a POST request to Browserbear API with the task’s ID and the project’s API key to trigger the task.
library(httr)
library(jsonlite)
r <- POST("https://api.browserbear.com/v1/tasks/your_task_id/runs",
add_headers(Authorization = "Bearer your_api_key"))
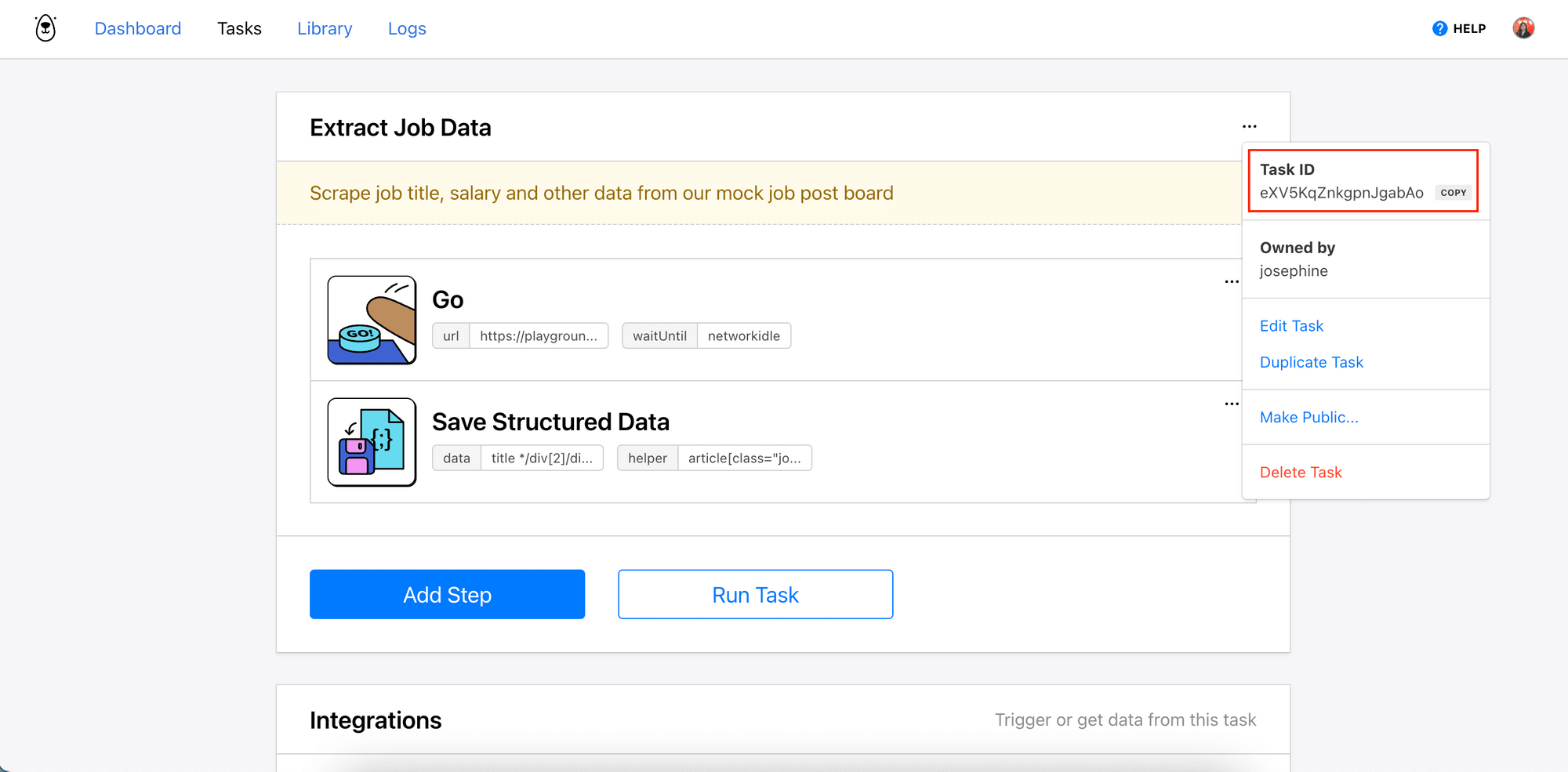
The task’s ID and the project’s API key can be found on your Browserbear account dashboard.
Every Browserbear task runs asynchronously. After making the POST request, you will receive a 202 Accepted response but to receive the result, you will need to query the GET endpoint or use a webhook.
Step 3. Make GET Requests to Receive the Result
Making a GET request to the endpoint will return the status and result of the run. When the task is still running, you will get an empty outputsarray. Keep making GET requests to the endpoint to get the latest result:
res <- GET("https://api.browserbear.com/v1/tasks/your_task_id/runs/your_run_id",
add_headers(Authorization = "Bearer your_api_key"))
data <- fromJSON(content(res, "text"))
jobs <- data$outputs$Xgna6ZmbQQrbjGl5KM_save_structured_data
Note: “Xgna6ZmbQQrbjGl5KM” is the ID of the “Save Structured Date” step, which can be retrieved from your Browserbear dashboard too.
Alternatively, you can also use a webhook to receive the result automatically when the task has finished running. To do this, you’ll need to add a webhook URL when making the POST request so that Browserbear will know where to send the result to:
r <- POST("https://api.browserbear.com/v1/tasks/your_task_id/runs",
add_headers(Authorization = "Bearer your_api_key"),
body = list(webhook_url = "https://webhook.site/addf19b2-6db9-4395-bd91-cf43a0fee0a1"))
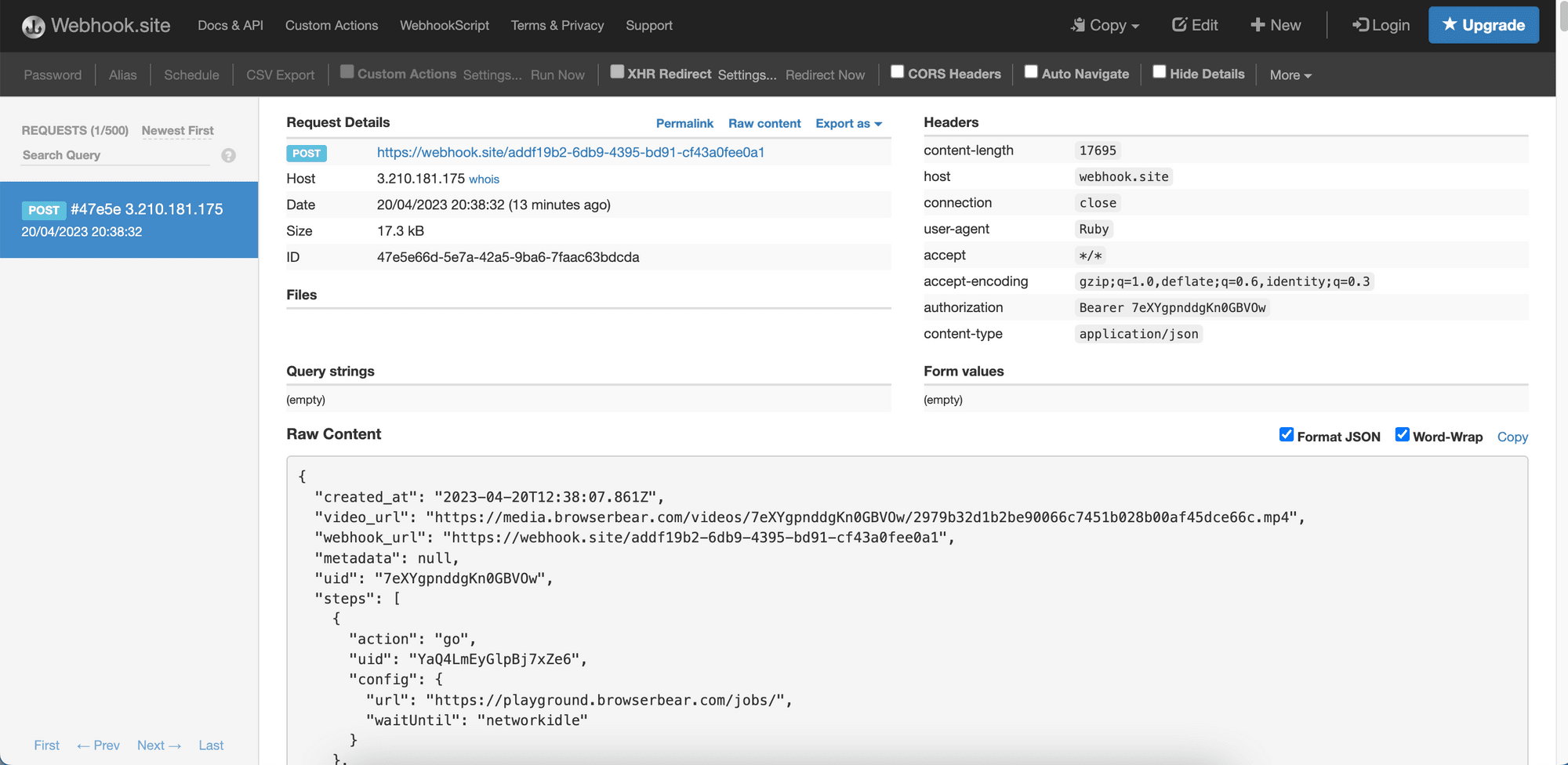
You can use Webhook.site to test the webhook. On its page, you can get a unique URL that you can use to receive the result. The result and the details of the HTTP request should be shown after you’ve made a request to the API and the task has been completed:
You should be able to find the same result in your Browserbear dashboard, under the run’s log:
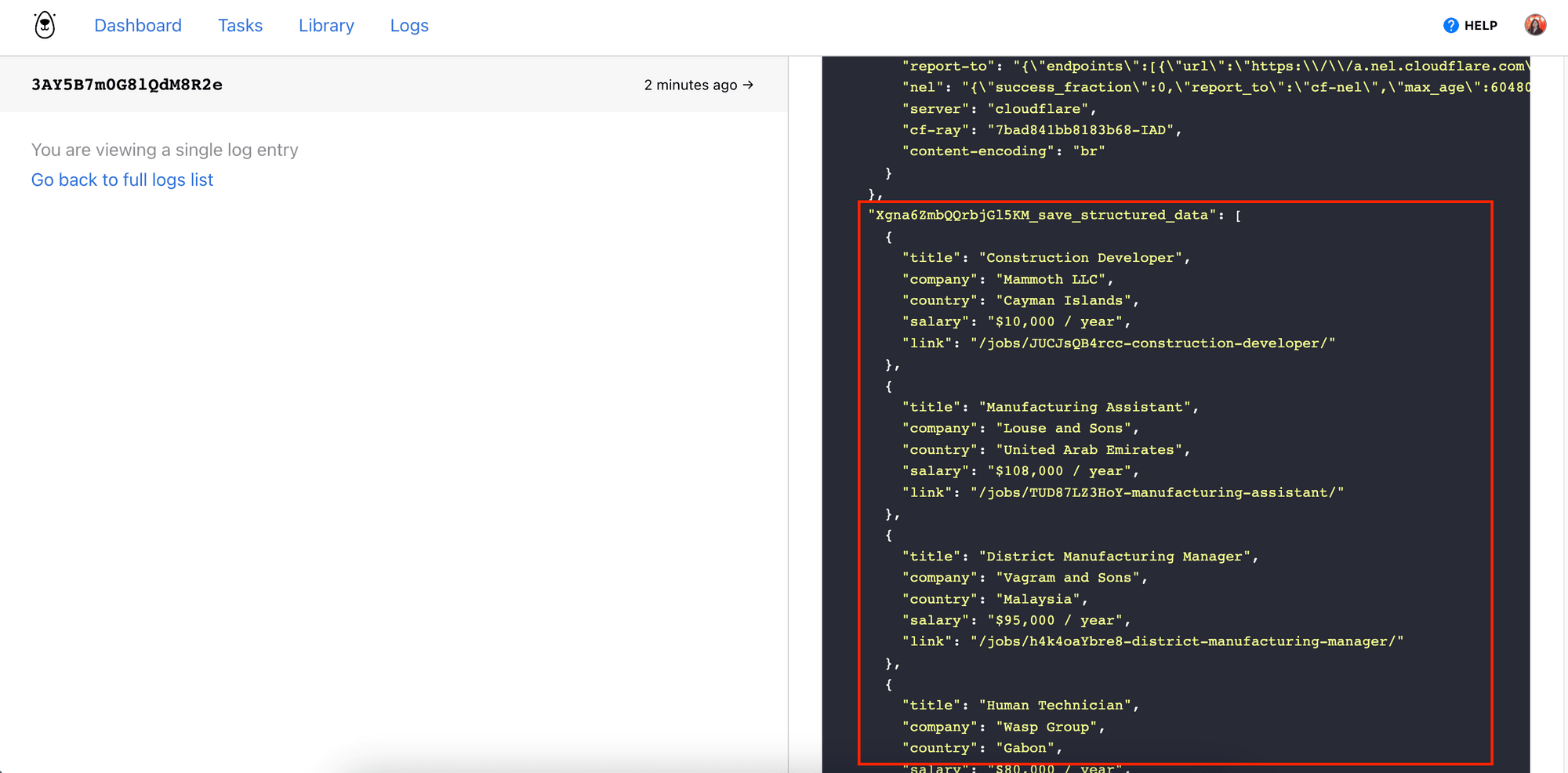
Step 4. Export the Data
Lastly, export the data into a spreadsheet.
write.csv(jobs, file = "jobs.csv")
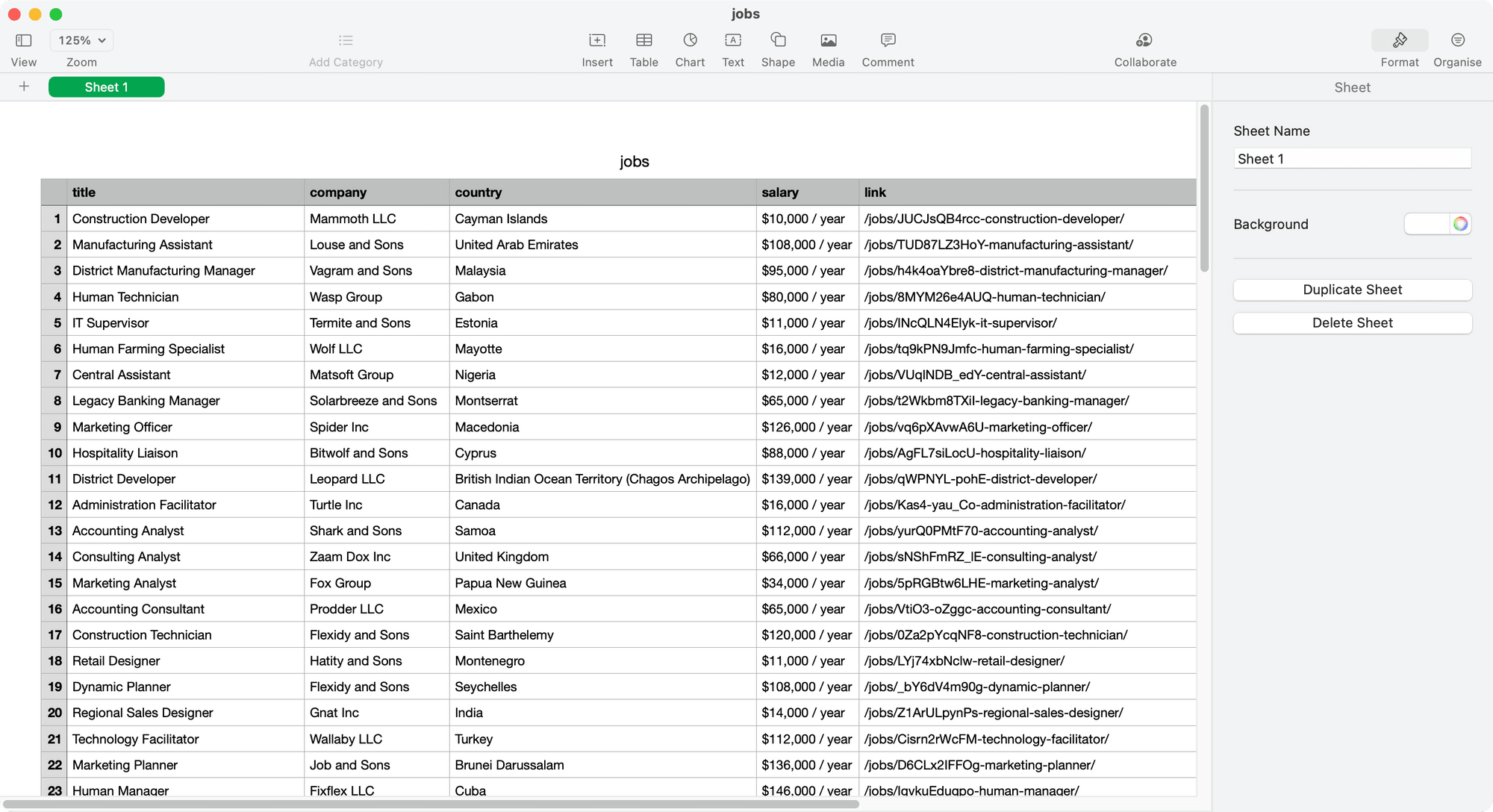
Voila! That’s how easy it is to scrape a website in R using Browserbear. To scrape other websites, you just need to create another similar Browserbear task and change the task ID and project API key in your R code.
Conclusion
In this article, we have discussed a few methods you can use to scrape a website in R, including using different web scraping libraries and using a third-party service that you can trigger via API. When it comes to which method to use, it depends on your specific requirements. Choosing one that is easy to set up, execute, and maintain like Browserbear definitely simplifies your work. Happy scraping!
