


Our Guide to Roborabbit Data Extraction (Data Types & Examples)
Contents
Browser automation tools such as Roborabbit can perform practically any action taken when manually browsing a website—clicking, loading URLs, and even filling out forms. While there are so many use cases for browser automation, it is perhaps most often used for data extraction.
You can use browser automation tools to capture data for various uses, such as:
- Comparing pricing information
- Creating marketing assets
- Updating real-time industry data
- Maintaining databases or archives
- Initiating other automated processes
When choosing a web scraping tool, it’s important to consider the data types you’re working with. Selecting something that can extract a wide variety of data types allows you to work with many websites and use cases.
Roborabbit powers a wide range of data extraction possibilities, even integrating AI to detect and extract data matching your description. Let’s walk through all of the extraction types and how you can expect them to look in your output log.
Types of Data You Can Extract with Roborabbit
Roborabbit has 10 different actions you can use to extract various pieces of data from a webpage. The majority rely on helper config (CSS selectors, XPath, JS selectors, etc.) to locate elements, but there are also AI-powered actions that use simple instruction labels to find the most relevant snippets.
When setting up a step, you can choose between AI or manually set config actions. Choosing the latter allows you to also select the type of tag you want to use for selection—CSS selectors, XPath, and so on. Roborabbit will recommend a tag, but depending on what you're trying to scrape, another might be more suitable.
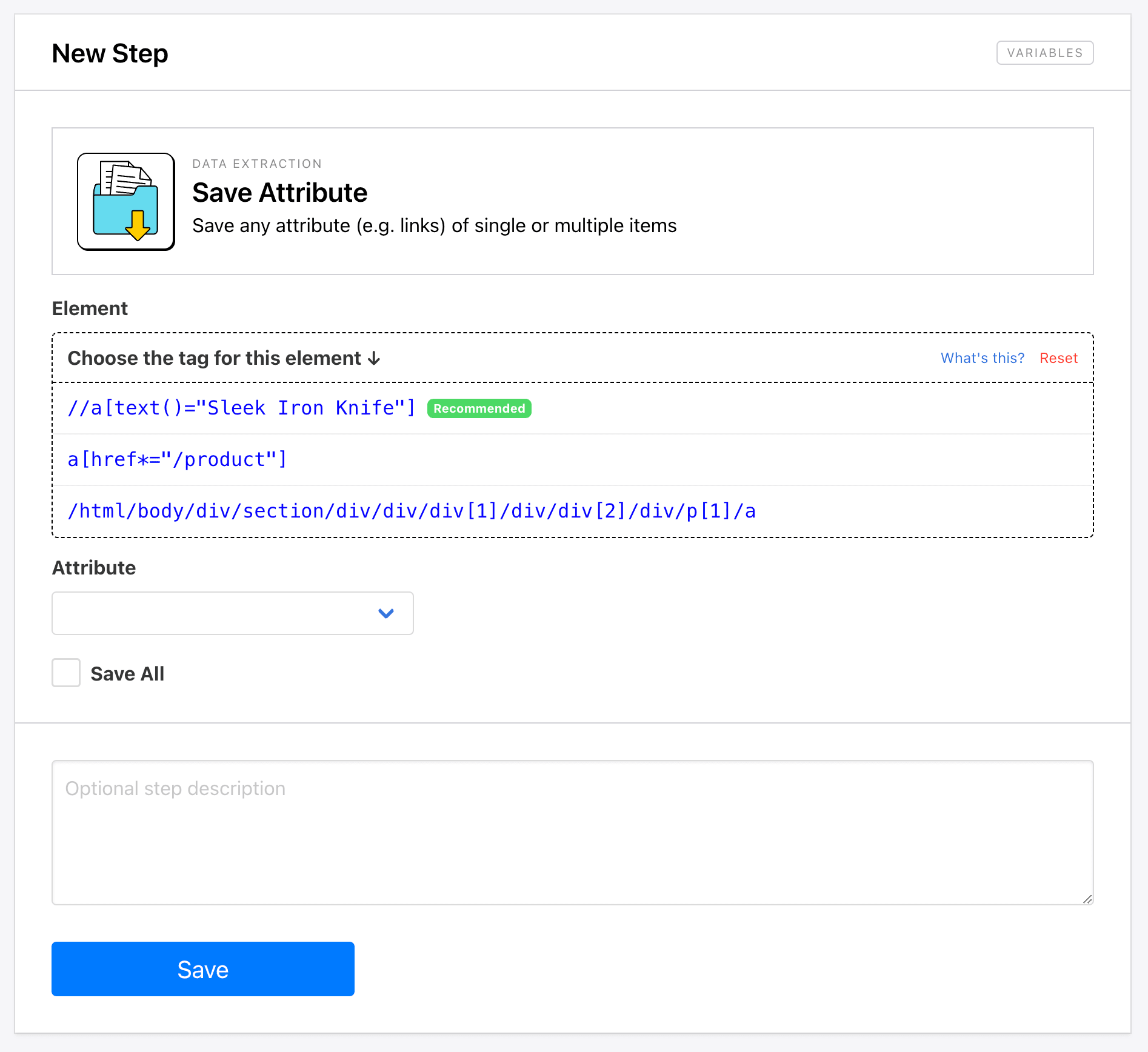
Once your selection config is all set up, you can proceed with the rest of the step as usual.
Let’s walk through the data extraction actions one by one:
Save Attribute
The Save Attribute action is a versatile option that saves any attribute of one or multiple elements. HTML attributes provide additional information about an element, such as titles, alt text, links, and more.
When setting up this action, you will need to provide Helper config to identify the element as well as specify the attribute you want to scrape (href, src, alt, etc.).
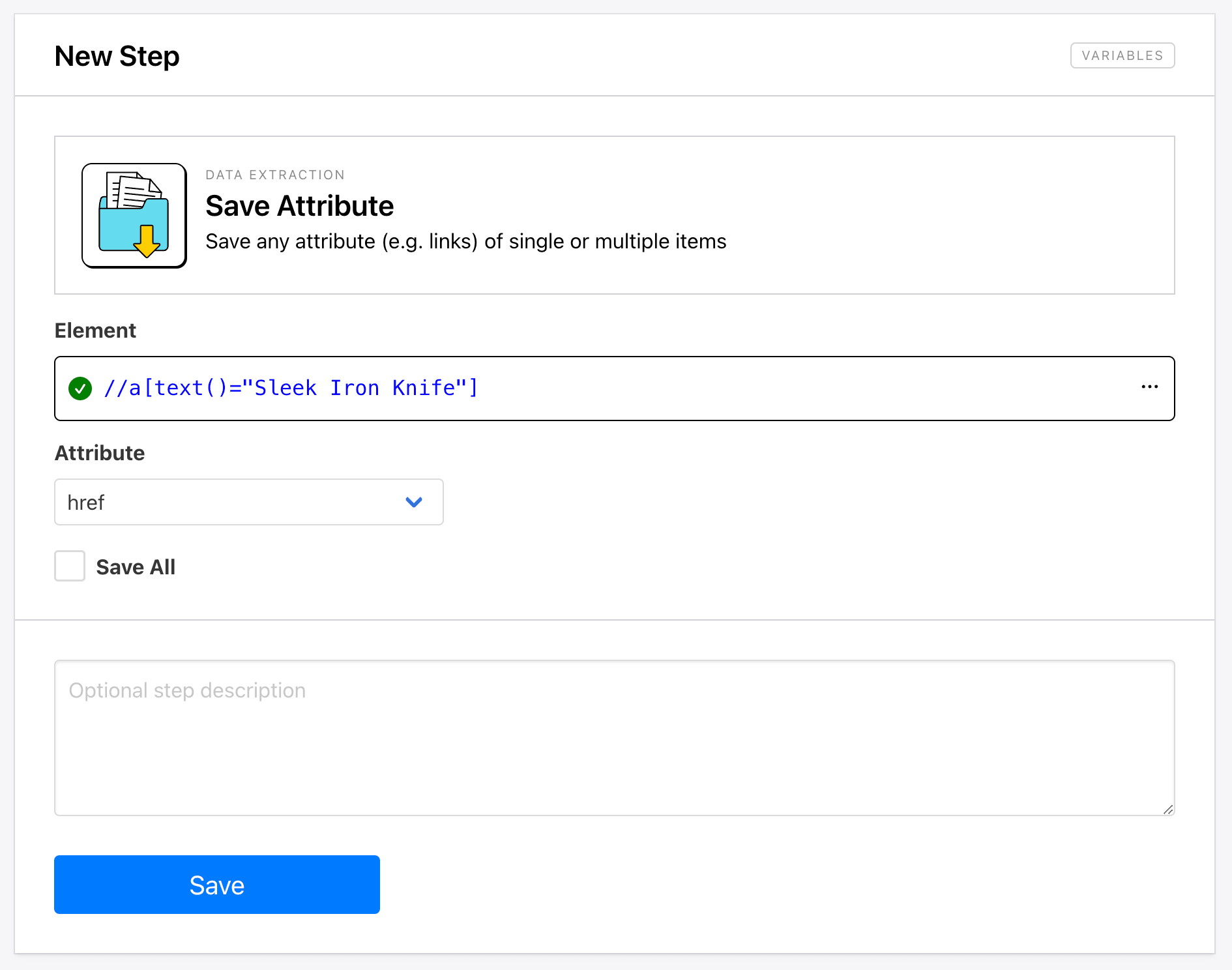
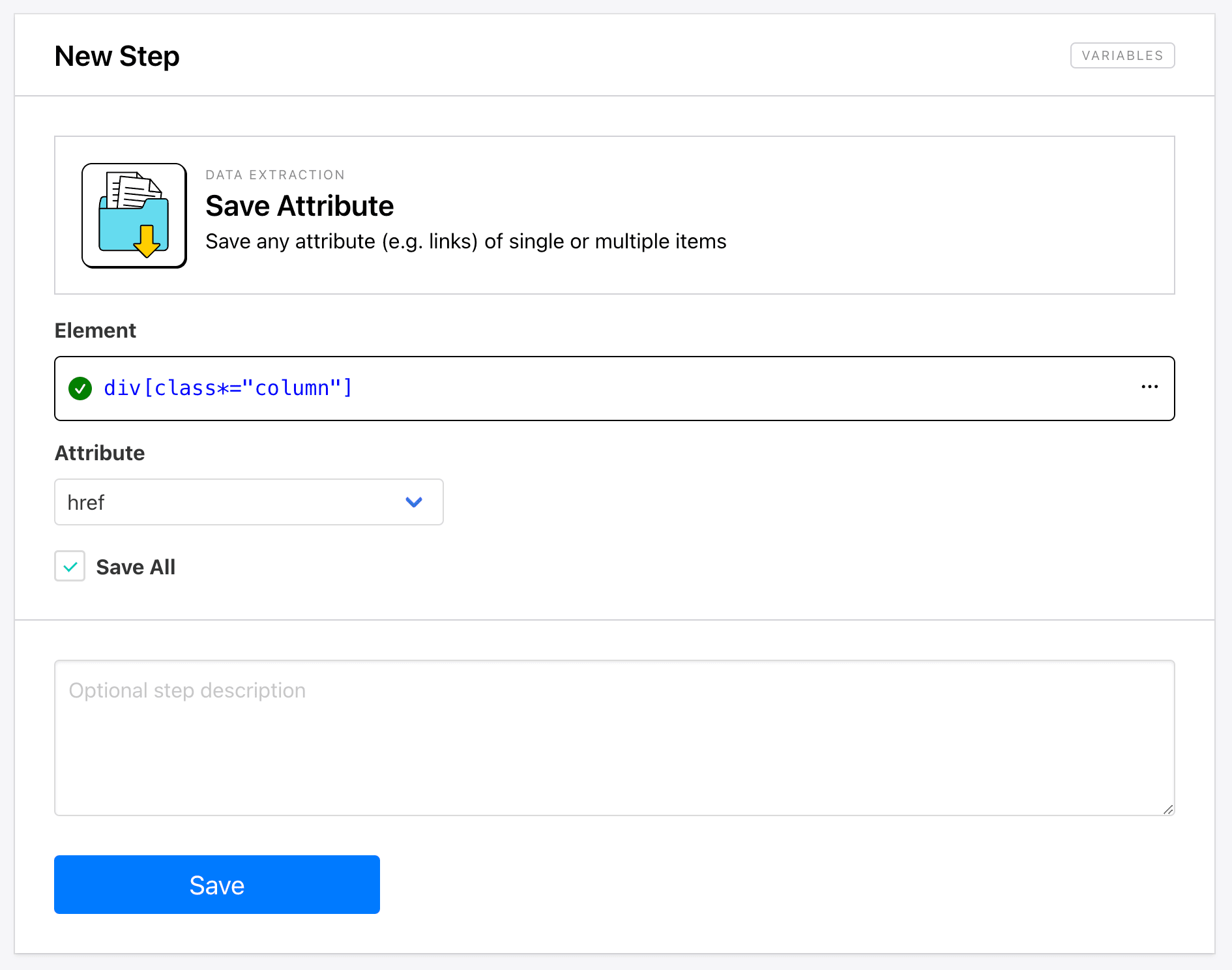
Checking All will extract the attributes of all elements matching the config.
Running a task with this action will yield an output log that looks something like this:

Save Clipboard
Save Clipboard instructs Roborabbit to save the contents of your clipboard to the output feed. This can save a lot of time building a longer task that pastes text, images, or files into an app to save it another way. Because the clipboard is only used for temporary storage, saving it to your output feed ensures you can continue accessing it for your workflows.
Setting it up is simple and only involves adding a Save Clipboard action following an action that copies something to your clipboard, such as clicking a Copy button.
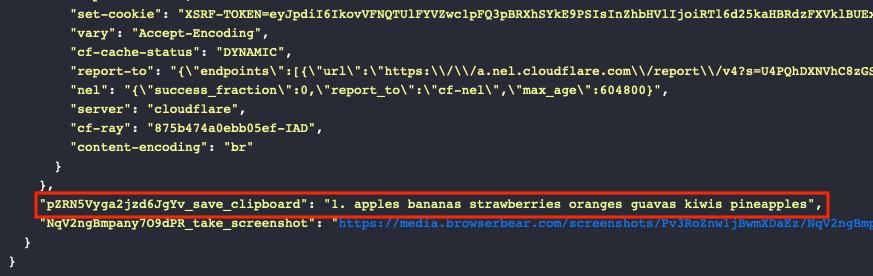
Running the task will show clipboard contents saved to your log:
Bear Tip 🐻: Another way to access clipboard contents is with the Paste interaction, which will paste clipboard content into a selected text field.
Save HTML
The Save HTML action allows you to save the entire webpage as an HTML file, which can be accessed by link. The file will be hosted on Roborabbit servers for 24 hours, after which you need to store it elsewhere for continued access.
To save the HTML of your current webpage, add the action to your task following a step that loads your page to the state you want it in.
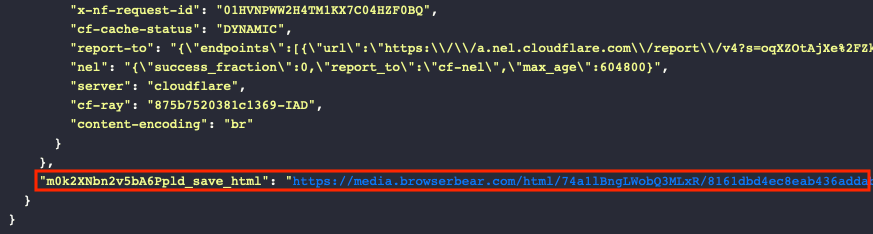
Your output log should return a link that leads to the HTML of that page.
Save Image
You can save photos on a webpage with the Save Image action. This returns link or paths which you can access in your output log, which can then be stored in a database or sent to other workflows.
Setting up a step to save images involves adding the action to your task, inserting Helper config, then clicking Save.
Checking All will extract the attributes of all elements matching the config.
Running the task should return one or more links to the specified images.
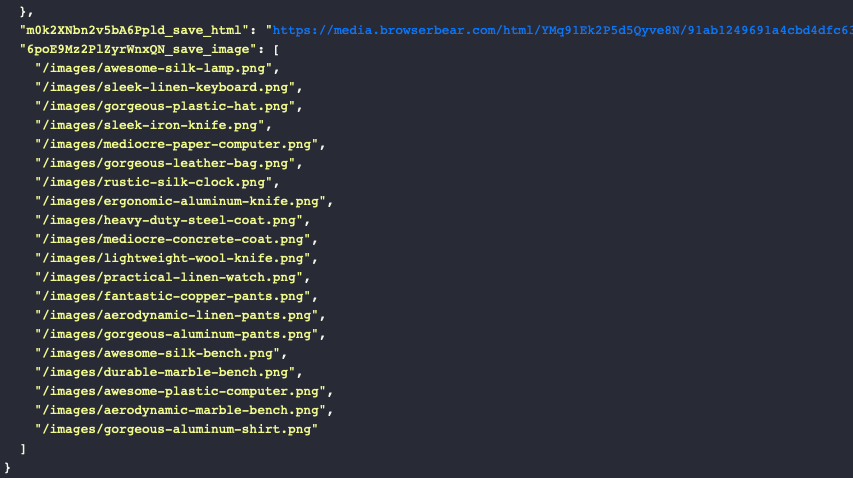
Bear Tip 🐻: This step returns links to images from the website being scraped. If you want to host these images independently, consider using Puppeteer or a tool like Zapier to create a process that downloads and saves image files according to your preferences.
Save Structured Data
The Save Structured Data action saves multiple elements from a webpage into a JSON object. It’s ideal for scraping multiple elements within identically structured parent containers, as is often the case for product pages and other types of lists.
To set up the step, you’ll need to insert Helper config that identifies a parent container, then add a label, config, and attribute to each individual child element using the Data Picker.
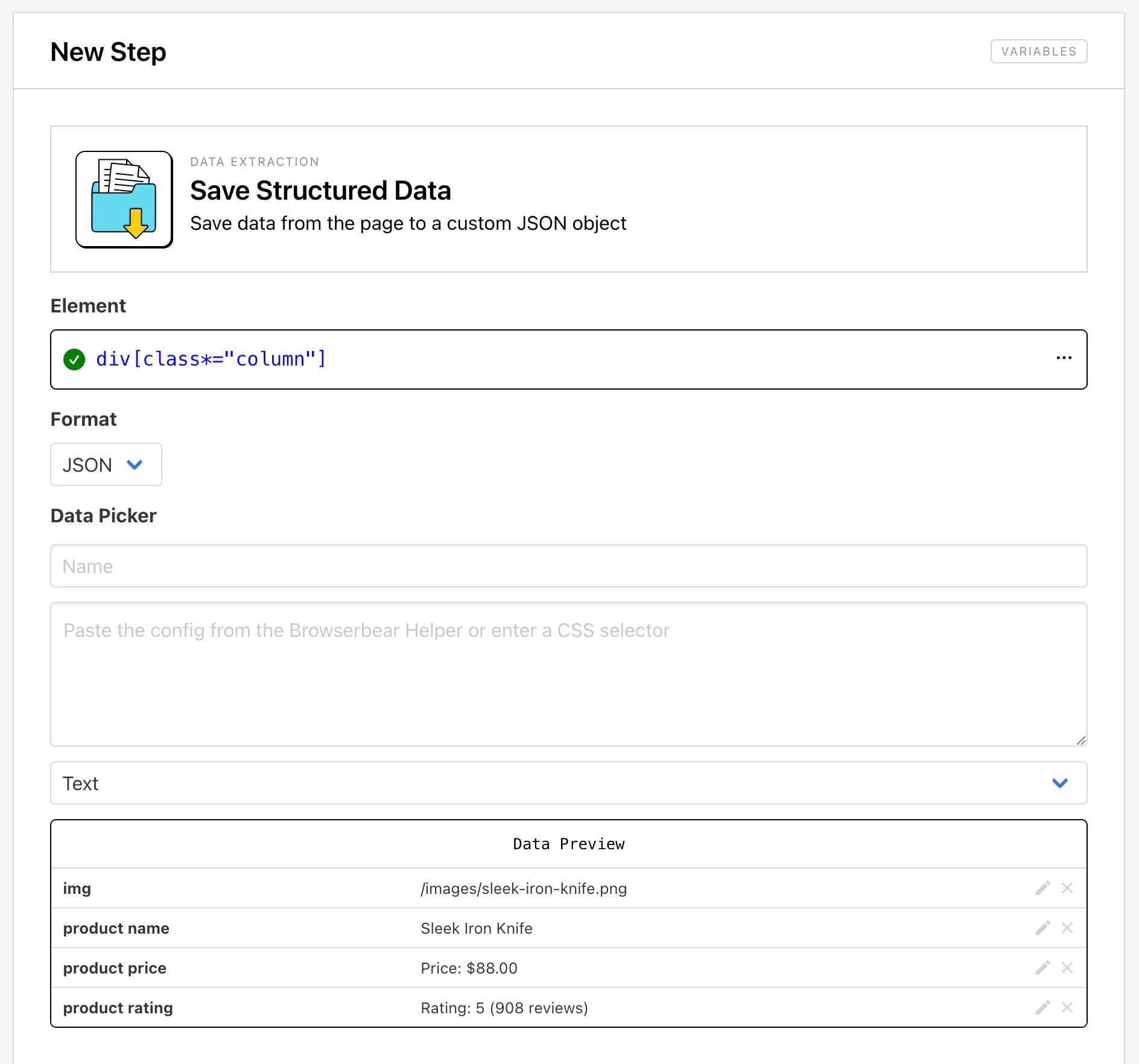
Roborabbit will scrape data from all parent containers containing the same child elements, then return it in an array:

Save Table Data
Save Table Data enables you to automatically save structured data from a table, organized by column or heading. This is especially helpful for HTML tables that would be difficult to work with if copied as plain text.
Setting up the action involves inserting config for the entire table, then specifying headings.
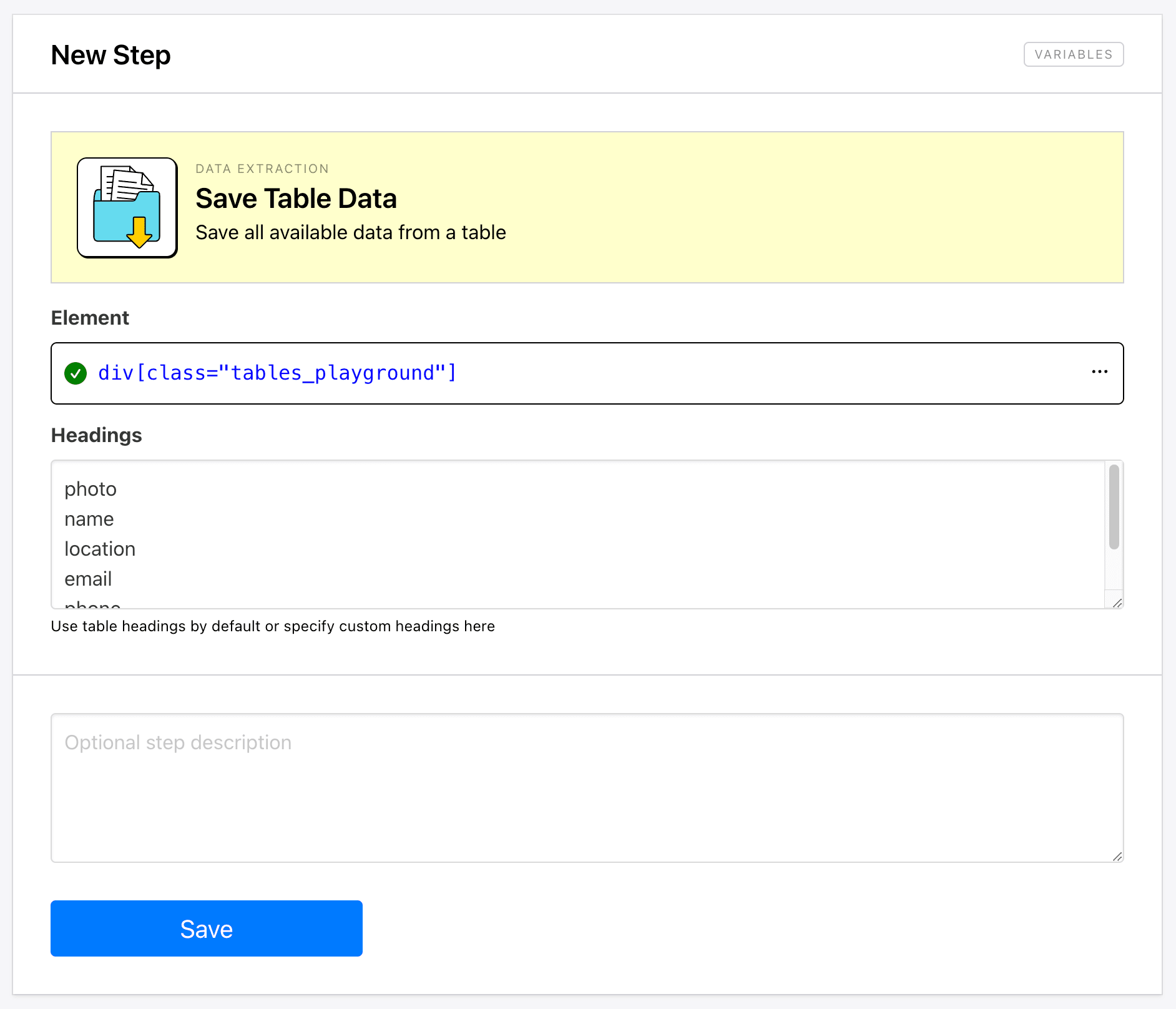
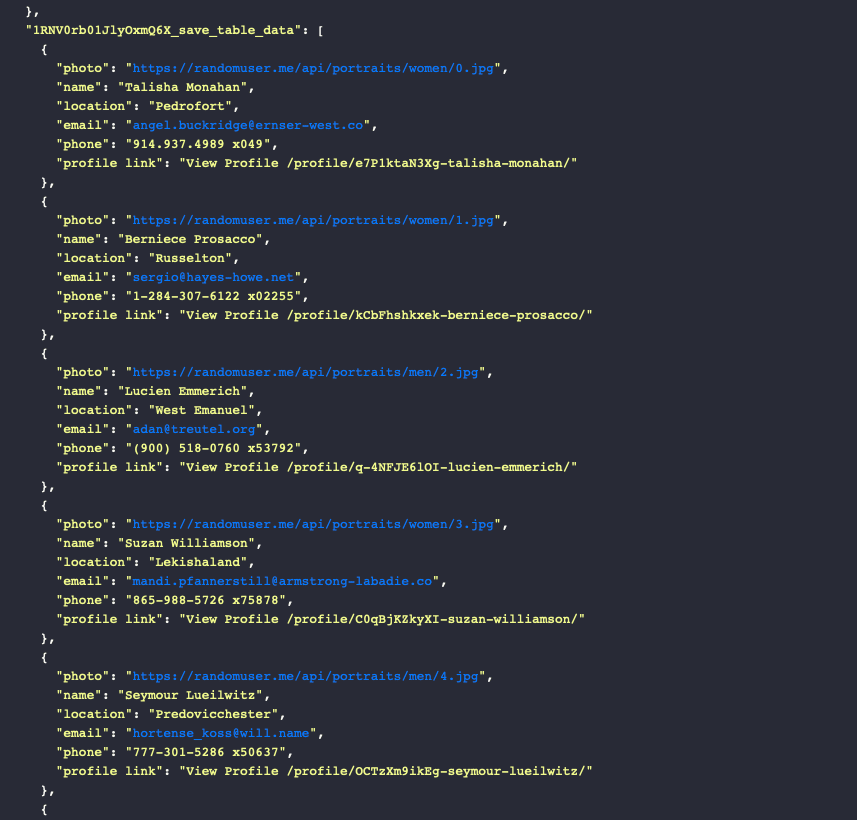
Running the task should yield an array of structured data, which you can then save to a database or table of your choice:
Save Text
This action saves text from one or multiple elements specified with config. It’s best used when you need small snippets of text and not any other types of data, in which case the Save Structured Data tool might be more appropriate.
To set it up, add a Save Text action to your task and insert config for the element.

You can also generalize the config and check All to extract multiple elements matching your identifier.
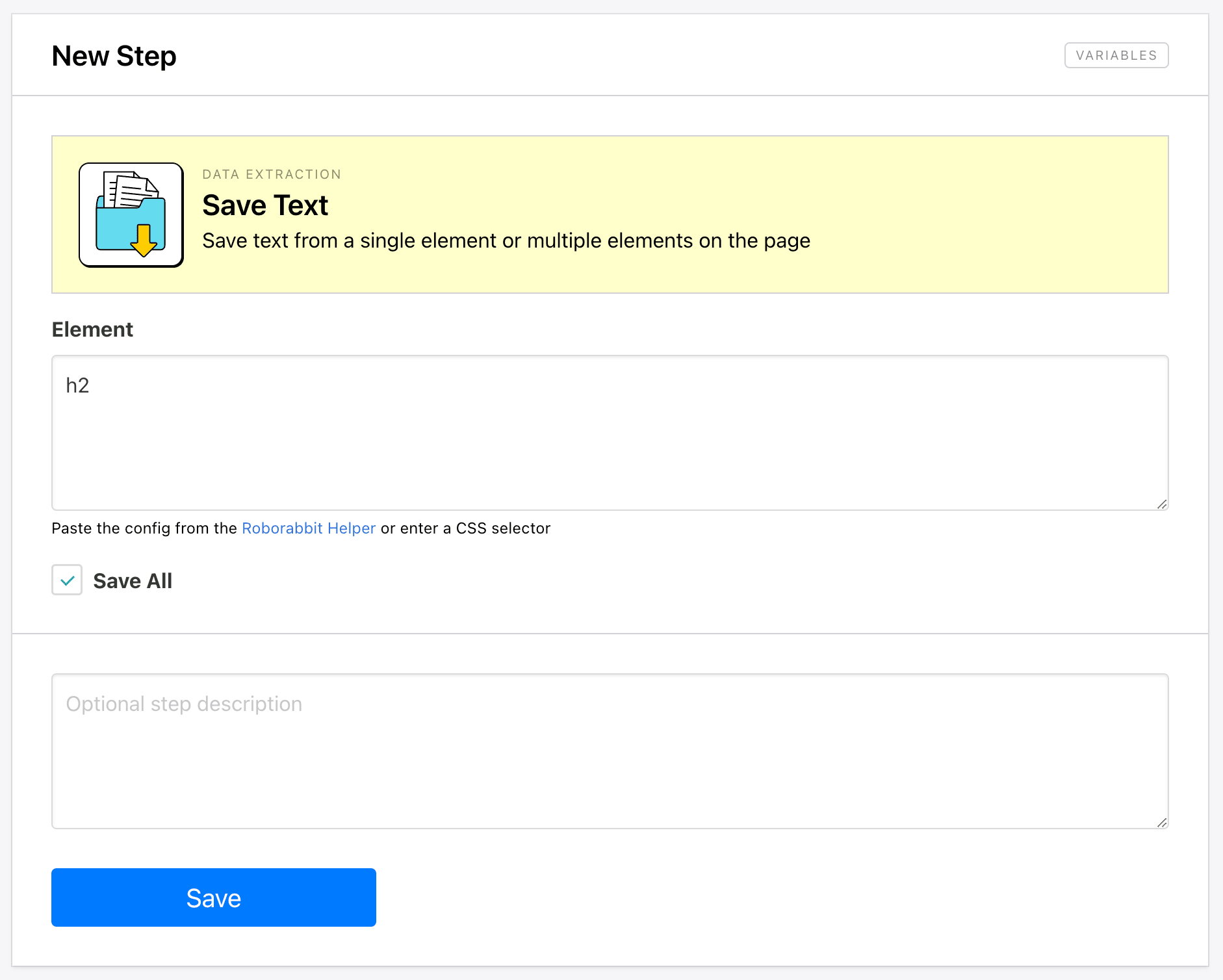
Your output log should return one or multiple lines of text:

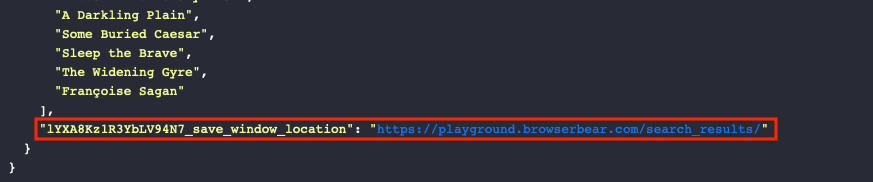
Save Window Location
Save Window Location saves the URL of your current webpage, making it easy to come back to. This can be quite helpful when you’re logging where you left off or picking up from the latest update.
Minimal setup is needed for this action, and you simply need to add it to your task at the right step of the process.
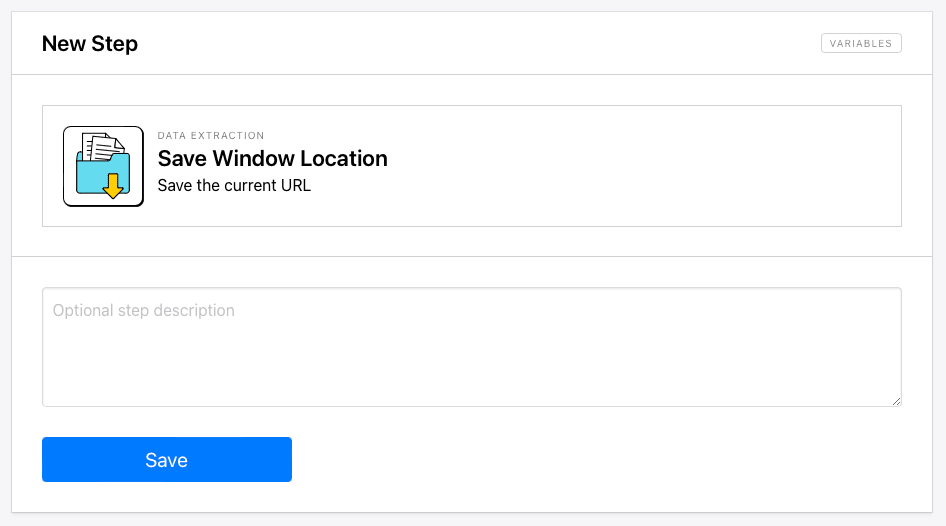
The link is saved in your output log, and it can then be stored in a database or used to initiate other workflows.
Bear Tip 🐻: To access the dynamic URL in later steps of your Roborabbit task, use a Go action combined with a variable URL.
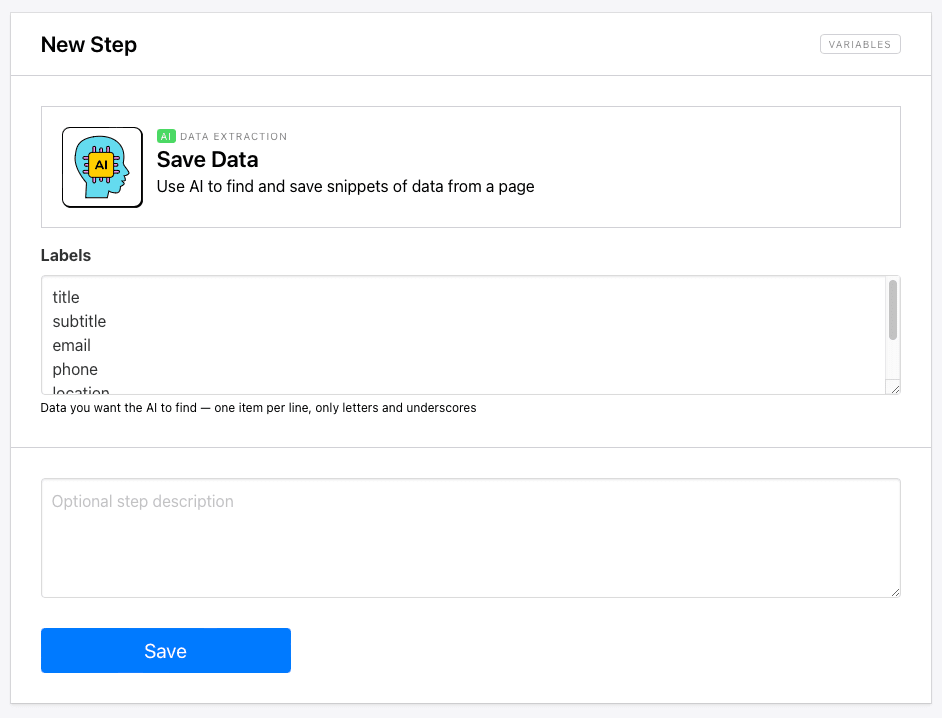
AI - Save Data
This variation of the Save Data action uses AI to locate and save snippets of data from webpages. While this may not be ideal for every scenario, it can save you a lot of time in many simple use cases and situations when page structure varies.
Setting it up involves inserting some instruction labels, which may only include letters and underscores.
Running the task should yield output that best matches your labels:

Keep in mind that AI is not completely accurate, and it may struggle to locate all the information you need, especially if it is located in a table or multiple containers.
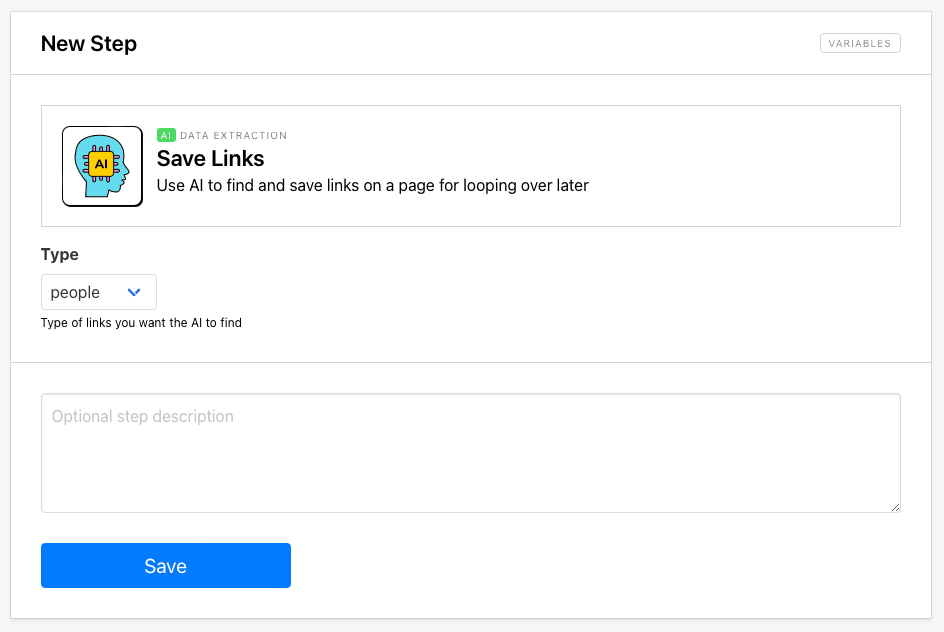
AI - Save Links
The AI-powered Save Links action stores URLs from a webpage, most often for looping through later on. This is helpful in cases where page structure varies.
To set it up, add the action to your task and specify the type of links you want the AI to find.
The scraper should return a list of links matching your description:
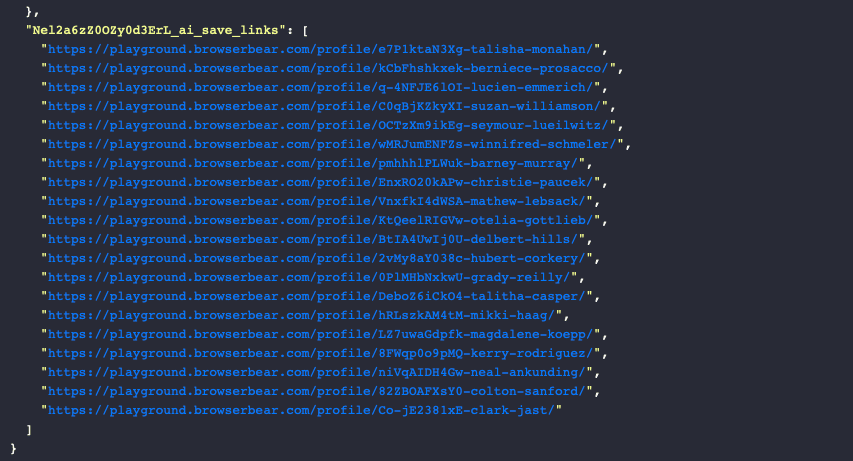
Following this up with a Save Data step will cause Roborabbit to loop through each link and extract the data you want to save.
Nocode Web Scraping Made Easier
Choosing a web scraping tool that can work with many types of data will open up the most possibilities in terms of websites and types of information you can extract. Roborabbit offers a versatile array of data extraction capabilities, empowering users to efficiently gather information with ease.
Whether your purpose is to collect mission-critical industry information or maintain an archive for documentation purposes, our nocode web scraping features make the extraction of data more accessible and streamlined than ever before.
