


Is Web Scraping Legal? 5 Best Practices for Ethical Web Scraping in 2025
Contents
In today's data-driven world, businesses, researchers, and developers rely heavily on web scraping to gather valuable insights, track market trends, and make informed decisions. However, as data privacy concerns grow, web scraping is increasingly scrutinized. A notable example is the LinkedIn vs. hiQ Labs case, where LinkedIn sued hiQ Labs for scraping public profiles, claiming it violated state and federal laws like the Computer Fraud and Abuse Act (CFAA) and Digital Millennium Copyright Act (DMCA). Although the courts ultimately ruled in favor of hiQ, the case highlighted the legal ambiguities surrounding the scraping of public data.
This brings up a crucial question: Is web scraping legal? The short answer is—it depends on how it’s done. By adhering to ethical best practices, you can avoid legal pitfalls while maximizing the benefits of web scraping. In this guide, we'll outline 5 best practices for ethical web scraping in 2025, to help you collect data responsibly and stay compliant with privacy regulations.
Is Web Scraping Legal?
Before diving into the best practices, let's address a common concern: Is web scraping legal? The legality of web scraping depends on both the methods used and the data being scraped. Generally, scraping publicly available information is legal, as long as you don’t violate a website’s Terms of Service or bypass any security measures.
However, scraping copyrighted content, personal data, or bypassing paywalls without permission can lead to legal issues, especially under laws like the Computer Fraud and Abuse Act (CFAA) in the U.S. or the General Data Protection Regulation (GDPR) in the EU. To stay compliant, make sure to follow these guidelines and the best practices outlined below, so you can scrape data from websites safely.
5 Best Practices for Ethical Web Scraping in 2025
1. Respect the Website’s Terms of Service
When scraping data from a website, one of the first and most important steps is to check and respect the website’s Terms of Service (ToS). These terms outline the acceptable ways users and automated tools can interact with the site, including restrictions on scraping, data extraction, and API usage. Websites may explicitly forbid scraping in their ToS, and ignoring these rules could result in your IP being banned, legal action, or even long-term damage to your reputation.
A website’s ToS can usually be found in the footer section. Look for links labeled "Terms of Service", "Terms and Conditions", or "Legal". When you click on one of these, it will take you to the full ToS, as shown below:
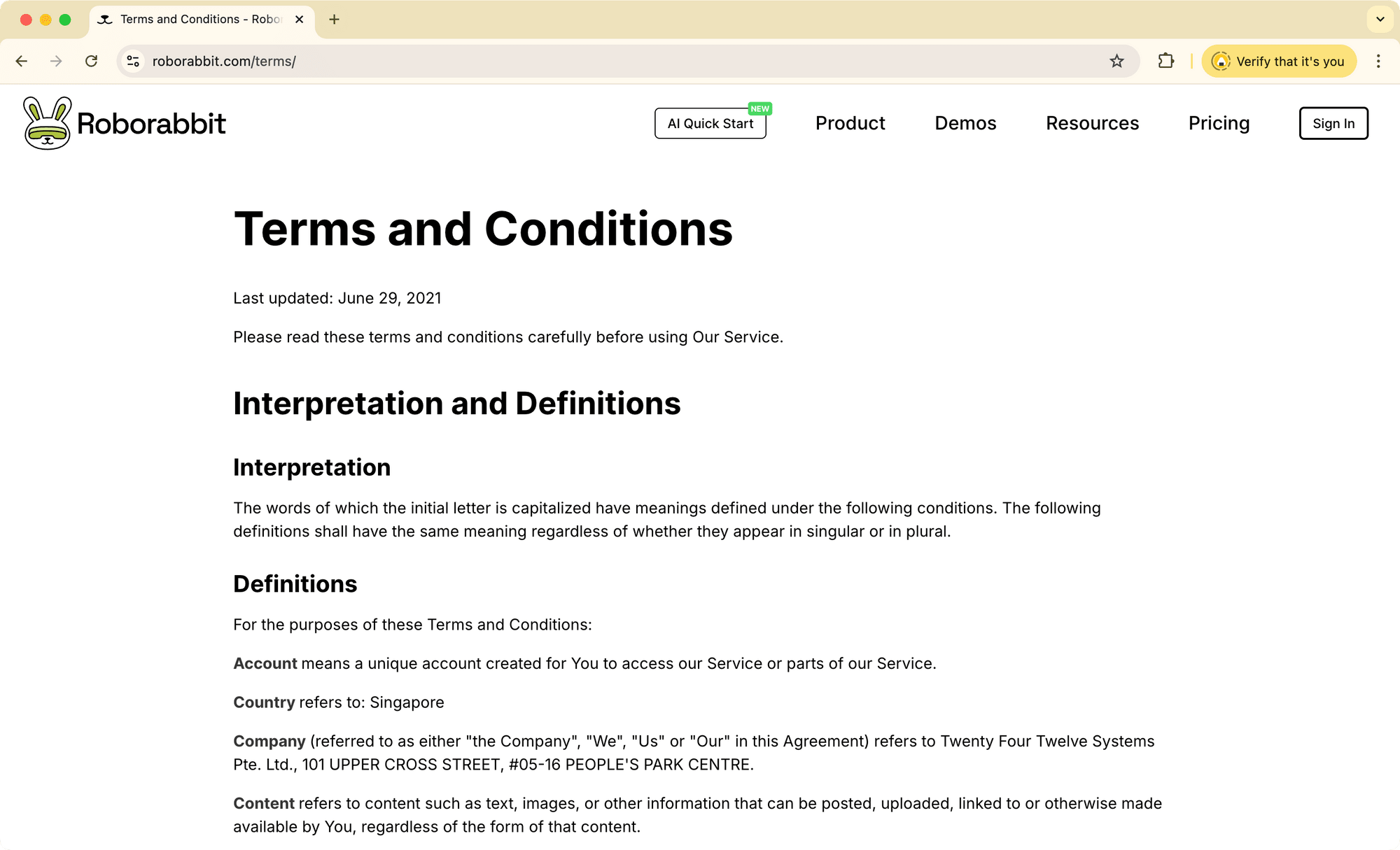
Why it matters: Ethical scraping involves respecting the website owner's rights and preferences regarding their data. Scraping without permission can result in legal issues and is generally considered unethical.
✅ What you should do: Always read the ToS carefully before scraping a website. Look for clauses that specify data usage, scraping, or automation. If scraping is prohibited, you can try reaching out to the website owner or operator for permission, or explore alternative ways to gather data, like using public APIs or open data sources.
2. Use Public APIs When Available
Many websites offer public APIs to allow users and developers to access their structured data in a safe and controlled manner. APIs are often the preferred way to gather data, as they are designed to allow automated data retrieval without overwhelming the site’s servers or violating terms. Using an API is not only more efficient, but it’s also much more ethical because it ensures you're accessing data that the website intends to share.
Here are some examples of popular websites that offer APIs for accessing data on their platforms:
Why it matters: Public APIs are a legal and efficient way to gather data, and they also help ensure that your scraping activities don’t harm the website’s performance or violate any laws.
✅ What you should do: Before building a scraping script, always check if the website provides an API. Many popular platforms, such as the ones mentioned above, provide APIs that give access to structured data, which eliminates the need to scrape the site directly. Keep in mind that APIs are typically rate-limited to prevent abuse, so ensure you're staying within these limits when accessing the data to prevent being blocked.
🐰 Hare Hint: Not all APIs provide the same level of access; some may still have restrictions on certain types of data. Make sure to check the API documentation to understand which data you can access.
3. Avoid Personal and Sensitive Data
Scraping sensitive data—such as health records, financial details, or other personal information—can result in serious legal consequences. Many countries and jurisdictions have strict laws governing the collection and use of sensitive data, and scraping such information can lead to significant fines, lawsuits, and even criminal charges.
Here’s a table outlining key laws related to user data privacy, including their main provisions and penalties, across different countries and regions:
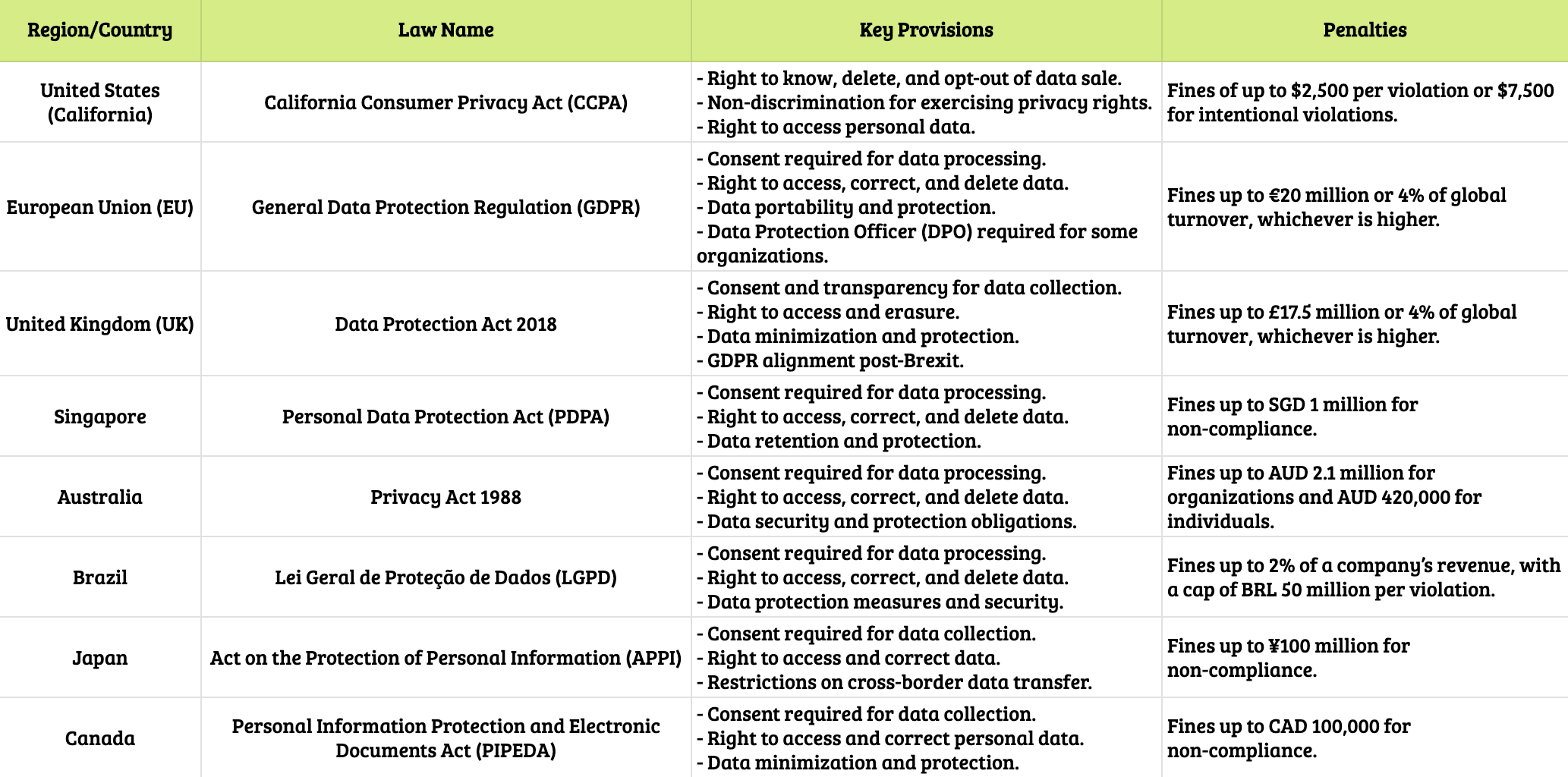
Why it matters: Sensitive data requires extra protection, and scraping it without consent or proper safeguards can lead to violations of privacy laws. Violating these laws can result in heavy penalties, including hefty fines and even imprisonment in some countries.
✅ What you should do: Focus on scraping publicly available, non-sensitive data that does not violate privacy laws. If the data involves sensitive details like people’s health or financial status, consider the legal risks carefully. Always prioritize ethical practices when selecting the type of data to scrape, and avoid any data that could compromise an individual’s privacy or security.
4. Prioritize Data Anonymization
When scraping data, particularly user-generated content, it's crucial to prioritize data anonymization. Many privacy laws, such as the General Data Protection Regulation (GDPR) in the EU, focus on protecting personally identifiable information (PII) including name, address, email, phone number, and more. Anonymizing the data ensures that this sensitive information is removed before it is stored, used, or shared, helping to safeguard user privacy.
Why it matters: Ethical scraping also involves respecting the privacy of individuals whose data you are collecting. It's important to handle personal information responsibly to comply with privacy laws and prevent any potential reputational damage.
✅ What you should do: When scraping data, collect only the information you truly need, and make sure to anonymize any personally identifiable information (PII). For example, if you're scraping reviews or social media posts, make sure to remove or mask details like usernames, locations, and contact information before using or storing the data for analysis.
Here are a few effective methods you can use to anonymize data:
- Replace personal names with random pseudonyms or anonymized codes (e.g.,
user1,user2, orID001). - Mask emails with generic formats like
[email protected]and phone numbers with placeholders such as(XXX)XXX-XXXX. - Generalize location data by using broad terms like "City_A" or masking specific coordinates with approximate locations.
- Use hashing algorithms (e.g., SHA-256) or encryption methods to anonymize sensitive data.
5. Respect Robots.txt and Crawl-Delay Directives
Most websites include a robots.txt file that provides instructions for web crawlers, indicating which pages or sections of the website are allowed to be crawled and which should be avoided. This file also often includes crawl-delay directives, which specify the ideal rate at which a crawler should make requests to avoid overloading the server. Even though this file is not legally binding, respecting it is an essential part of ethical scraping.
You can typically find a website’s robots.txt file by visiting its /robots.txt directory. Just enter the website’s root domain followed by /robots.txt. For example, to see Google's, go to https://www.google.com/robots.txt. In this file, look for directives such as User-agent, Disallow, Allow, and Crawl-delay to understand the site’s crawling guidelines.

Why it matters: Respecting robots.txt and crawl delay settings ensures that you aren’t unnecessarily burdening the website’s servers. It helps prevent your scraper from acting like a bot, which could slow down or disrupt the website’s normal functioning.
✅ What you should do: Before starting any scraping, always review the website’s robots.txt file. If the site has restrictions or crawl delays listed, configure your scraper to follow these rules. Also, be mindful of the website’s server load by adding proper intervals between your requests to avoid overwhelming the server.
Bonus: Tips for Ensuring Efficiency While Web Scraping Ethically
While ensuring the legality and ethics of web scraping is crucial, efficiency is equally important. Efficient scraping allows you to gather data faster, reduce server load, and lower the risk of being blocked. It also helps you optimize resources, making your scraping activities more scalable and sustainable.
Here are some tips to make sure your web scraping is efficient:
- Use headless browsers - Headless browsers like Puppeteer or Playwright help your scraping activities appear more human-like, reducing the likelihood of being flagged as a bot.
- Implement rate limiting and throttling - Rate limiting and throttling control the frequency of your requests, preventing the website’s server from being overwhelmed and lowering the chance of your scraper being blocked.
- Randomize your requests - Websites often detect bots by identifying repetitive patterns. To avoid this, randomize your headers, user agents, and request intervals to mimic human browsing behavior.
- Use targeted selectors - Use precise CSS or XPath selectors to extract only the data you need. This reduces parsing time and avoids irrelevant content.
🐰 Hare Hint: For more tips on web scraping efficiently, check out our full guide here.
Final Thoughts
Web scraping is a powerful tool for businesses, researchers, and developers to collect valuable data from the web, but it’s important to use it responsibly. Legal and ethical considerations should always be at the forefront to ensure that you don't violate a website's terms of service or infringe on user privacy.
By following these 5 best practices, you can minimize the risk of legal issues while scraping. Ultimately, responsible web scraping is not just about gathering data—it's about doing so in a way that respects others' work and contributes positively to society. Whether you're scraping for business insights, research, or other purposes, keeping these guidelines in mind will help you scrape safer.
