


How Web Scraping is Transforming the Market Research Industry
Contents
In today’s world, market research has become an integral part of decision-making for businesses across industries. Staying informed on upcoming trends and how they may affect your brand is essential. Businesses that make use of data they collect are able to use their resources efficiently and capitalize on opportunities for growth.
There’s no doubt that market research is invaluable. But with the vast amount of data available online, extracting and analyzing data can be time-consuming and labor intensive. You’re also constantly working against time as out-of-date data is not nearly as valuable.
Web scraping—the process of automatically capturing data from websites—is a game-changing tool that researchers now have at their disposal. Now, you can set up automations that gather the information you need with minimum intervention. This provides brands with valuable insights and transforms the way they make strategic decisions.
In this article, we will explore the transformative power of web scraping in market research and delve into the various ways it is reshaping the industry.
How Web Scraping Works
Web scrapers access the data on a website by parsing the HTML and navigating the elements on the page. They target and extract data from elements using XPath, CSS selectors, or regular expressions. Output is typically stored in a structured format, such as a CSV file or JSON array.
Most tools—like Browserbear—will give you additional browser control features that allow you to scrape multiple pages, extract specific types of information, take screenshots, and more. Nocode-friendly apps will also come with selectors that make it possible to do all of this without being able to code.
Bear Tip 🐻: To learn how to use Browserbear for your web scraping needs, refer to our Part 1 and Part 2 tutorials.
The Advantages of Web Scraping in Market Research
Web scraping is presented as a solution to many issues market researchers face in their work. It relieves several pain points of manual data collection, including:
- Inefficiency of collection
- Human error
- Limited scale of reach
- Time sensitivity for decision-making
Automating the data collection process addresses all of these challenges, providing accurate and comprehensive data in real time with a reduced chance of human error.
Let’s break down the key advantages of automatic data extraction in a little more detail:
1 - Increased Efficiency
Manual data collection is an exhausting process, and it takes significantly longer than automation. Even if the sources for collection have already been established, the process of retrieving the data and organizing it as needed can seem endless.
The web scraping software industry is growing, and a big part of that is due to the time and cost savings associated with automation. When researchers no longer have to perform tasks like manual data entry, formatting, and compilation, their abilities can go towards analyzing and interpreting the information. Teams can also create accurate reports in a fraction of the time, which increases decision-making agility.
2 - Access to Real-time Data
A major disadvantage of manual and internal data is that by the time everything is compiled into a report, the information is already out-of-date. While there are absolutely circumstances where historical data is preferred, you’ll find real-time data to be useful as well.
Automatic data extraction gives researchers access to real-time data, which they can use to provide decision makers with an accurate look at the current market and how trends are actively shifting. You can use browser automation tools to retrieve data and give you updates periodically. Take it a step further by integrating with other apps to create reports, take actions based on data, send automatic updates to teams, and more.
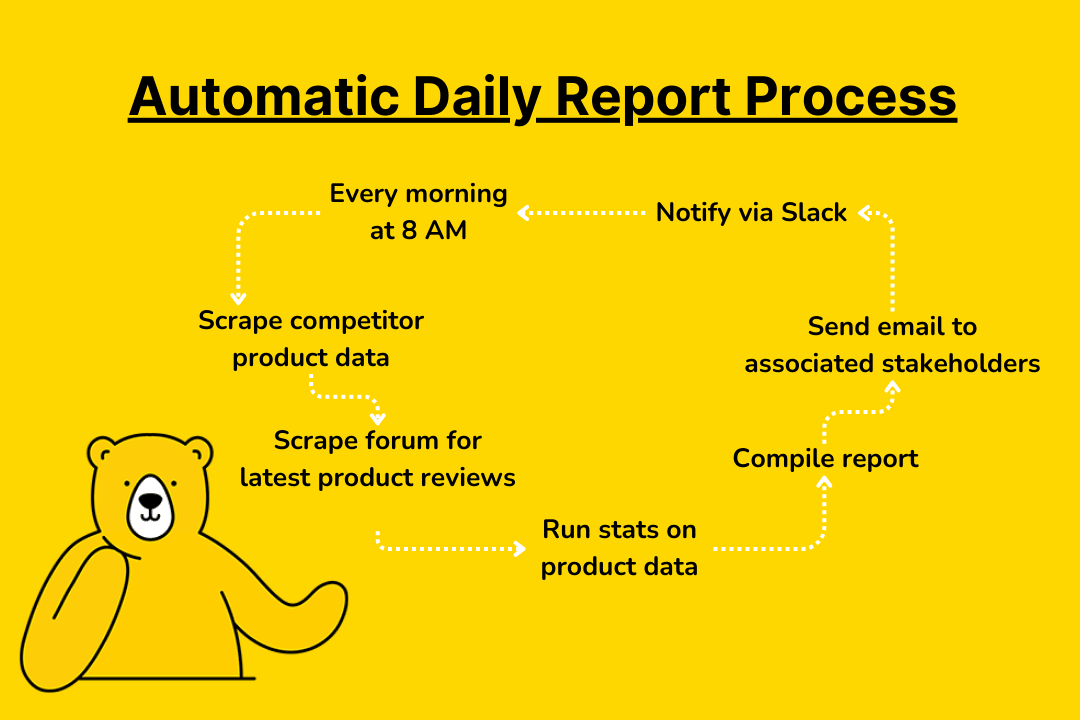
Bear Tip 🐻: A great way to ensure you always have real-time data is to schedule frequent web scraping tasks. Different situations may call for either time-based or trigger-based automation. You can do this with the scraping tool of your choice or through a third-party workflow automation tool like Zapier.
3 - Broader Reach
The time-consuming nature of traditional market research means it’s tricky to capture comprehensive and representative data. This can hinder the accuracy of insights drawn and decisions made. Automation allows you to expand your reach, collecting a larger quantity of data from a variety of sources.
Automated data collection scales very easily as many tasks can be carried out concurrently. You can gather data from 10+ sites at the same time, sending it to the same database so the information can be viewed and used for analysis.
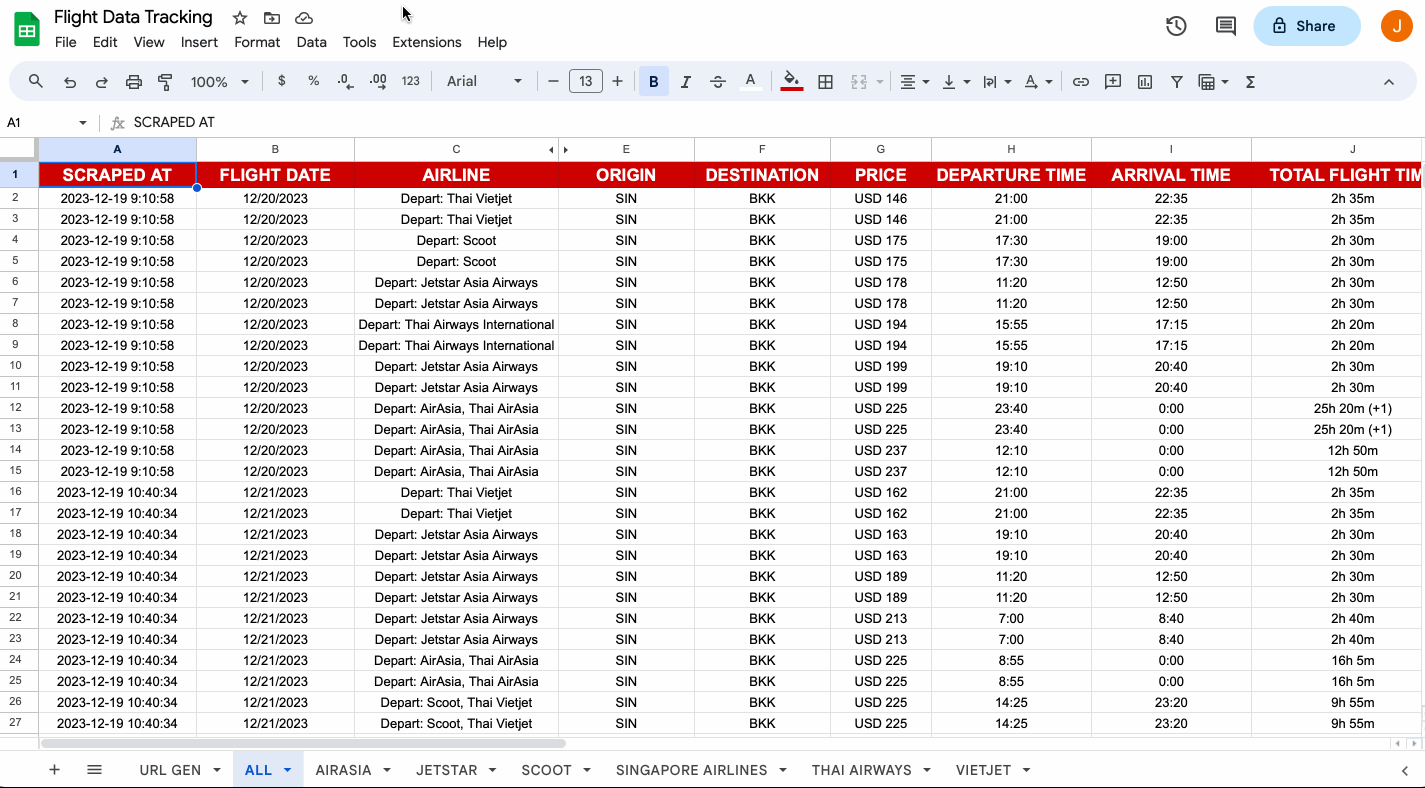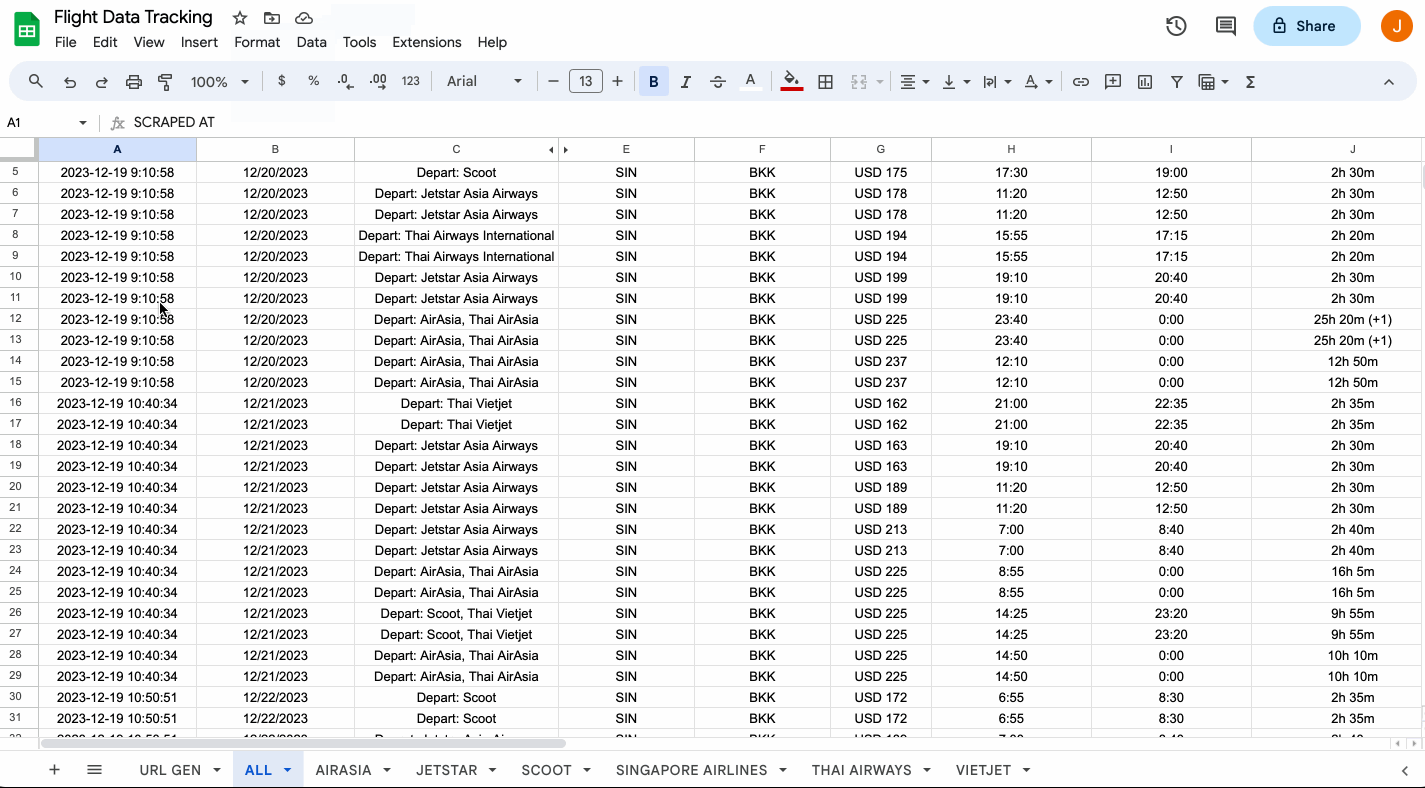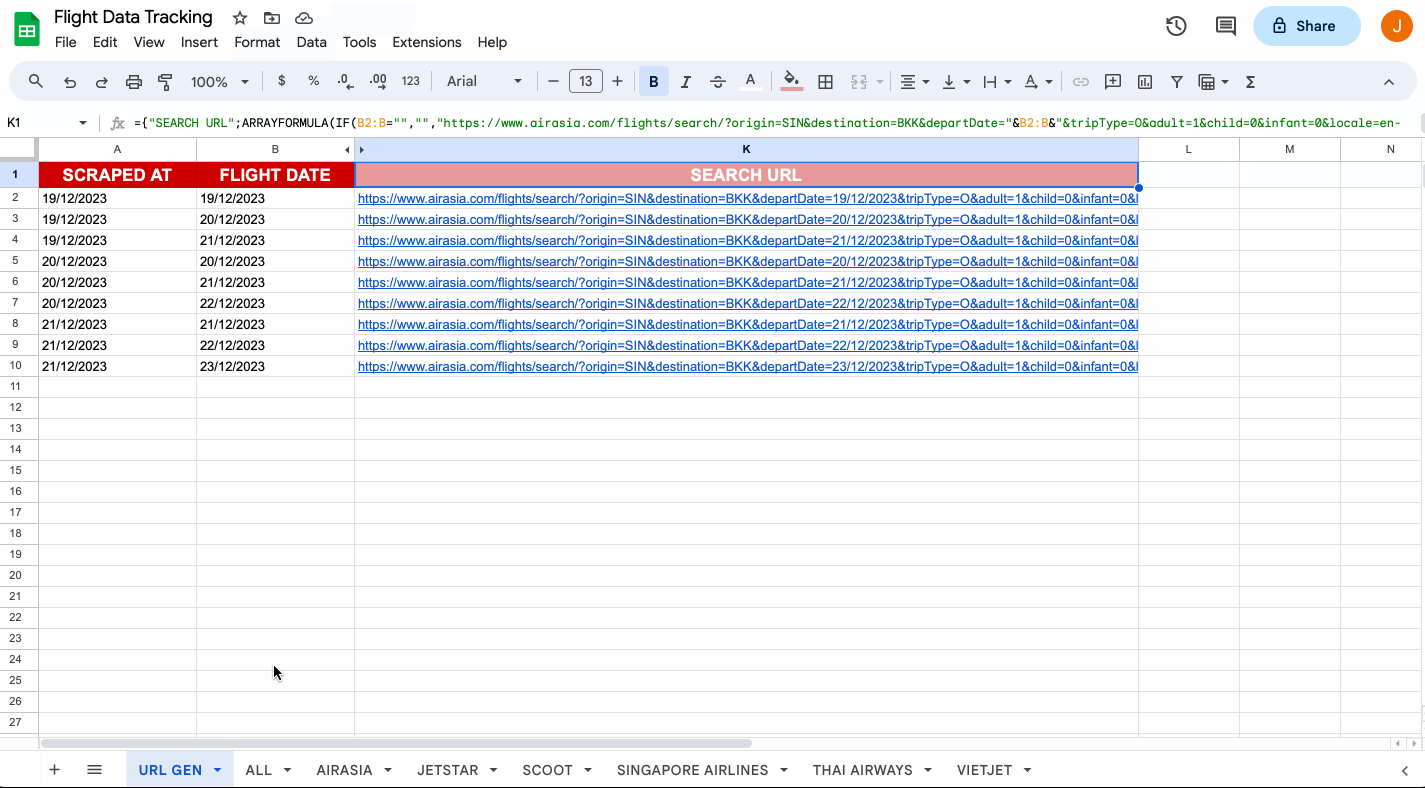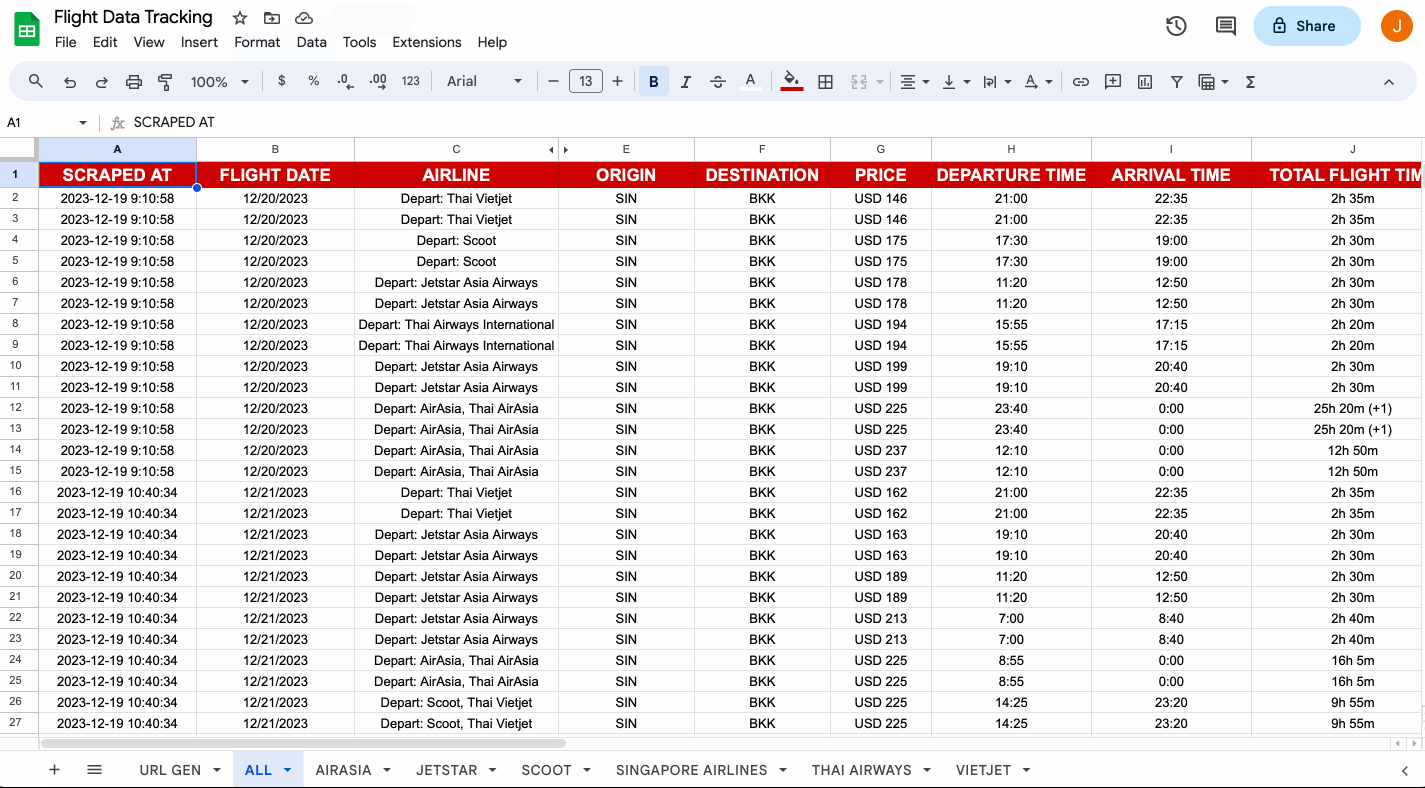
4 - Structured Formatting
Most web scraping tools collect data in a structured format, such as JSON, CSV, or XML. This allows for easier data organization, analysis, and transferability. Having your information in a structured format eliminates the need for manual data cleaning and formatting, saving time and reducing the chances of error.
With structured data, researchers can easily import the scraped information into databases, spreadsheets, or analysis tools for further evaluation. If you have an automated process that involves moving the data across apps, proper formatting enables efficient data management and integration with other systems or software.
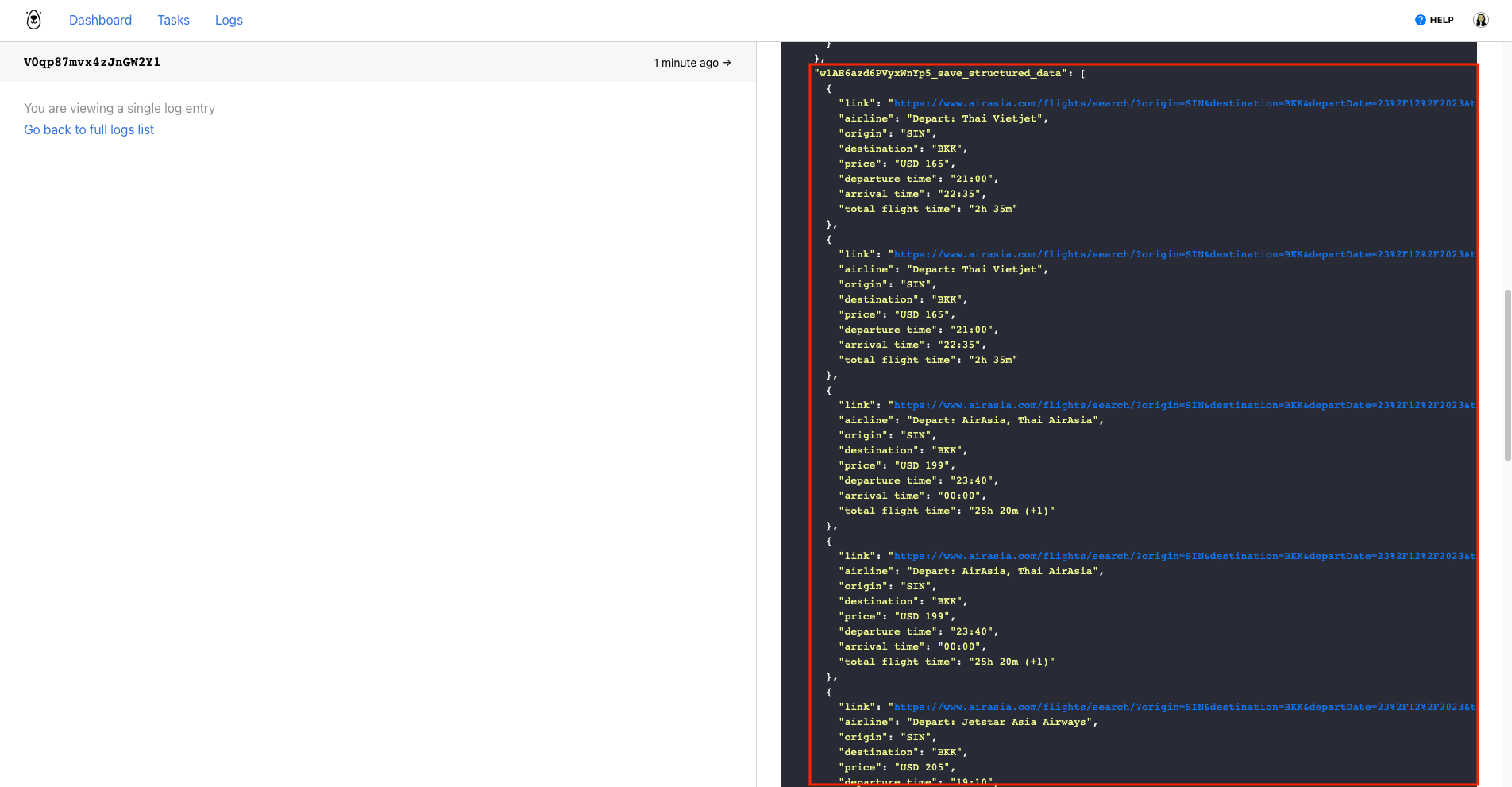
Overall, structured data obtained through automated web scraping streamlines the research process and enhances the accuracy and usability of the collected information.
Bear Tip 🐻 : Browserbear supplies output data in a JSON array, making it simple to transfer to databases and spreadsheets of all sorts. You can also use the Custom Feeds feature to scrub data and customize it to your needs. This saves you time that would otherwise be spent manually formatting your data for analysis.
How Businesses Use Web Scraping for Market Research
Information is power in today’s data-driven business environment. Having access to timely and accurate market information can mean the differences between being the industry leader and being left behind.
Researchers can gather many types of information to develop valuable business insights. A wide range of analyses can be performed on data collected, with a few of the most common being:
1 - Industry Analysis
Keeping a close watch on larger industry trends and shifts can help you make better strategic decisions. Researchers may collect analysis data from news sites, industry reports, industry leader sites, and more.
2 - Market Analysis
You should also know what to expect from the immediate market your brand operates in. Analysis data can be collected from local industry blogs, competitor sites, and search engines.
3 - Competitor Analysis
A firm grasp of the competitive landscape ensures you have an edge in terms of positioning, marketing campaigns, and more. Product prices, features, descriptions, and demand are all valuable information researchers might want to gather from competitor websites and search engines.
4 - Consumer Analysis
Brands need to know consumer sentiments to stay ahead of the trends and know how to position their products for their market. Data can be taken from social media, forums, user reviews, and search engines.
Web scraping empowers market researchers to gather relevant insights from online sources efficiently. Here are some specific examples of how different industries might use data extraction tools:
- Tech & Software: Information such as customer reviews, feedback, feature requests, and more can be collected from review sites, social media, news sites, and industry leaders. These provide insights into product performance and user experience, helping teams improve their products and position them better.
- Marketing: Data used by marketing firms is often gathered from social media, blogs, news websites, competitor websites, and review sites. This helps them and their clients to understand consumer behavior, market trends, and competitor strategies.
- Banking: Financial data can be collected from investment platforms, financial news websites, and market forecast sites. This helps them perform risk assessments and provide investment strategies that their customers might be interested in.
- E-commerce: Brands selling consumer products online can scrape competitor websites, online marketplaces, and social media. Product data and customer sentiments help them optimize their offerings.
- B2B: Information for B2B companies can be extracted from industry directories, trade publications, and company websites. This helps identify potential leads, monitor industry trends, and adjust pricing in response to demand.
- Entertainment: Data for entertainment brands can be extracted from social media, streaming platforms, and forums. This helps them understand content popularity and aids in targeting the best audience.
- Hospitality: Hospitality businesses can collect data from booking platforms, review platforms, and forums. This gives insights into consumer preferences, seasonality, and pricing trends.
The range of market research data you can collect with web scrapers is near endless, and the best part is that you can customize it to your needs. Brands of different sizes with different competitors and markets will require a different approach, and it’s the market researcher’s job to decide on the data needed for strategic decision-making.
Reducing the Manual Work in Research
Automated tools like web scrapers aren’t there to make market research redundant—rather, they reduce the manual work so professionals can focus on turning raw data into actionable insights. And since automation scales so well, an individual or small team of researchers can handle a fairly large data collection task.
Browserbear can help you transform your market research processes by automating the data extraction process. To learn more about what you can do with our product, check out a few of these articles:
👉 How to Scrape Your Latest TripAdvisor Reviews (+ Autogenerate Images!)
👉 A Nocoder’s Guide to Formatting Scraped Data in Browser Automation
