


How to Use cURL in Python (with Examples)
Contents
cURL (Client for URLs), a versatile command line tool for data transfer, is a powerful asset in a developer's toolkit. It is platform-independent and can be used on various operating systems including Windows, macOS, Unix/Linux, IBM i, and Android to send and receive data over protocols like HTTP, FTP, SCP, IMAP, and more. You can use it to fetch web pages, download files, upload data, interact with APIs, and perform other operations that involve data exchange between a client and a server.
While cURL can be executed directly in the terminal or command prompt of nearly any operating system, there are situations where running a cURL command within Python code becomes advantageous. For example, it allows integration with an existing Python code base, leveraging enhanced Python functionalities, and working with other Python libraries.
In this article, we will explore how to use cURL in Python, particularly using it to make HTTP requests, and provide examples that showcase its features and practical applications.
What is cURL
cURL is a free and open-source command line tool and library for transferring data with URLs. Other than the operating systems mentioned previously, it can also be used on devices like routers, printers, audio equipment, mobile phones, tablets, and media players.
All transfer-related features of cURL are powered by libcurl, a free and easy-to-use client-side URL transfer library. It builds and works similarly on different platforms and operating systems. To use it on your machine, run the curl command in the terminal or command prompt followed by the desired options and arguments.
curl [options / URLs]
Here’s a screenshot using cURL in the terminal to fetch a web page:
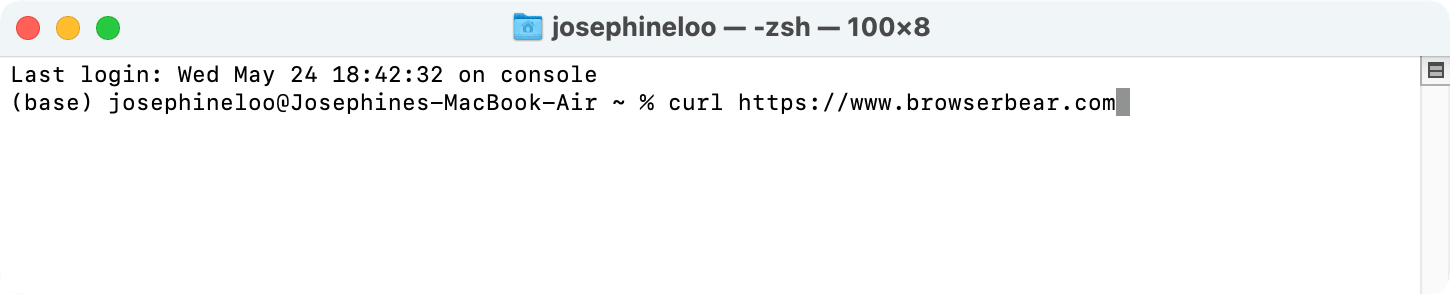
The command in the screenshot above will send a GET request to the specified URL and displays the response in the terminal. The received data will be written to stdout by default but you can also save them into a local file, using the -o, –output or -O, –remote-name options.
Sending HTTP Requests in Python: PycURL vs Requests
Making HTTP requests in Python requires a library. You can use PycURL, a wrapper around the cURL library, or Requests, a third-party library that simplifies HTTP request making and provides a high-level API for interacting with web services in Python.
The Requests library is widely used due to its simplicity. However, it can be slow. When multiple requests are performed and connections are reused, the speed of PycURL wins over Requests significantly (2-3x). Besides that, PycURL also offers many other features, like:
- Support protocols like DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet, and TFTP (Requests support HTTP only)
- I/O multiplexing
- The ability to use several TLS backends
- More authentication options
Both libraries come in handy when you need to make HTTP requests in Python. The Requests library is often preferred because it provides a simple API but if you need to send data over other networks too or utilize more advanced features, PycURL is a better choice.
Pre-requisites
To use cURL in Python/PycURL on your machine, you need to have these installed:
Using cURL in Python to Send HTTP Requests
PycURL is a Python wrapper around the cURL library. To use cURL in Python, install the PycURL package by running the command below in your terminal/command prompt:
pip install pycurl
After installing the package, we can import and use it in our Python code.
Next, we will see how to make HTTP requests using the PycURL library. To show the comparison between using PycURL and Requests to make HTTP requests, we will also use some examples from Web Scraping with Python: An Introduction and Tutorial, which the Requests library is used.
POST
The code below shows a simple example of making a POST request in Python using PycURL:
import pycurl
from urllib.parse import urlencode
# Create a Curl object
curl = pycurl.Curl()
# Set the URL
curl.setopt(pycurl.URL, 'https://www.example.com/submit')
# Set request type to POST
curl.setopt(pycurl.POST, 1)
# Set request data
data = {'key': 'value'}
curl.setopt(pycurl.POSTFIELDS, urlencode(data))
# Perform the request
curl.perform()
# Get response code
response_code = curl.getinfo(pycurl.RESPONSE_CODE)
print(f"Response Code: {response_code}")
# Close the Curl object
curl.close()
The data must be URL-encoded beforehand. If you’re not sending any data in the request body, set the POSTFIELDSIZE to 0 to indicate there’s no request body. Otherwise, the request cannot be made.
curl.setopt(pycurl.POSTFIELDSIZE, 0)
In some cases, you might need to add headers and data to your request, like making a POST request to Browserbear's API to trigger an automation task, which requires authentication:
import pycurl
from urllib.parse import urlencode
api_key = "your_api_key"
task_id = "your_task_id"
run_id = "your_run_id"
# Create a Curl object
curl = pycurl.Curl()
# Set the URL
curl.setopt(curl.URL, f"https://api.browserbear.com/v1/tasks/{task_id}/runs")
# Set the header
curl.setopt(curl.HTTPHEADER, ["User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
f"Authorization: Bearer {api_key}"])
# Set request type to POST
curl.setopt(pycurl.POST, 1)
# Set request data
data = {
'webhook_url': 'https://webhook.site/bf8ed79b-0d35-4734-883b-3b0ea909e6d8',
}
curl.setopt(pycurl.POSTFIELDS, urlencode(data))
# Perform the request
curl.perform()
# Get response code
response_code = curl.getinfo(pycurl.RESPONSE_CODE)
print(f"Response Code: {response_code}")
# Close the Curl object
curl.close()
Note: If you receive error code: 1010% in the response, try adding user agent to your header like the example above.
🐻 Bear Tip: You can compare the code above with the request made in Web Scraping with Python: An Introduction and Tutorial.
GET
For a GET request, the code is simpler. You don’t have to set the request type explicitly like POST:
import pycurl
# Create a Curl object
curl = pycurl.Curl()
# Set the URL to send the GET request
curl.setopt(curl.URL, 'https://www.example.com/endpoint')
# Perform the request
curl.perform()
# Retrieve the response
response = curl.getinfo(pycurl.RESPONSE_CODE)
print(response)
# Close the Curl object
curl.close()
Similarly, you can use it to make a GET request for Step 3 in Web Scraping with Python: An Introduction and Tutorial instead of using the Requests library:
import pycurl
api_key = "your_api_key"
task_id = "your_task_id"
run_id = "your_run_id"
# Create a Curl object
curl = pycurl.Curl()
# Set the URL
curl.setopt(curl.URL, f"https://api.browserbear.com/v1/tasks/{task_id}/runs/{run_id}") #initializing the request URL
# Set the header
curl.setopt(curl.HTTPHEADER, ["User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
f"Authorization: Bearer {api_key}"])
# Perform the request
curl.perform()
# Get response code
response_code = curl.getinfo(pycurl.RESPONSE_CODE)
print(f"Response Code: {response_code}")
# Close the Curl object
curl.close()
🐻 Bear Tip : If you're hitting errors, you can debug using
curl.setopt(c.VERBOSE, True).
The examples above show you how to make simple HTTP requests using PycURL without other advanced configurations. However, sometimes, you might need to configure PycURL or perform additional operations to suit project requirements, like:
Utilizing a Certificate Bundle
Most websites nowadays use HTTPS, which uses TLS (SSL) to encrypt normal HTTP requests and responses, and digitally sign those requests and responses. In this case, PycURL needs to utilize a certificate bundle.
Some operating systems supply the certificate bundle. Otherwise, you can install and use the certifi Python package:
import certifi
curl.setopt(curl.CAINFO, certifi.where())
Downloading/Writing Data to a File
PycURL does not provide storage for the network responses but you can write them to a file using the WRITEDATA function. The response body can be written bytewise without decoding or encoding, as long as the file is opened in binary mode. You can do so by indicating wb in the open() function:
import pycurl
with open('output.html', 'wb') as f:
curl = pycurl.Curl()
curl.setopt(curl.URL, 'https://www.browserbear.com/')
curl.setopt(curl.WRITEDATA, f)
curl.perform()
curl.close()
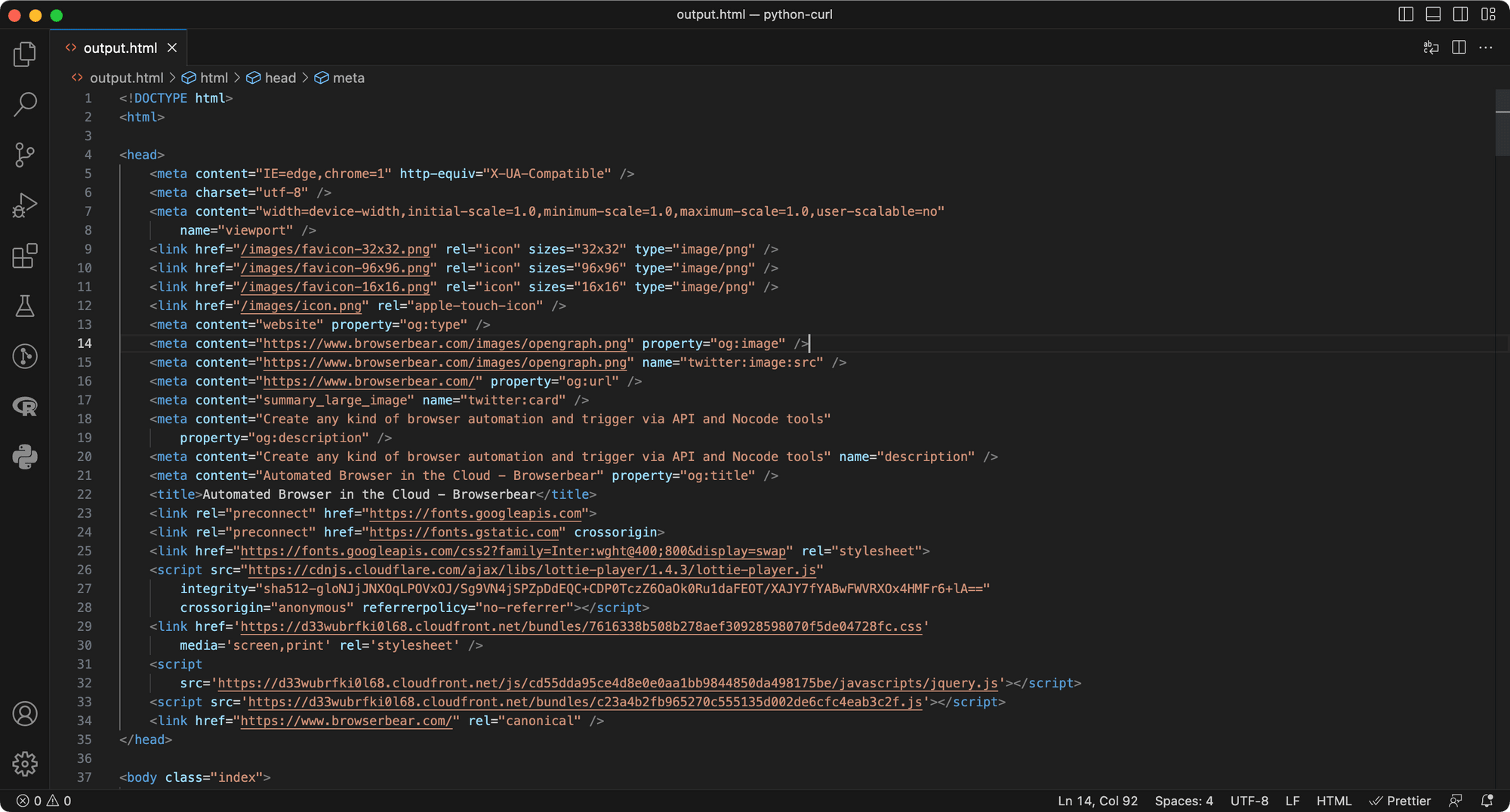
The response is saved in a file named ouptut.html:
Uploading Files
The HTTPPOST option can be used to upload a file, which replicates the file upload behaviors in an HTML form. You can upload data from a physical file using the code below:
import pycurl
curl = pycurl.Curl()
curl.setopt(curl.URL, 'https://www.example.com/upload')
curl.setopt(curl.HTTPPOST, [
('fileupload', (
# upload the contents of this file
curl.FORM_FILE, __file__ ,
)),
])
curl.perform()
curl.close()
If the data is in memory, instead of using curl.FORM_FILE, use curl.FORM_BUFFER:
importpycurlc = pycurl.Curl()
curl.setopt(c.URL, 'https://www.example.com/upload')
curl.setopt(curl.HTTPPOST, [
('fileupload', (
curl.FORM_BUFFER, 'output.txt',
curl.FORM_BUFFERPTR, 'The data is in memory',
)),
])
curl.perform()
curl.close()
For other operations like examining response headers, following redirects, and examining responses, refer to the PycURL documentation.
Conclusion
cURL is a valuable tool for data transfer and offers a wide range of capabilities. Whether you prefer running cURL commands directly in the terminal/command prompt or integrating them into your Python code, the choice ultimately depends on your specific requirements.
Throughout this article, we have explored how to use cURL in Python, with a focus on making HTTP requests. By incorporating cURL into your Python projects, you can unlock a multitude of benefits. So, don't hesitate to harness the power of cURL in Python and enhance your ability to handle data transfer tasks with ease!
