


How to Use a Proxy in cURL
Contents
Short for “Client URL”, cURL is a powerful command-line tool commonly available on most systems, including Linux/Unix, macOS, and Windows for transferring data. Its versatility and ease of use make it a popular choice for developers and system administrators to perform tasks like testing APIs, downloading files, and automating web interactions.
Using cURL with a proxy can be beneficial in various scenarios, such as bypassing geo-restrictions, enhancing privacy, and web scraping. In this article, we'll explore what cURL is, why you might want to use it with a proxy, and how to configure it to use a proxy effectively.
What is cURL
cURL, which stands for "Client URL", is a command-line tool used to make HTTP requests and transfer data to or from a server using URLs. It supports various protocols such as HTTP, FTP, and SMTP. Similar to making a typical HTTP request, you can include cookies, data, authentication credentials, and other headers in your cURL command.
Here's an example of a simple cURL command:
curl https://www.roborabbit.com/
The cURL command above sends a GET request to the URL. It retrieves the content of the webpage and displays it in the terminal. Essentially, it's fetching the HTML of the page:
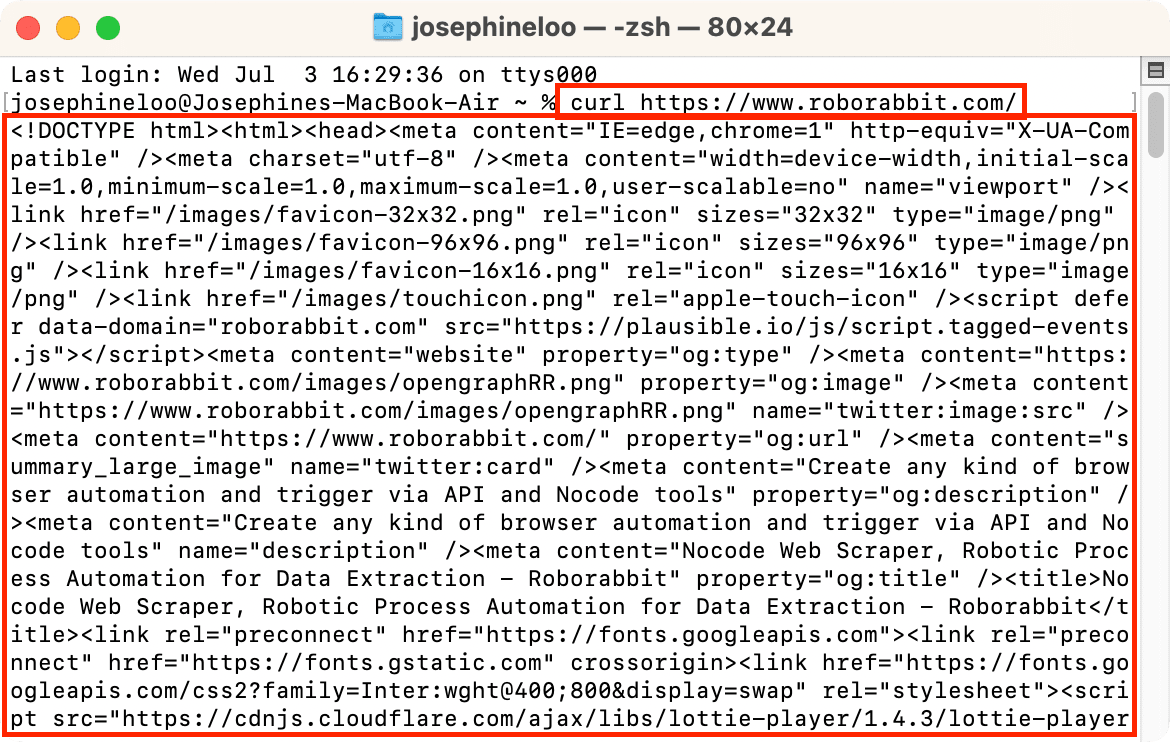
cURL is pre-installed on many systems, making it an ideal tool when you need a lightweight solution that doesn’t require additional software installation. Moreover, it works consistently across various operating systems, including Linux, macOS, and Windows.
Why Use a Proxy
Before we get into how to use cURL with a proxy, let's understand the benefits of using a proxy. A proxy serves as an intermediary between your device and the internet—your internet requests are directed through a proxy server, which then communicates with the website on your behalf.
Using a proxy can be beneficial in several scenarios, such as:
- Hiding your IP address to protect your identity and location
- Enhancing security
- Accessing geo-restricted content
- Distributing requests across multiple proxies to avoid rate limits
For example, websites often impose rate limits to prevent abusive behaviors like spamming or scraping. They do this by limiting the number of requests a single user or IP address can make within a certain time frame. By using a proxy, you can distribute requests across different IP addresses, appearing as multiple users rather than a single source. However, it's crucial to use proxies ethically and in accordance with the website's terms of service.
🐰 Hare Hint: Depending on your requirements, company policies, or privacy preferences, a proxy can offer different levels of functionality, security, and privacy.
How to Use a Proxy in cURL
To use a proxy in cURL, you'll need to provide the necessary information about the proxy server. Here's how you can do it:
Step 1. Determine the Proxy Server Details
Before you can use a proxy in cURL, you'll need to know the following information about your proxy server:
- Proxy address/hostname (e.g.,
proxy.example.com) - Proxy port (e.g.,
8080) - Proxy username and password, if required
Step 2. Set the Proxy Options in cURL
Once you have the proxy server details, you can use the following cURL options to configure the proxy settings when making an HTTP request to a URL:
Specifying the Proxy Server
You can use the -x or --proxy option to specify the proxy server:
curl -x <protocol>://<proxy_host>:<proxy_port> <url>
curl --proxy <protocol>://<proxy_host>:<proxy_port> <url>
Replace <protocol> with the proxy protocol (http, https, socks4, socks4a, socks5, etc.), <proxy_host> with your proxy server's IP address or domain name, <proxy_port> with your proxy server's port number, and <url> with the website URL.
Providing Authentication Credentials
If authentication is required, you can use the -U or --proxy-user option to specify the username and password:
curl -U <user:password> --proxy <protocol>://<proxy_host>:<proxy_port> <url>
curl --proxy-user <user:password> --proxy <protocol>://<proxy_host>:<proxy_port> <url>
Alternatively, you can use the command below:
curl --proxy <protocol>://<username>:<password>@<proxy_host>:<proxy_port> <url>
🐰 Hare Hint: Run
curl --help proxyto check all options related to proxies.
Step 3: Verify the Proxy Connection
To ensure everything is set up correctly, test the proxy connection with a simple request to a known website. If the request is successful, that means the proxy is working as expected!

Note: Each cURL command is independent. You need to specify the proxy details whenever you want to make an HTTP request through the proxy.
Configuring The Proxy in the ‘.curlrc’ File
To avoid specifying the proxy details every time you make an HTTP request with curl, you can set up a default proxy in your cURL configuration file (~/.curlrc). Here’s how you can do it:
Open or create the ~/.curlrc file in your home directory:
nano ~/.curlrc
Then, add the following line with your proxy details to ~/.curlrc:
proxy = <protocol>://<proxy_host>:<proxy_port>
Save the changes and exit the text editor. Now, each cURL command will automatically use the proxy settings defined in ~/.curlrc.
Using cURL for Web Scraping
cURL is a handy tool for web scraping when you need to quickly fetch web page content without installing extra software. It also integrates seamlessly into scripts for automated tasks and scheduled scraping jobs. However, for more complex scraping needs, you may need to combine cURL with tools like grep, awk, or sed to filter and process data, which makes the process more complicated.
An alternative to cURL for web scraping without additional software installations is Roborabbit. Roborabbit is a scalable, cloud-based tool that comes with built-in proxies featuring IPs from various countries. It also supports custom proxies, and all proxy values are securely encrypted.

Roborabbit is incredibly easy to set up and use. With its Chrome extension, you can easily identify your target HTML and add the necessary steps to your task in Roborabbit to scrape data from the website.
Here’s an example of a Roborabbit task for web scraping:
To get a practical feel, sign up for Roborabbit and duplicate the task above to your account. You can customize the task by adding additional actions and steps as needed. Whether you prefer using cURL for quick tasks or opting for a more comprehensive tool like Roborabbit, I hope you found this article useful!
🐰 Hare Hint: You can also use Roborabbit's REST API to execute tasks in the cloud and retrieve data once the tasks are completed.
