


How to Scrape Lists with Browserbear (A No Code Guide)
Contents
Web scraping most often involves extracting data from various elements on a webpage, with each one being a separate field that can be deposited in a database. But in some cases, it’s useful to group similar items together in a field, such as in the case of a list.
Lists can be ordered, unordered, or description-based, and may contain nested lists. You might find them commonly used for things such as:
- Batched items
- Product descriptions
- Recipe ingredients
Since the number of list items can vary across different pages, it’s more practical to scrape the entire list as a single item rather than per-line.


There are several methods to extract lists from webpages, but using a nocode web scraping tool like Browserbear can make the process much simpler. This article will guide you through setting up a list scraping task in Browserbear and provide tips for creating similar workflows on your own.
❗ Note : Not all lists are as they seem. Table of contents, for example, might look nested on the frontend but not be a true list. Rather, they are just styled to look like one using CSS or a CMS (content management system). Keep in mind that these might present different results when scraped.
How to Set up a List Scraping Task on Browserbear
When scraping lists, it’s important to set tools up in a way that accurately selects all the data and maintains formatting when pulled into a database. We will use Browserbear to create a task that can be triggered by an event or on a schedule.
Log into your Browserbear account (or create a free trial account if you don’t have one — no credit card required! 🎉). Click the Tasks tab, then the Create a Task button.
Give your task a name, then Save.
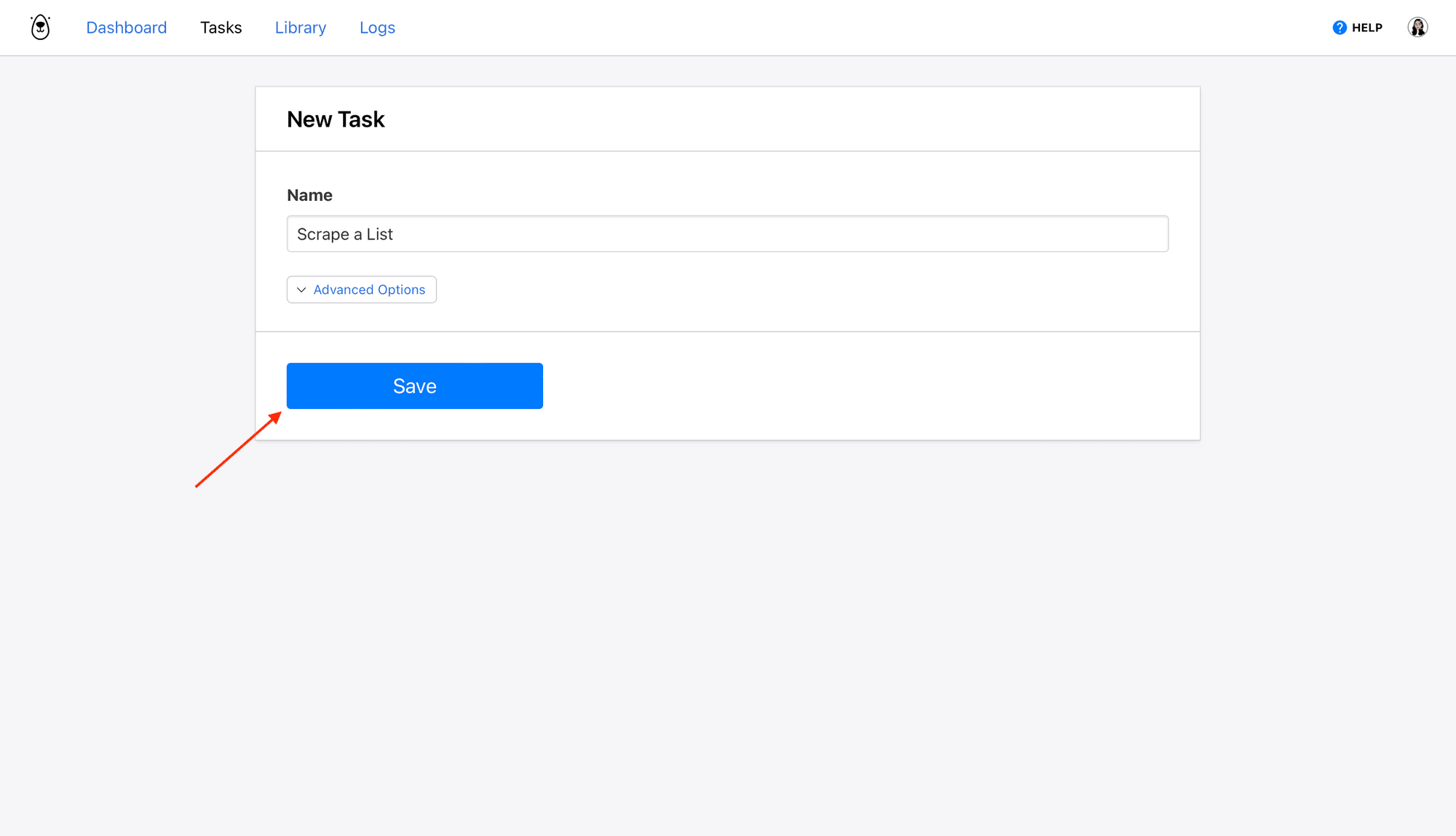
You will now be on a page where you can add steps, integrate with other apps, run your task, and review completed runs.
Let’s create a simple task to scrape a list of ingredients from a recipe site. Click Add Step and set up the following actions:
Step 1. Go
Select go as the Action, insert your destination website URL, and choose domcontentloaded as the wait instructions.
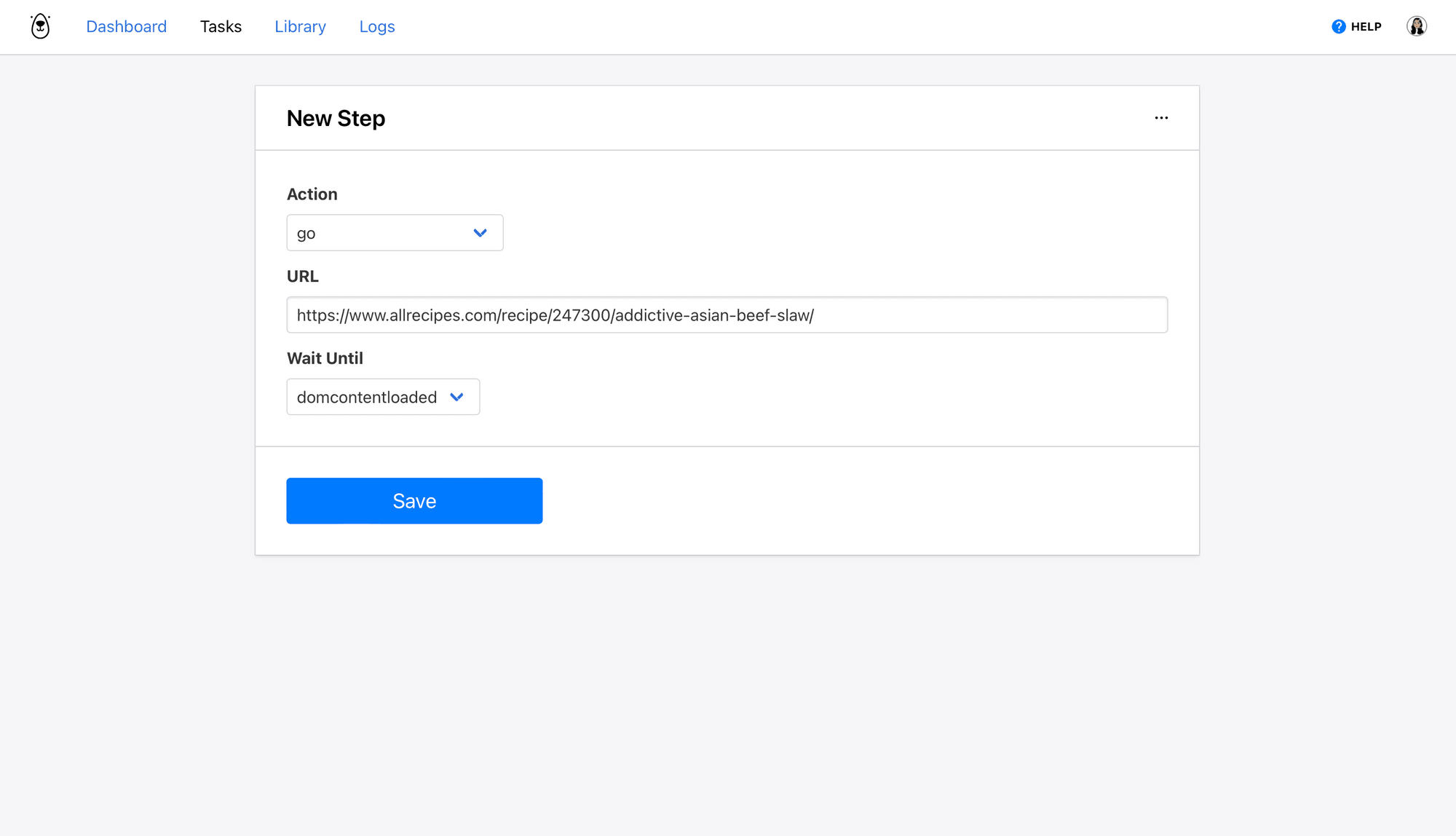
Click Save.
Bear Tip 🐻: We will use domcontentloaded as the load instructions in this situation because we are only scraping text. Other options include networkidle and load, with the former being the safest in the majority of situations.
Step 2. Save Structured Data
This step will define a parent container and the child elements you want to scrape within it. We will only set up an action for one container. It will then apply to all others on the page containing the same elements.
You can also use Zapier to override the task’s initial destination URL and send it to another page with the same elements, which is what was done in this example.
Bear Tip 🐻: We are using the save_structured_data action to save multiple items in a structured format, but the save_text action will also work if you’re only looking to scrape the list.
Select save_structured_data as the Action.
You will need to use the Browserbear Helper Chrome extension to retrieve the helper configs. Activate the extension on the fully loaded destination site.
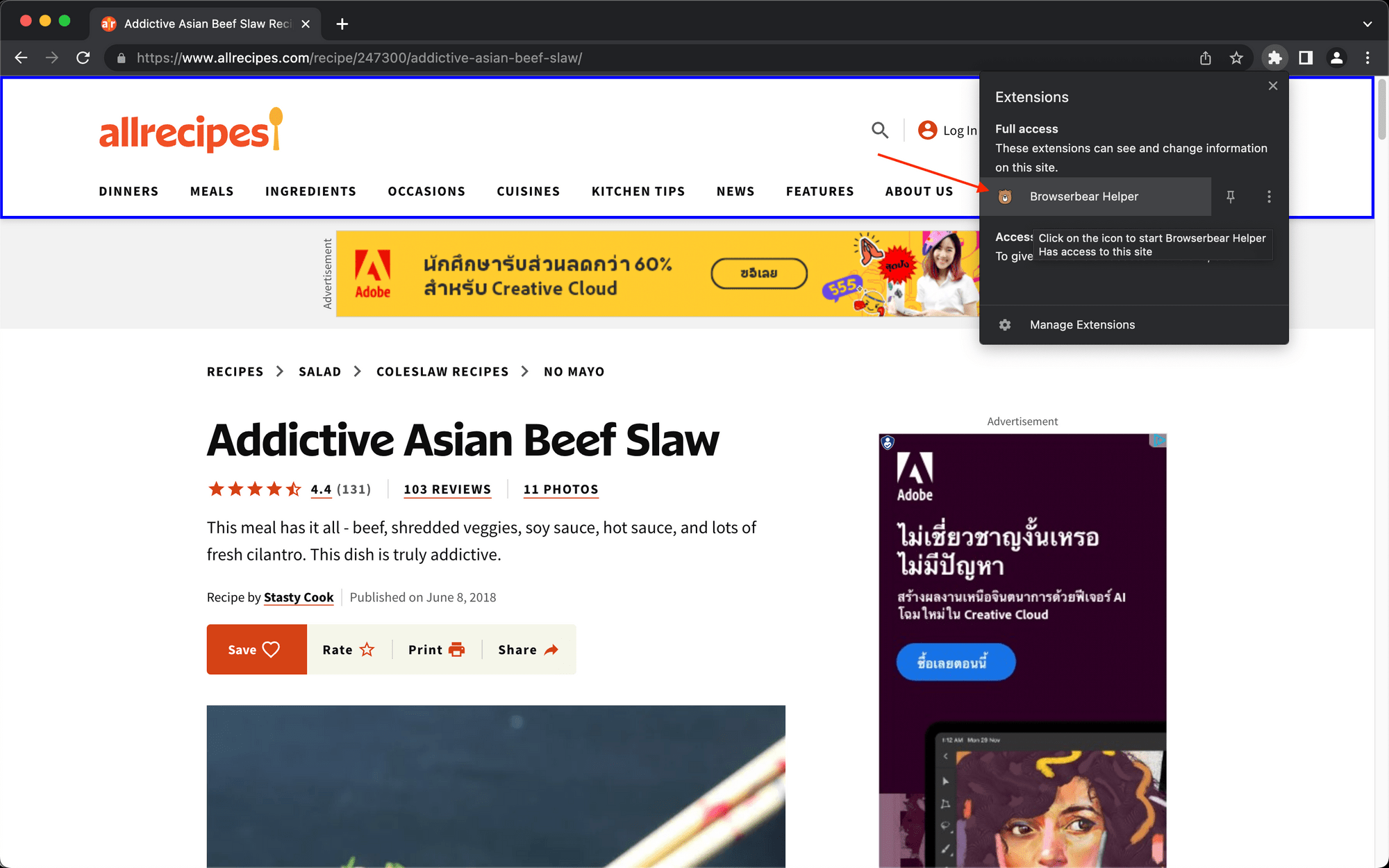
Hover over the parent container until a blue outline indicates the selection. Take special care to make sure the entire list you are scraping is within the container.
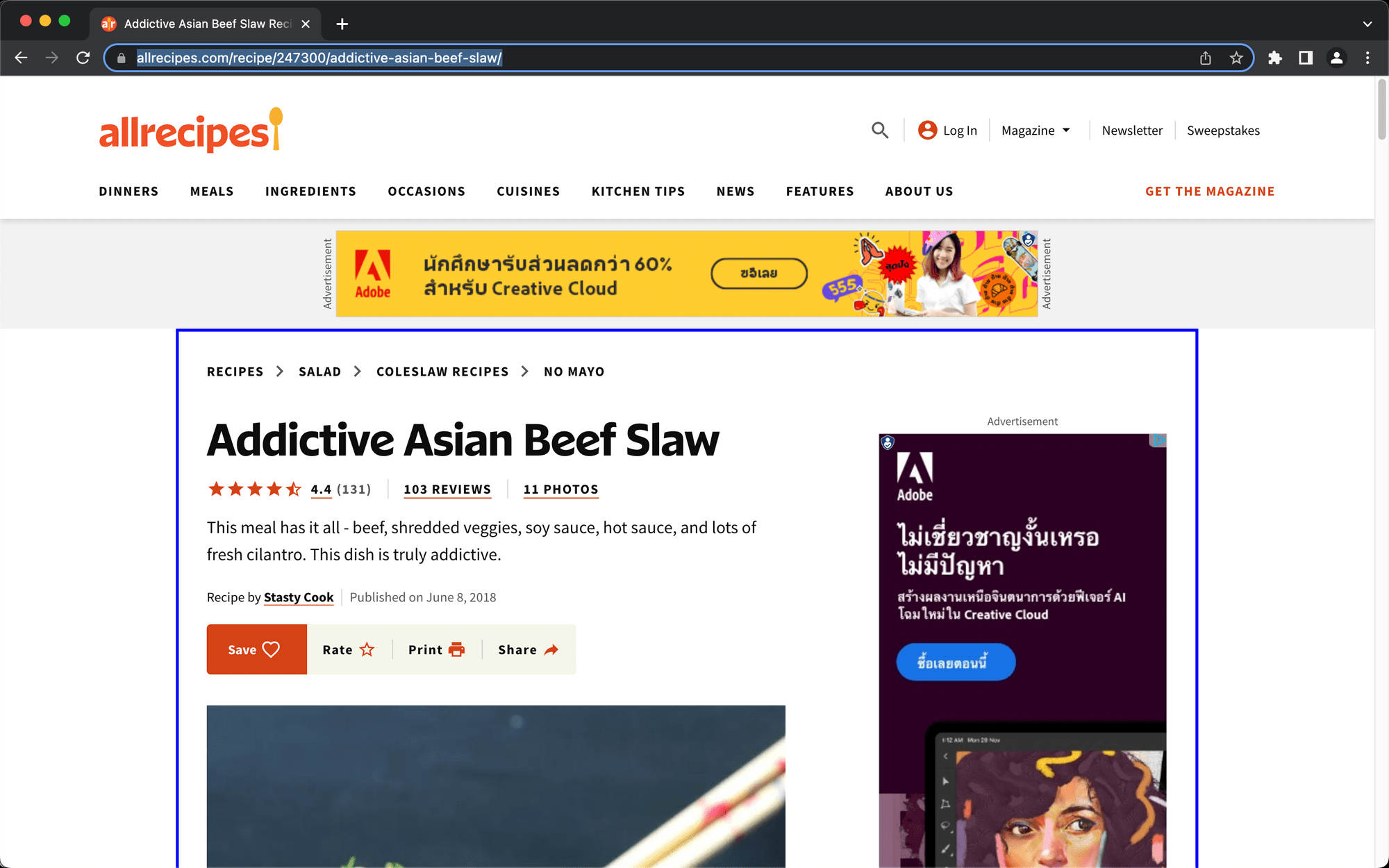
Click the element, then copy the config in the popup window.
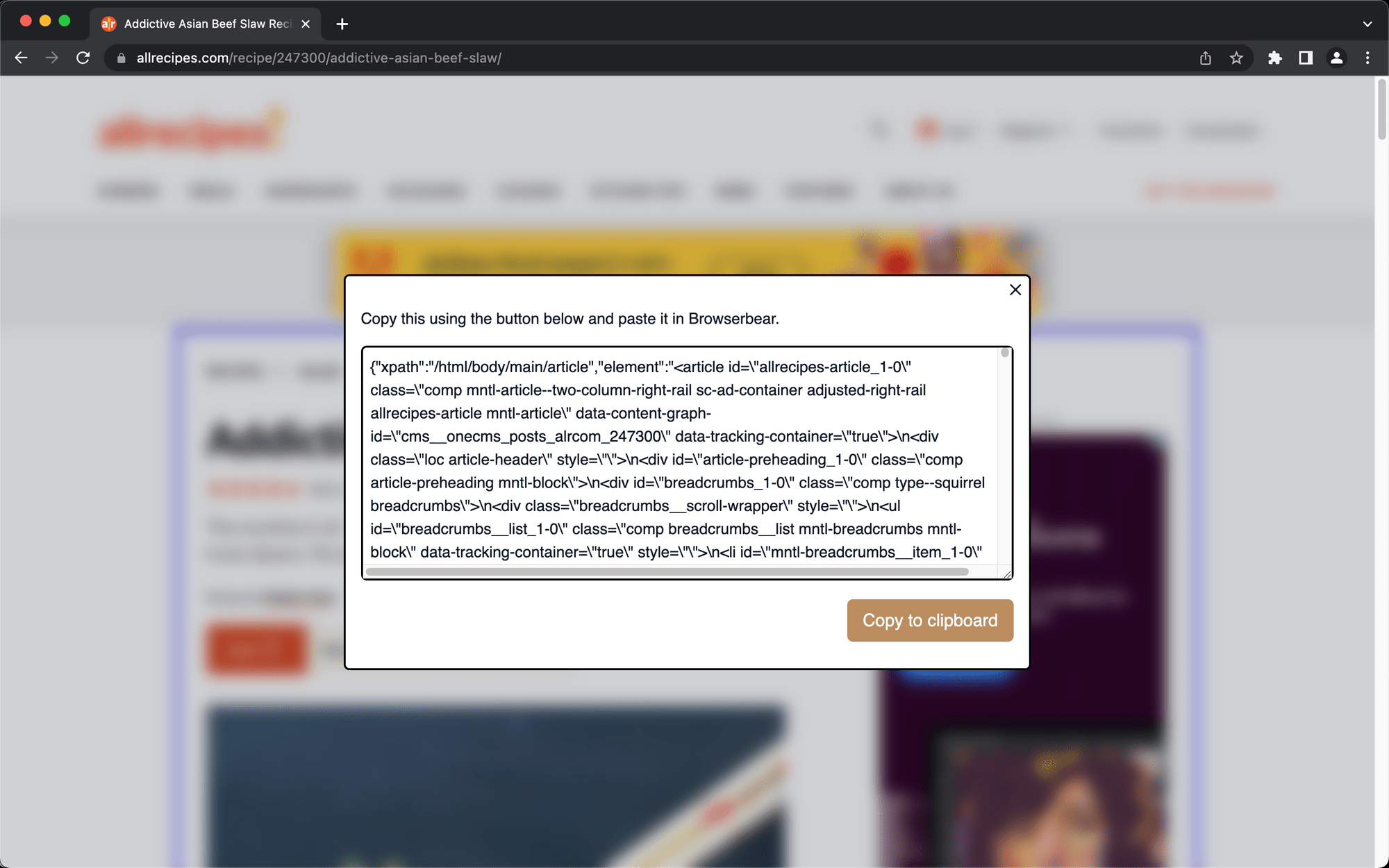
Paste the config into the Helper section of your save_structured_data step.
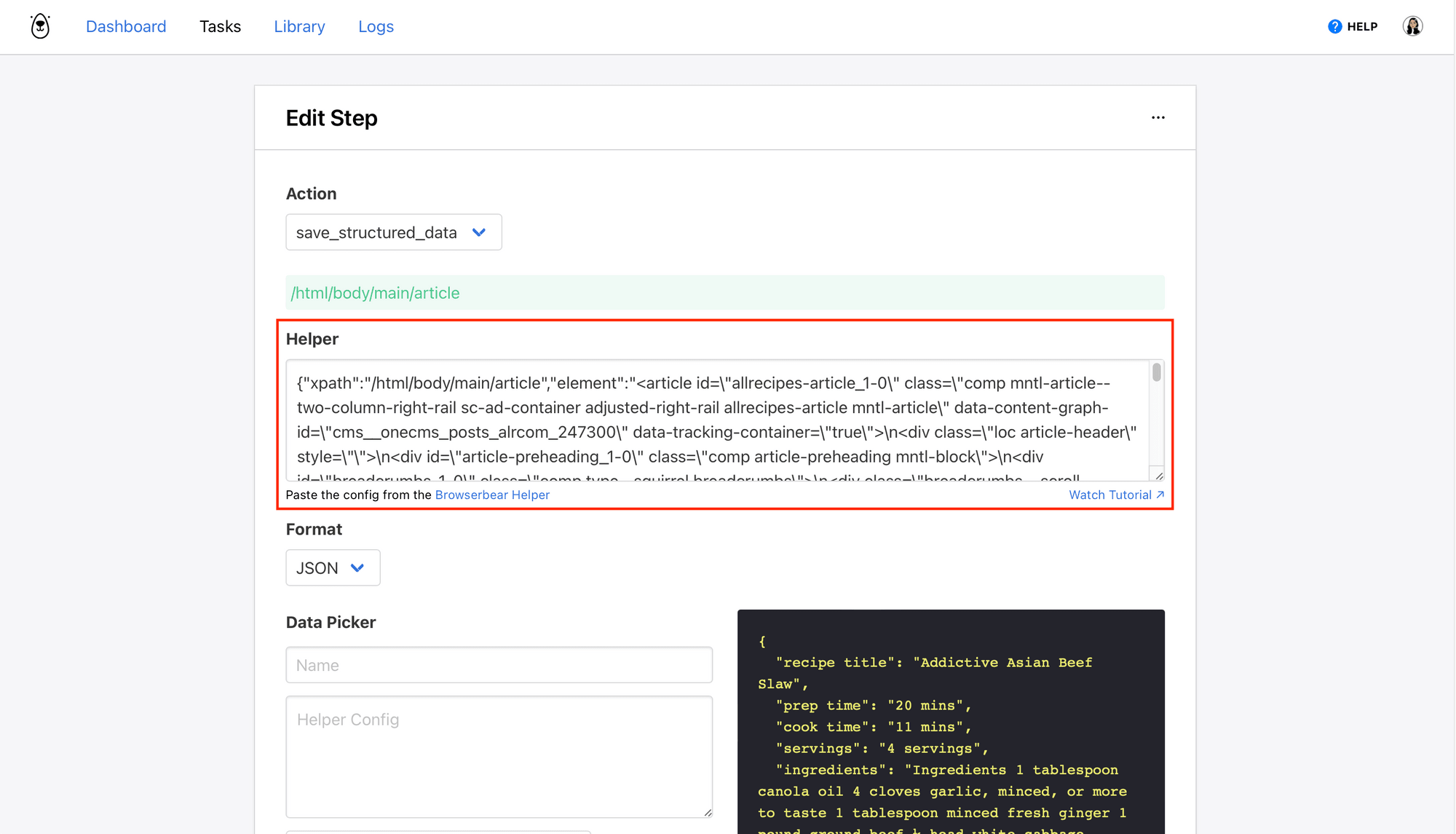
Your parent container has been defined; now, we have to identify the individual HTML elements we want to scrape.
Return to your destination site and make sure the extension is activated. Hover over the list you want to scrape and click when a blue outline surrounds the entire block.
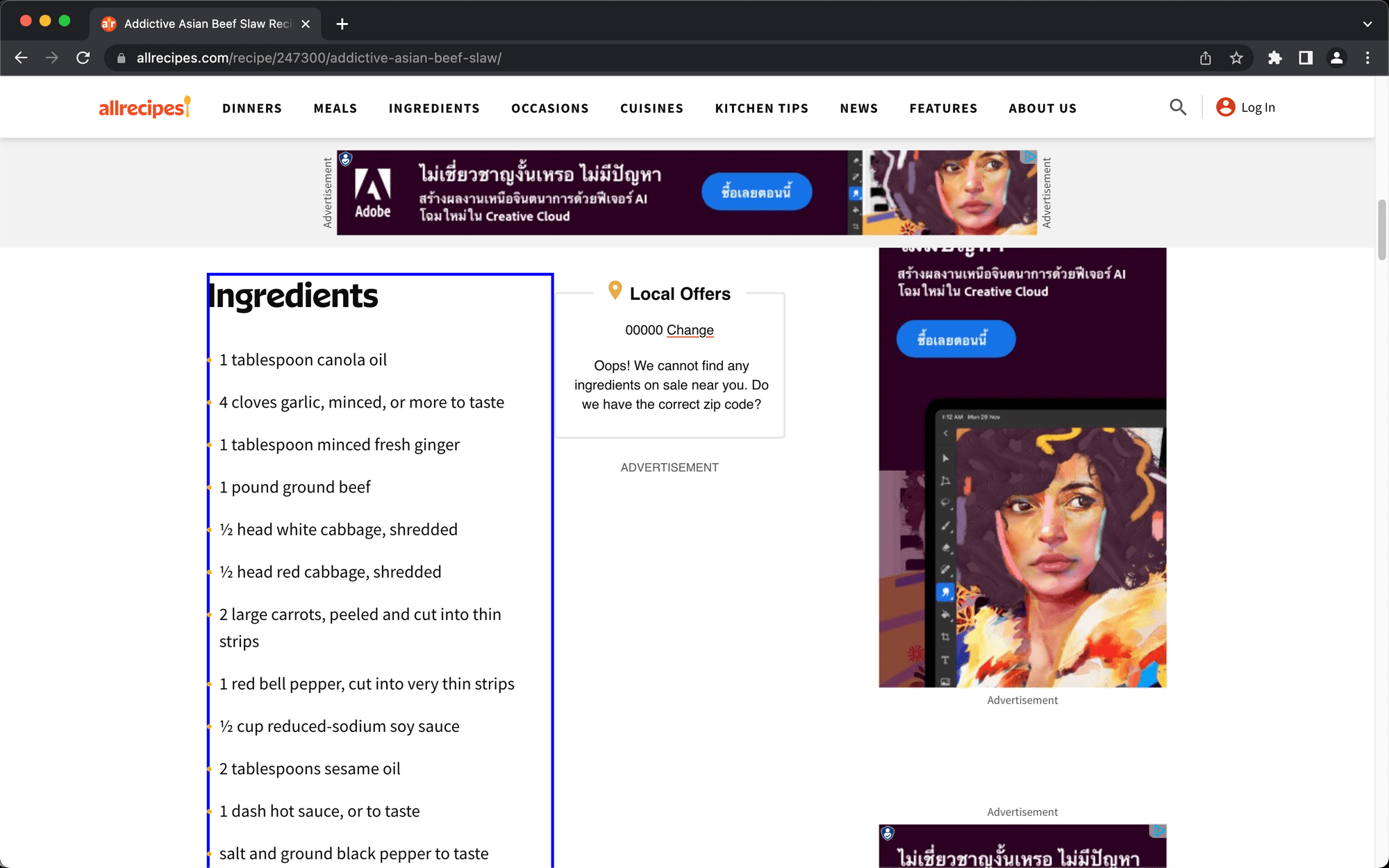
Copy the config and paste it into the Helper Config section of the Data Picker. Add a name and specify the type of data you want to pull (the default is Text ).
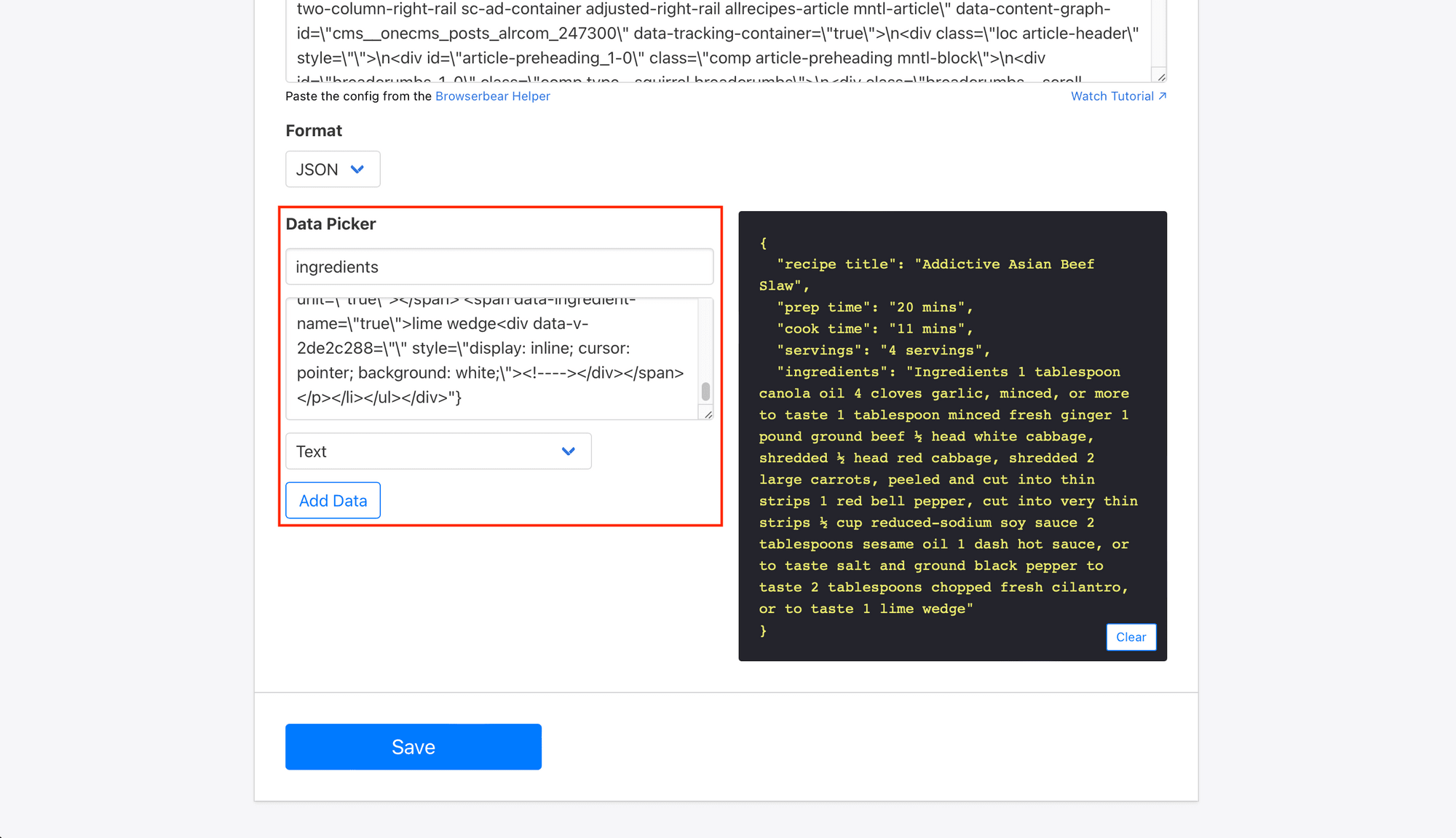
Click Add Data.
Repeat this step for any other children HTML elements you want scraped, then click Save once everything has successfully loaded onto the log on the right side of the task builder.
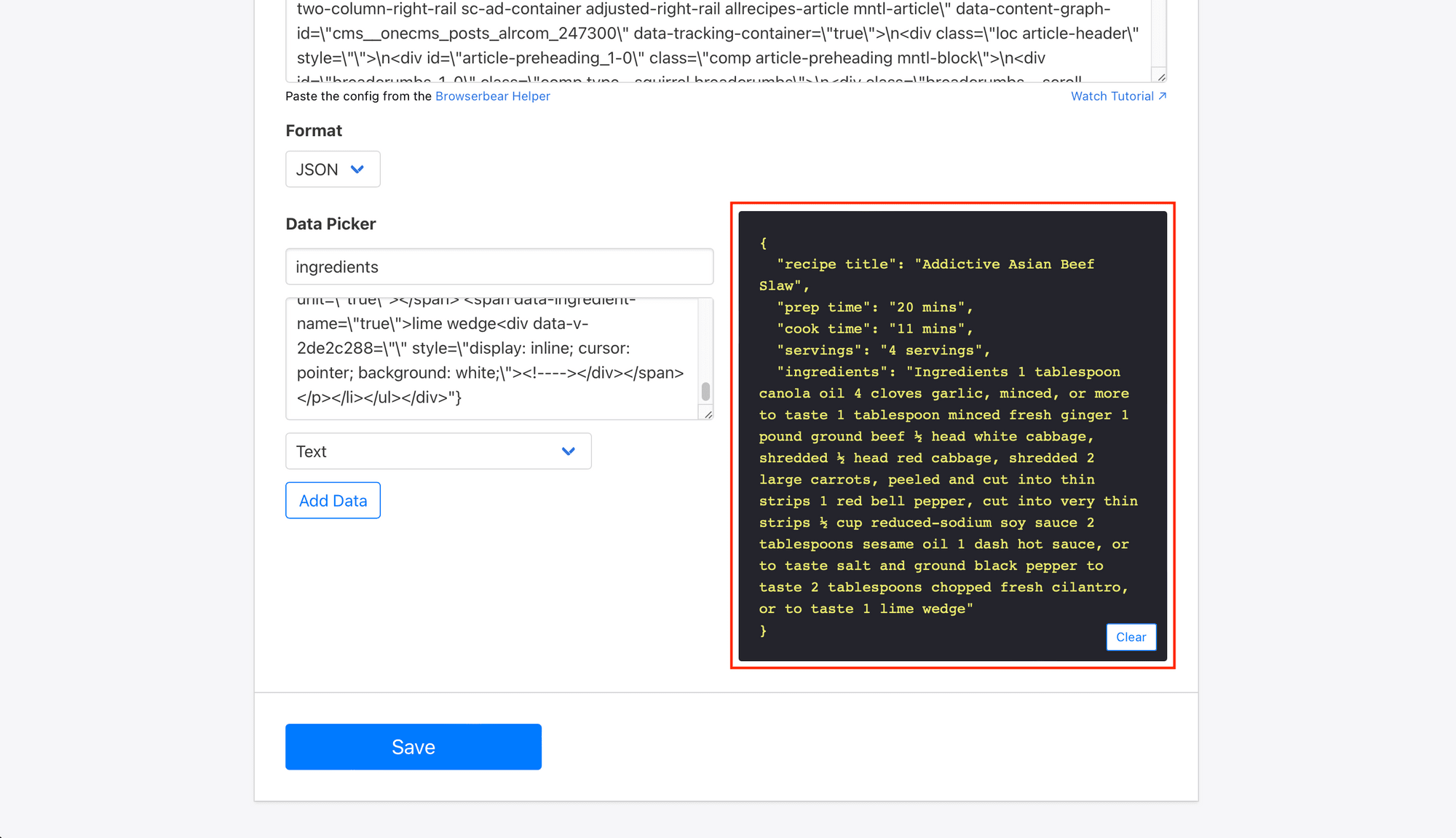
Return to your task page, then click Run Task to test your automation.
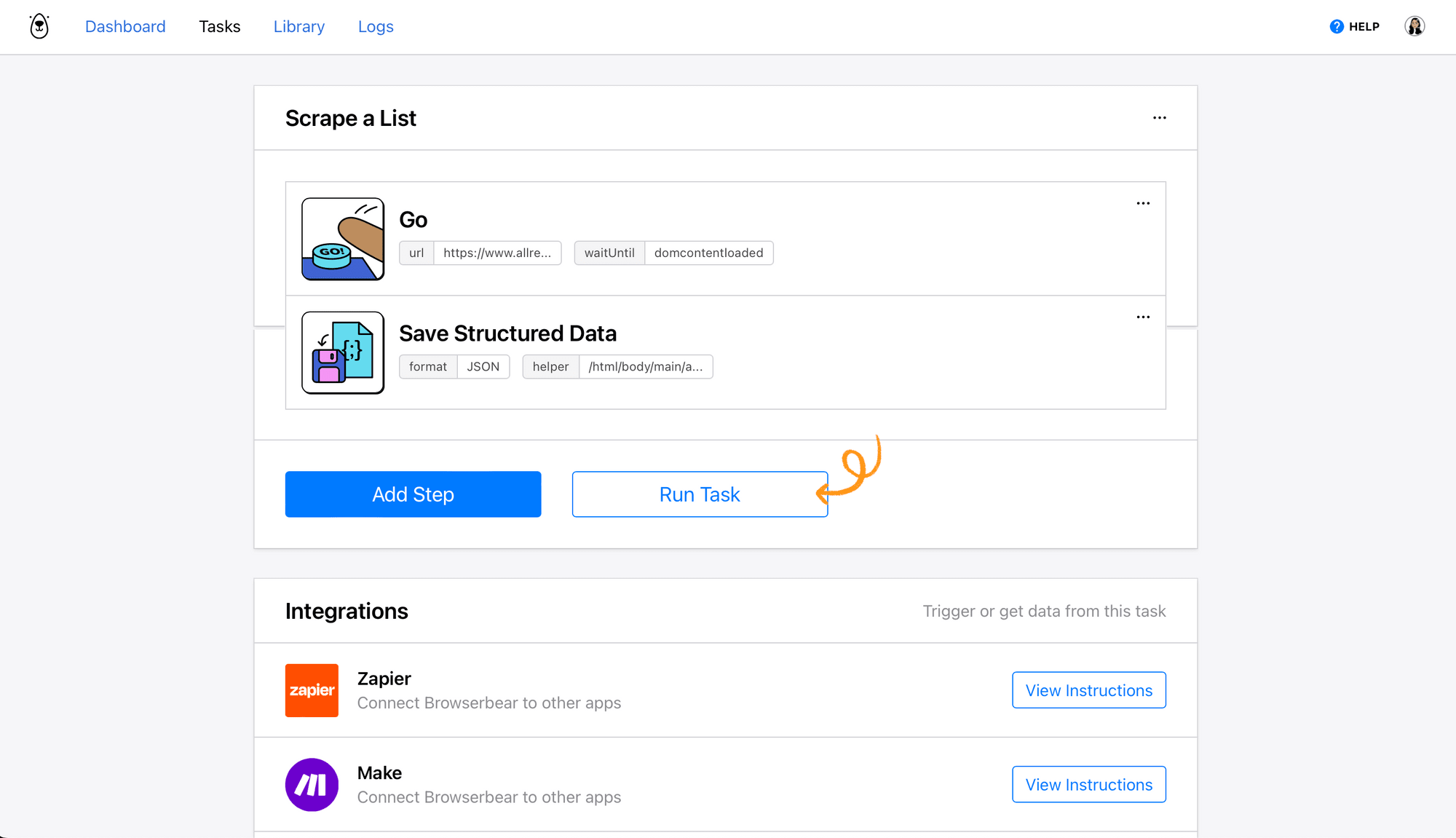
A run will appear at the bottom of your task page, showing if it is successfully completed.

If you click Log , you’ll be able to see the output of your browser task.
Note that the output is in HTML format; tags like \n, \n1, and so on signify line breaks.
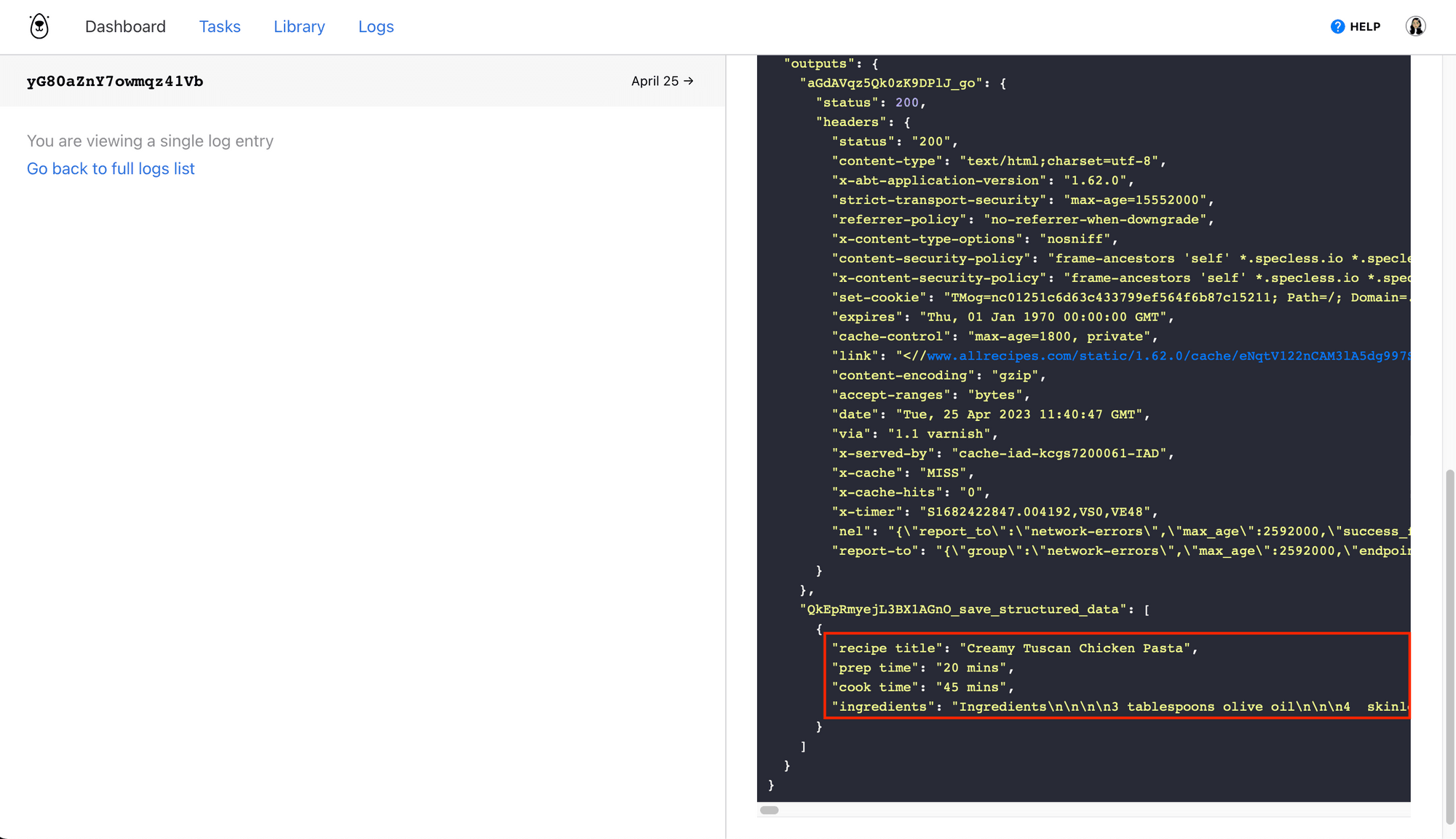
To make it easier to view, we’ve used Zapier to automatically send the structured data to Airtable.
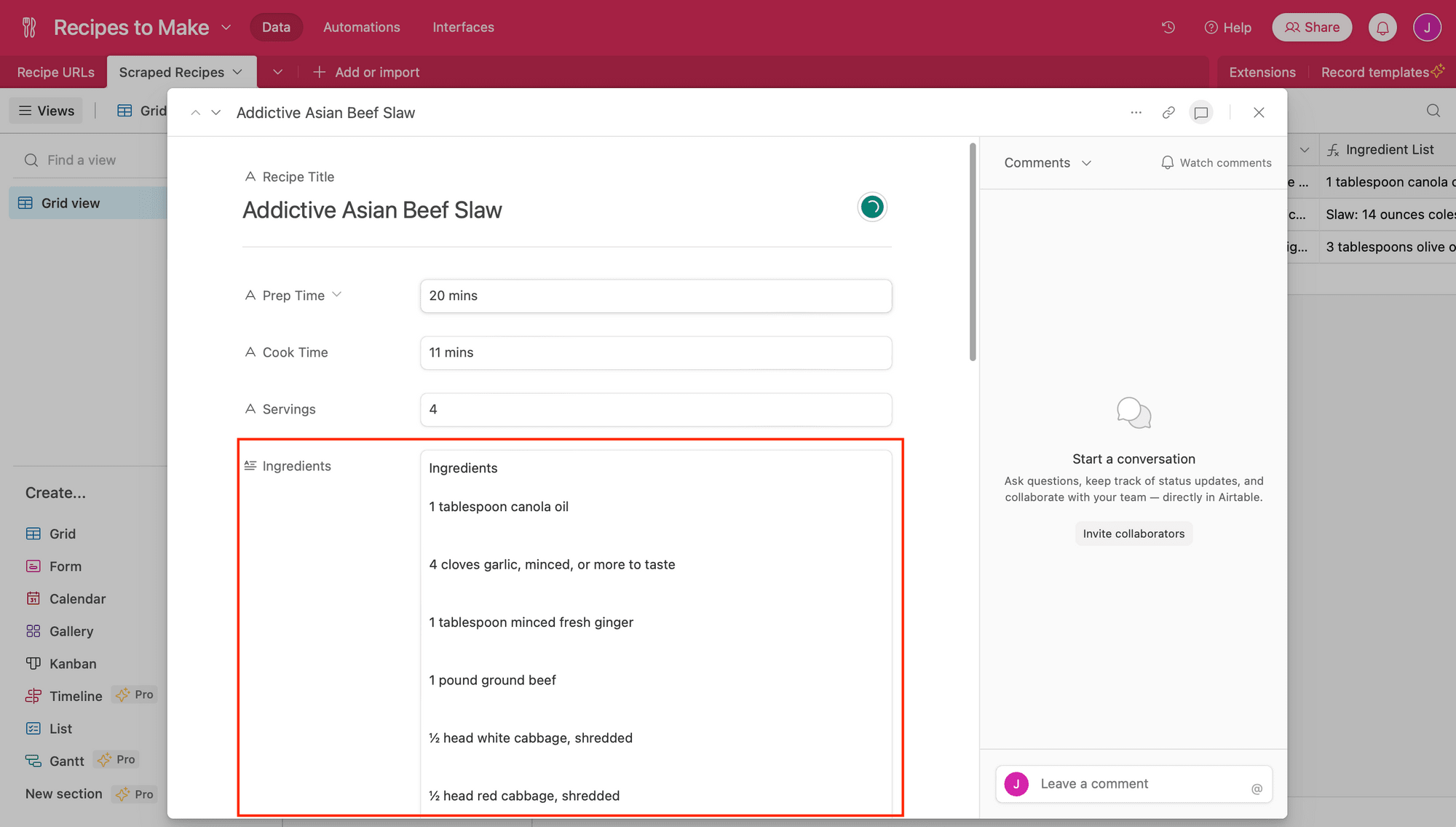
As you can see, the list items are still properly formatted with line breaks, making it easy for you to view and manipulate according to your needs.
3 Tips for Scraping Lists from Web Pages
Scraping lists from web pages can be challenging because it requires ensuring the accuracy of extracted data as well as correct formatting. Here are some tips to increase the accuracy of your automation and ensure you get the expected output:
1 - Select Containers that Work with a Variety of Webpages
Consider the characteristics of the website you're scraping before deciding on the save action and setting up the automation. Does a single page have multiple parent containers with lists you want to scrape? Or is there only one list you're extracting from multiple pages?
Choosing an action and container that work reliably will help. When using the Chrome extension to select the config of the list element, make sure the blue outline contains the entire list, without any items left out.
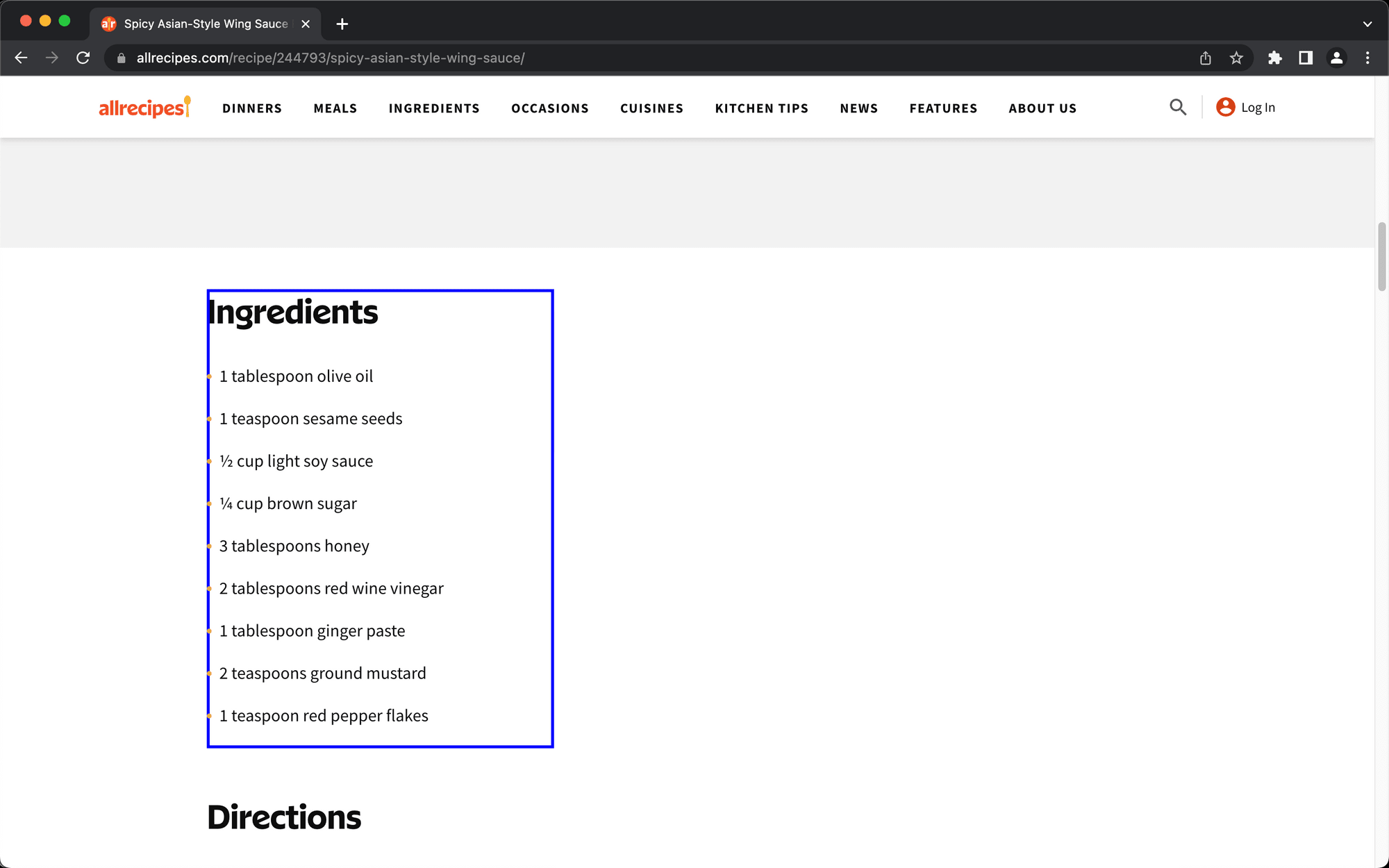
Test the selection across multiple pages to ensure lists can be fully extracted. Keep in mind that this is only possible if the webpages have identical structures.
2 - Override the “Go” Action with Zapier
When scraping from multiple non-consecutive webpages, you'll need to override the first destination URL. This is possible using the REST API or using Zapier for a no-code option.
The zap to override the “ go ” action is simple: a trigger that actives on a schedule or in response to an event, followed by an action that signals Browserbear to launch a task run.
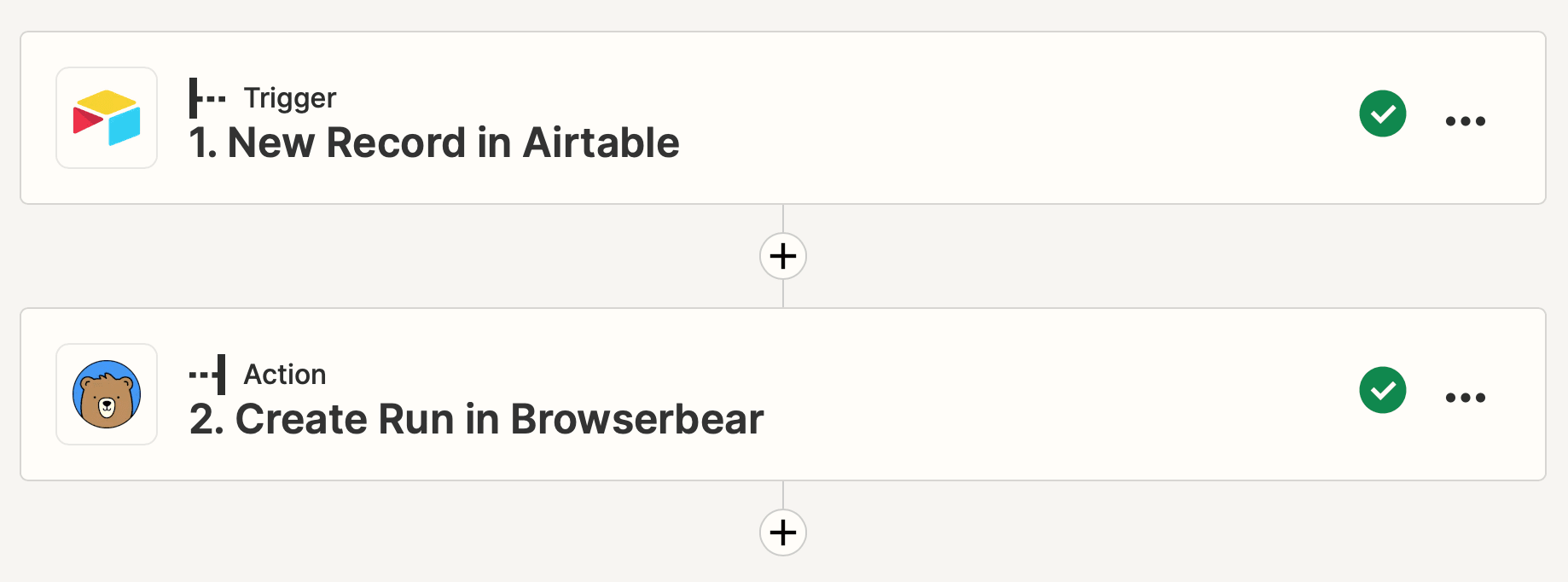
Set up the action to map to a dynamic field with links to other webpages you want to scrape. In this example, we're using Airtable.
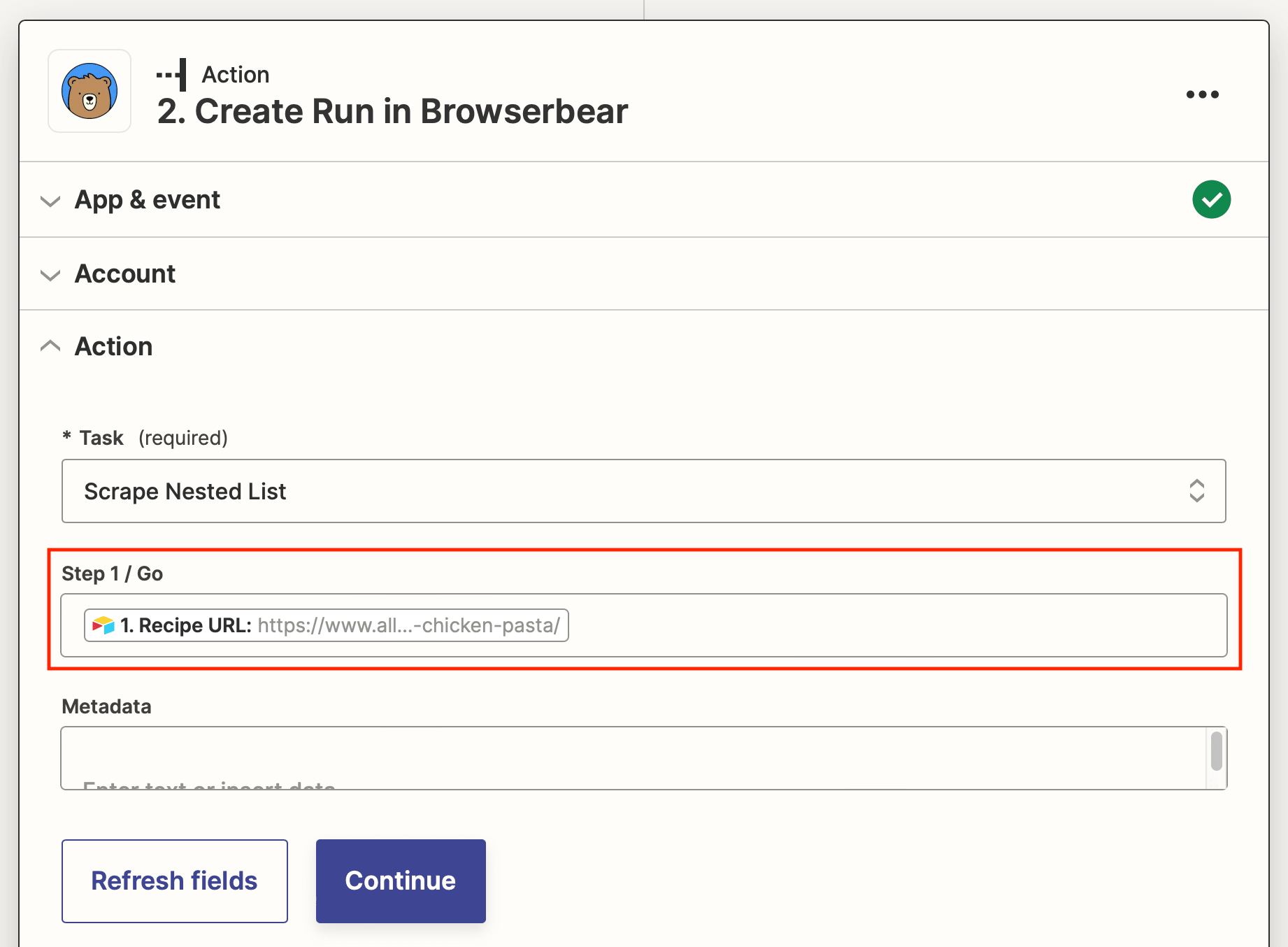
When links are added to the database, they override the destination URL and trigger a new task run.
3 - Use Database Formulas to Adjust Formatting
The list you extract from a webpage is in HTML format and may require some formatting adjustments. If you need to adjust spacing, remove unnecessary text, or make other formatting changes, it's often easier to do so in the database.
Familiarize yourself with the syntax and a few basic formulas on your database of choice. On Airtable, for instance, \ndenotes a line break and REGEX formulas can be useful for correcting irregularities in your lists. Formulas like TRIM and SUBSTITUTE can also be used to remove unnecessary text.
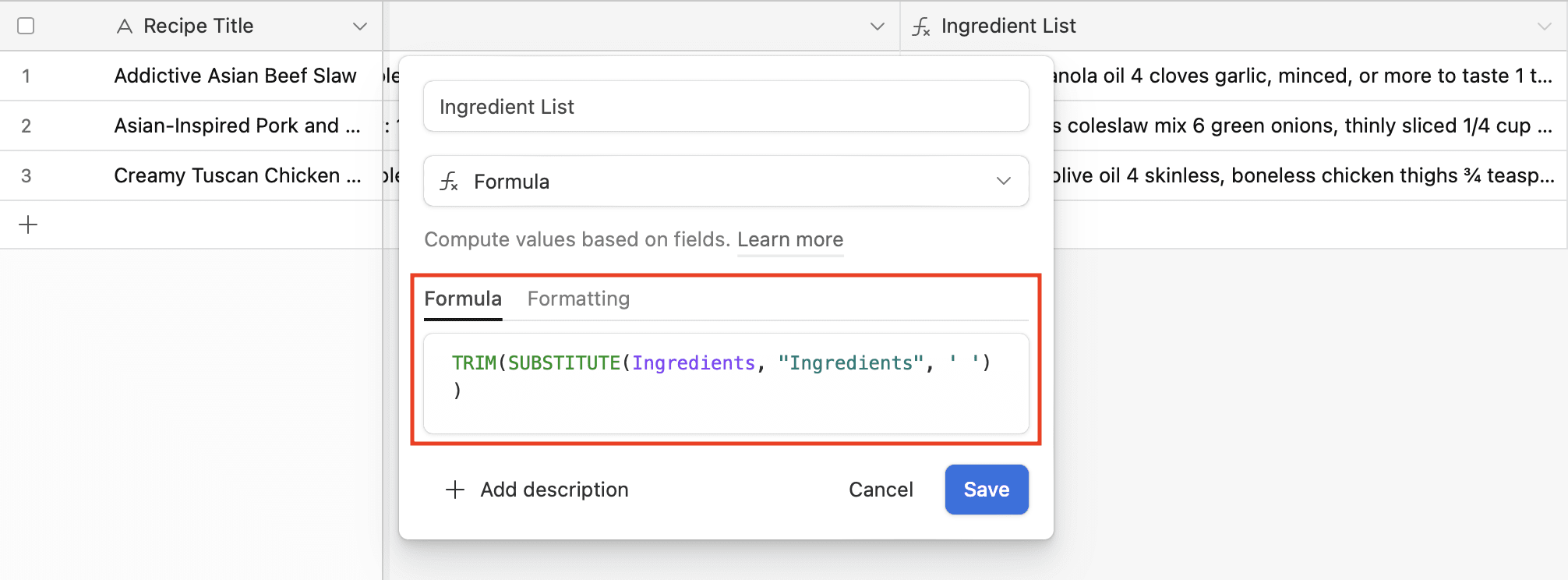
Check the task run log to see how the extracted data is formatted, making it easier to adjust the result to your needs.
Scrape Lists Accurately with a Browser Automation Tool
Many data scraping use cases will still involve saving each element as its own item. However, there are still situations where you might have to group similar things together. By selecting the right containers and setting up the appropriate actions, you can easily and accurately extract batched items, product descriptions, recipe ingredients, and other list-based information.
With these tips and tools, you’ll be on your way to efficiently and effectively scraping lists from the web with Browserbear.
