


How to Scrape Data from a Website Using Roborabbit (Part 1)
Contents
Data scraping, also known as web scraping, is a technique used to extract large amounts of data from websites and various sources, transforming unstructured data into a structured format. This process can be automated and makes collecting information from various sources more efficient.
To make it more efficient, you can use a cloud-based data scraping tool. It provides greater accessibility, scalability, and flexibility. One such tool is Roborabbit, a cloud-based browser automation tool that you can use to automate various browser tasks, including scraping data.
In this tutorial, we will learn how to scrape data from a website using Roborabbit. To demonstrate how the job title, company, location, salary, and link on a job board can be saved as structured data using Roborabbit, we will use this Roborabbit playground as an example.

What is Roborabbit
Roborabbit is a scalable, cloud-based browser automation tool that helps you to automate any browser task. From automated website testing, scraping data, taking scheduled screenshots for archiving, to automating other repetitive browser tasks, you can do it with Roborabbit.
Similar to Bannerbear, the featured automated image and video generation tool from the same company, you can easily create no-code automated workflows by integrating it with other apps like Google Sheets, Airtable, and more on Zapier. Besides that, you can also use the REST API to trigger tasks to run in the cloud and receive data from the completed tasks.
Scraping a Website Using Roborabbit
You will need a Roborabbit account to follow this tutorial. If you don't have one, you can create a free account.
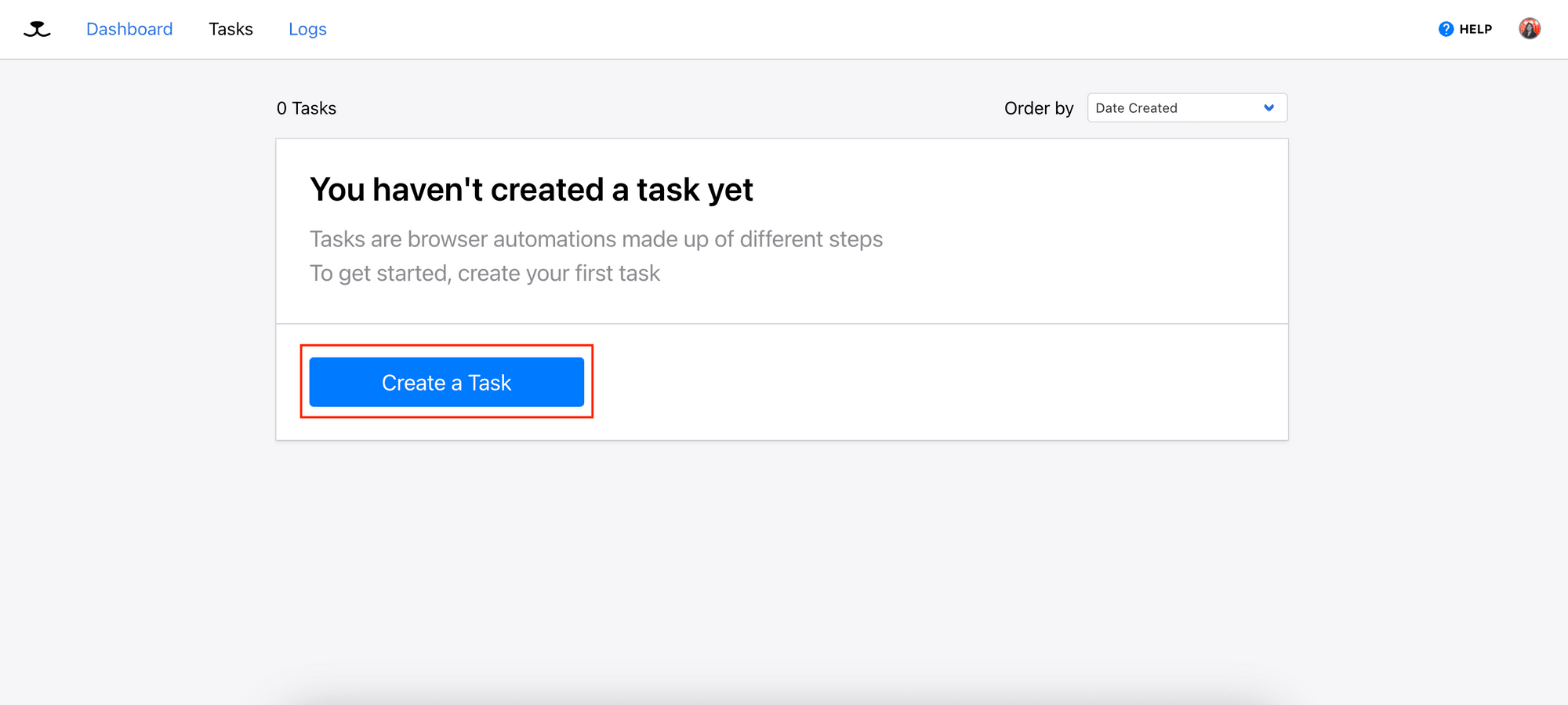
1. Create a Task
After logging in to your account, go to Tasks and create a new task.
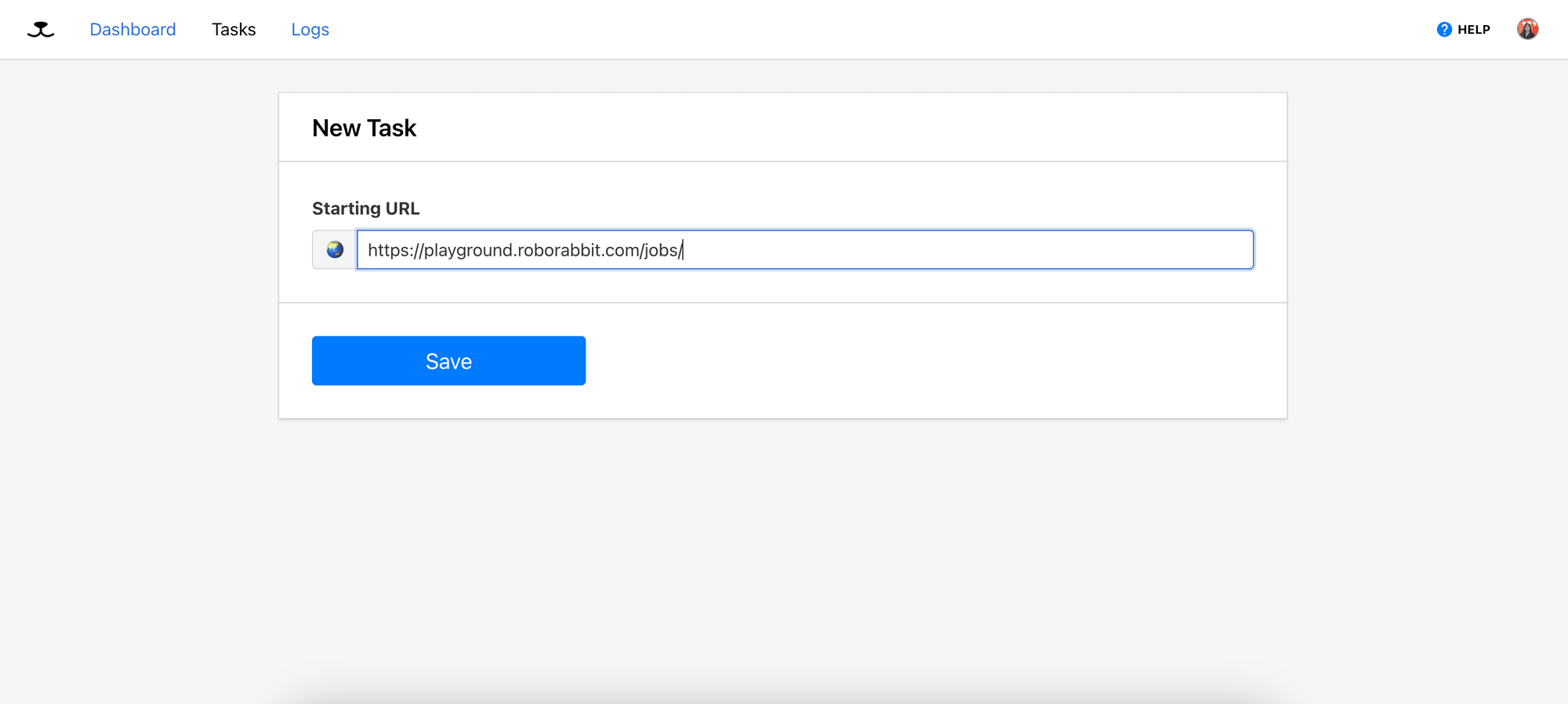
2. Enter the Starting URL
Enter the starting URL for your task and click the “Save” button.
The "Go" action will be automatically added as the first step of the task to visit the starting URL:
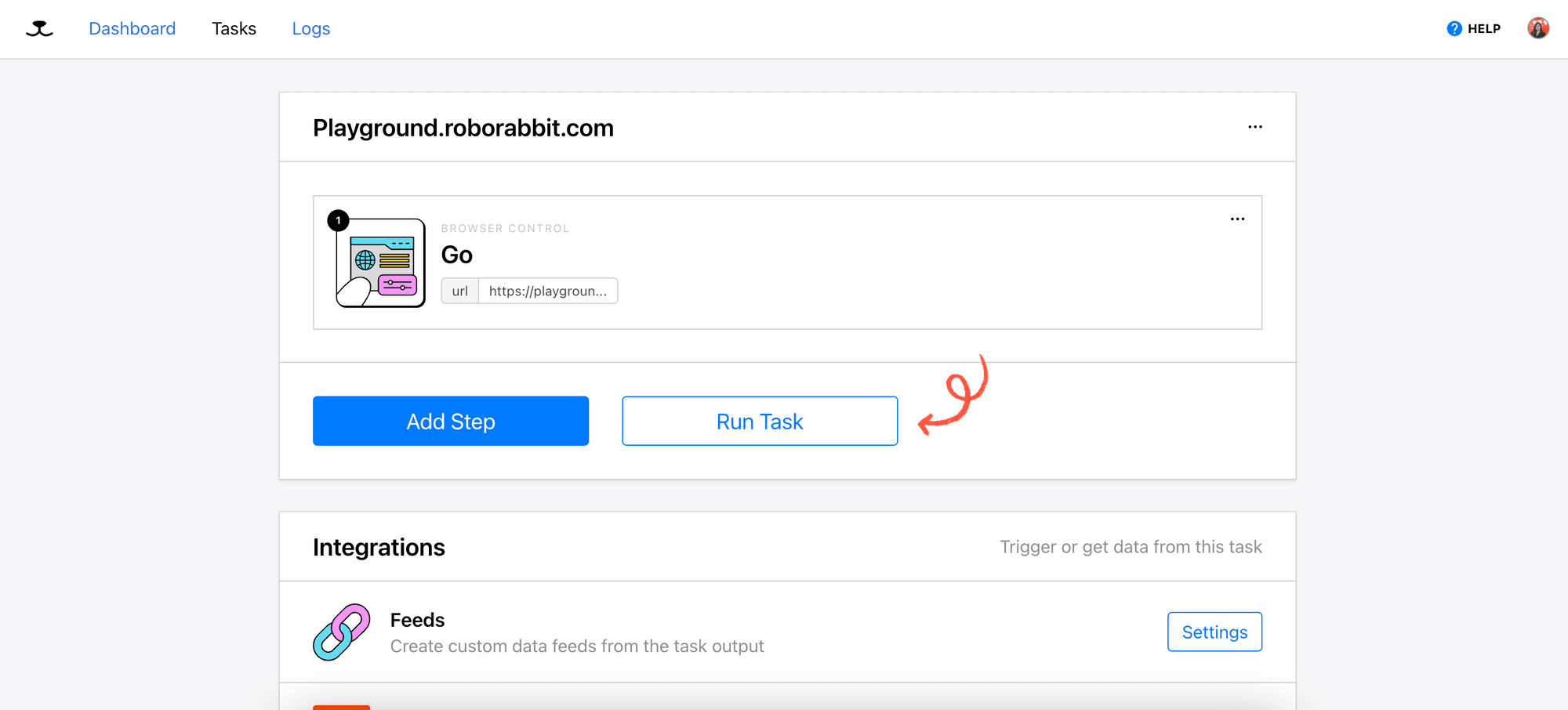
3. Add Steps - Save Structured Data
Click “Add Step” to add the second step. For this step, we will need to specify:
i) A parent container (in Helper)
ii) The children HTML elements that hold the data (in Data Picker)

Note: The children HTML elements must be contained within the parent container.
To locate the parent container and the children HTML elements, we will need to pass a helper config, which is a JSON object that contains the XPath and the HTML snippet of the elements to .
We will use the RoborabbitHelper Chrome extension to help us get the helper config. Install and pin it on your browser.
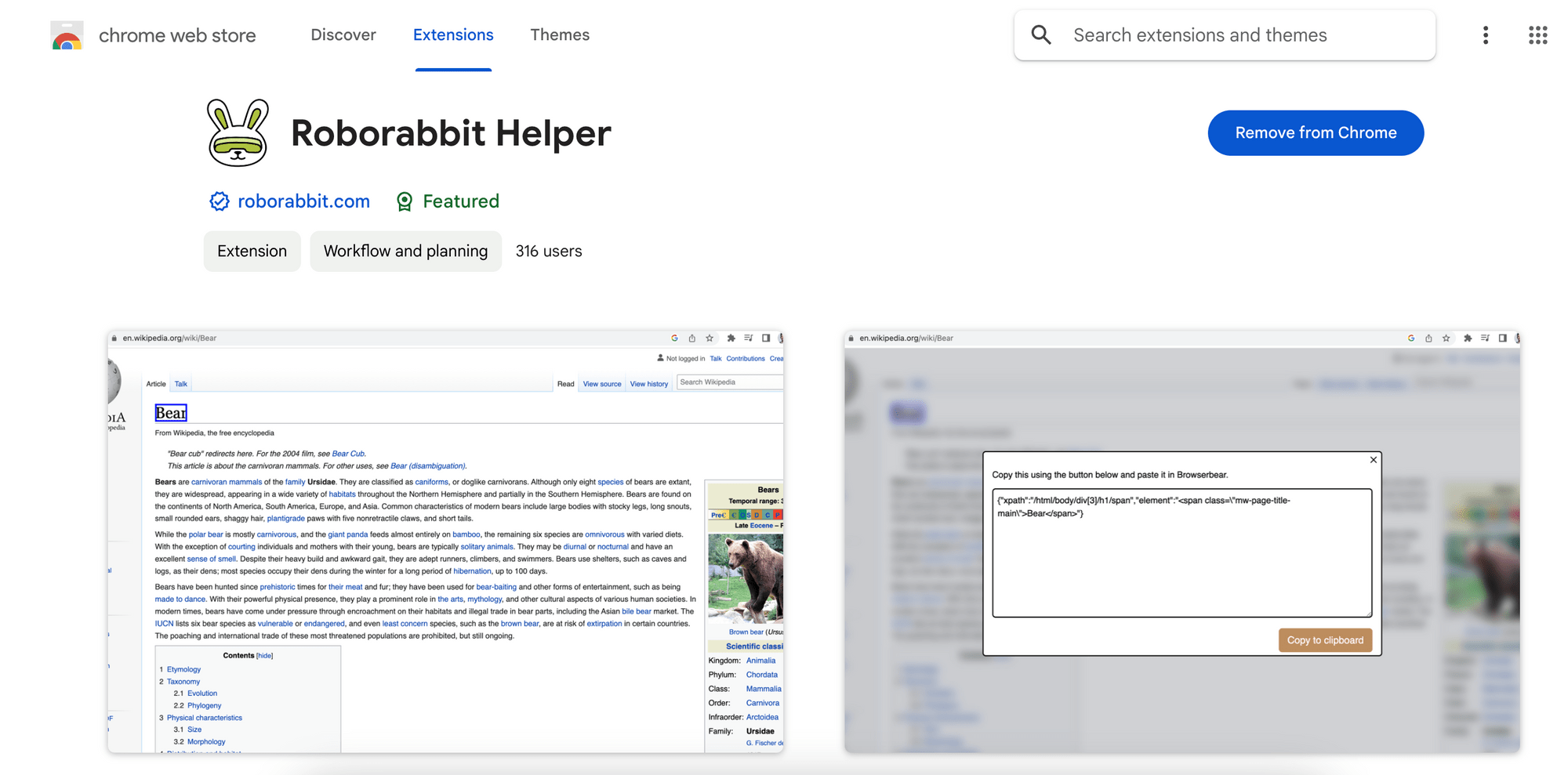
In Roborabbit, select “Save Structured Data” from the Action selection and you will see a textbox for Element. This is where we will add the helper config that points to the parent container.
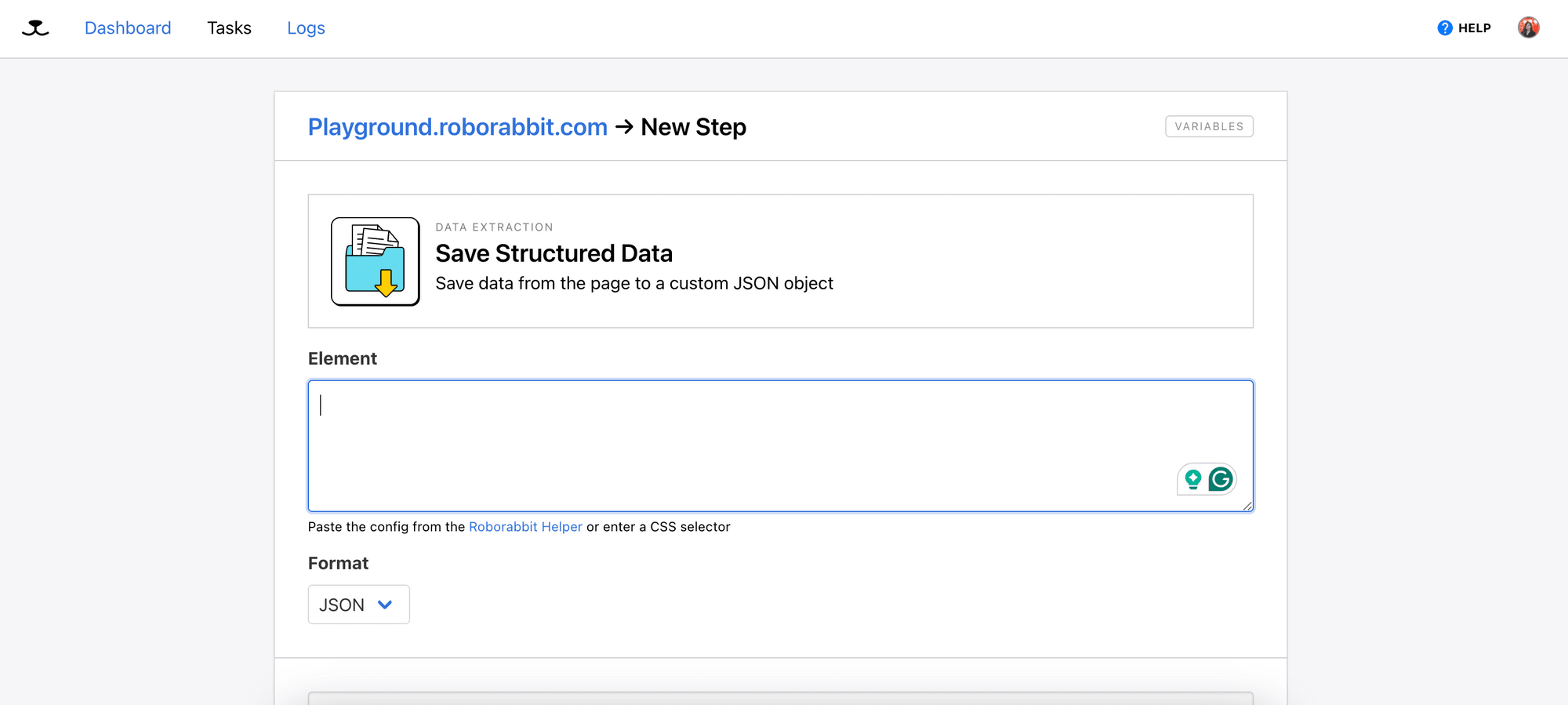
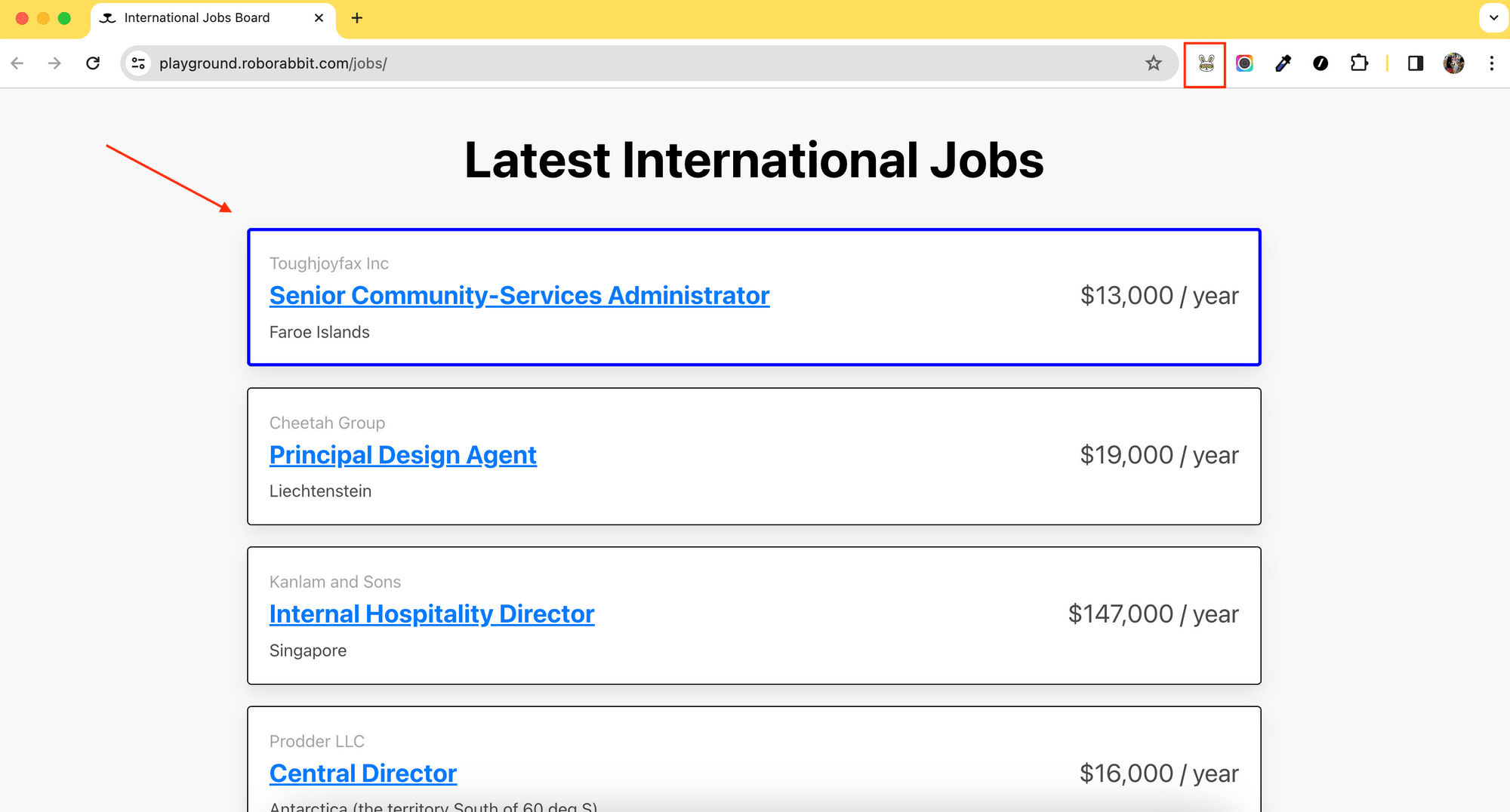
On the job board, click on the extension icon and hover your mouse over the card. You should see a blue box surrounding it.
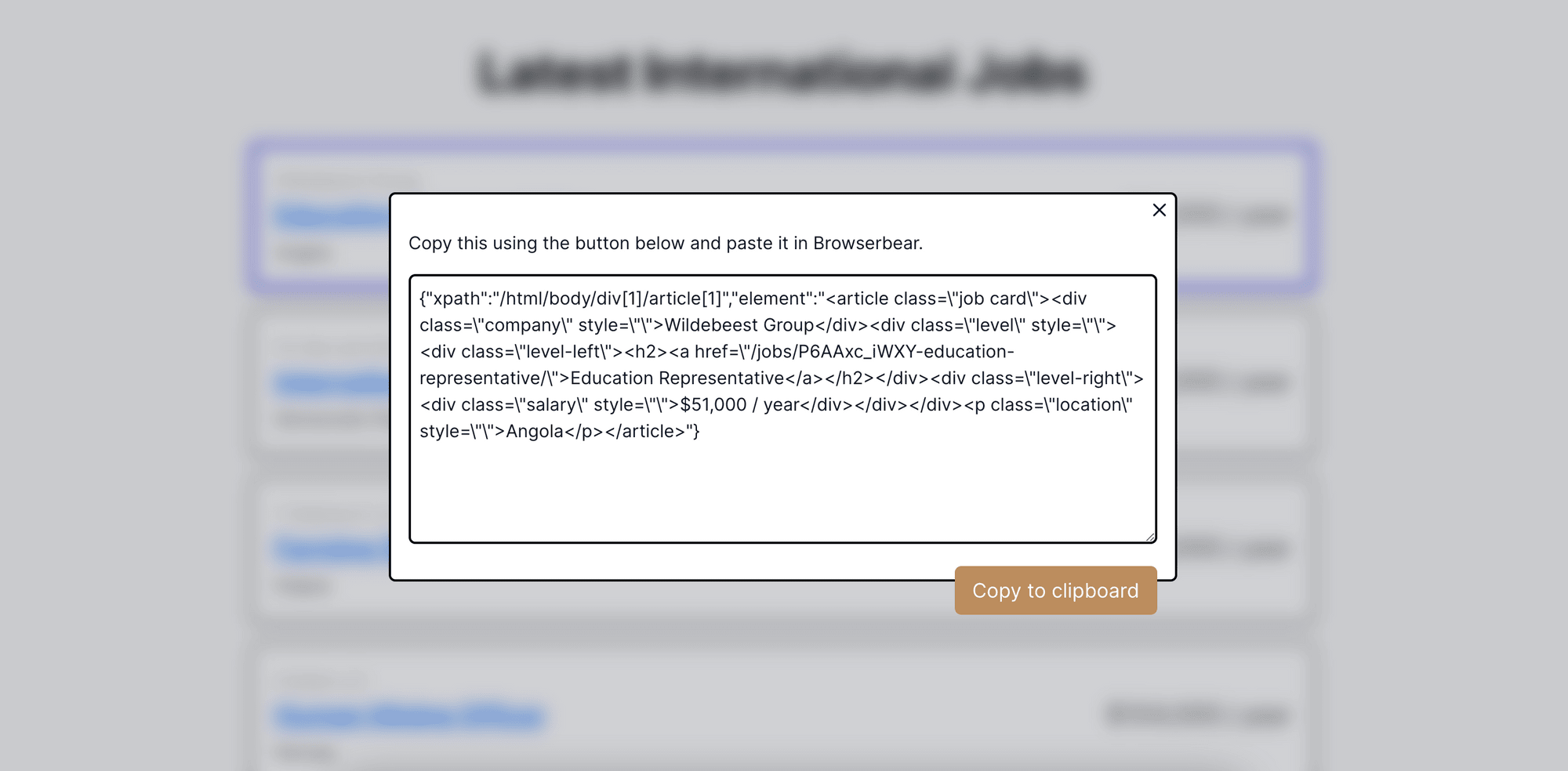
Click on the card to get the helper config. Copy and paste it into the Element textbox in your Roborabbit dashboard.
Roborabbit should list the potential tags that can be used to locate the selected element, with the recommended tag highlighted (article[class=“job”]):
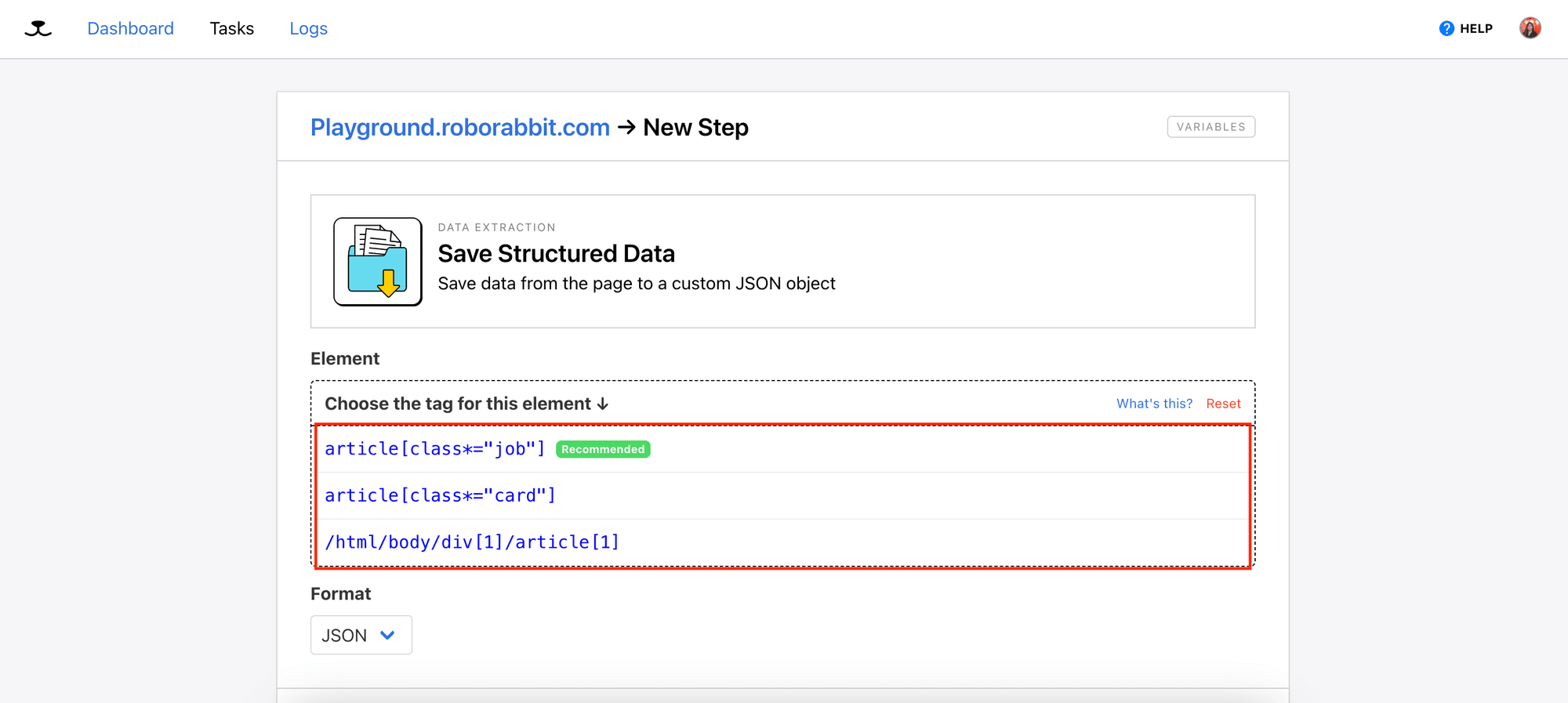
Select a tag from the list:
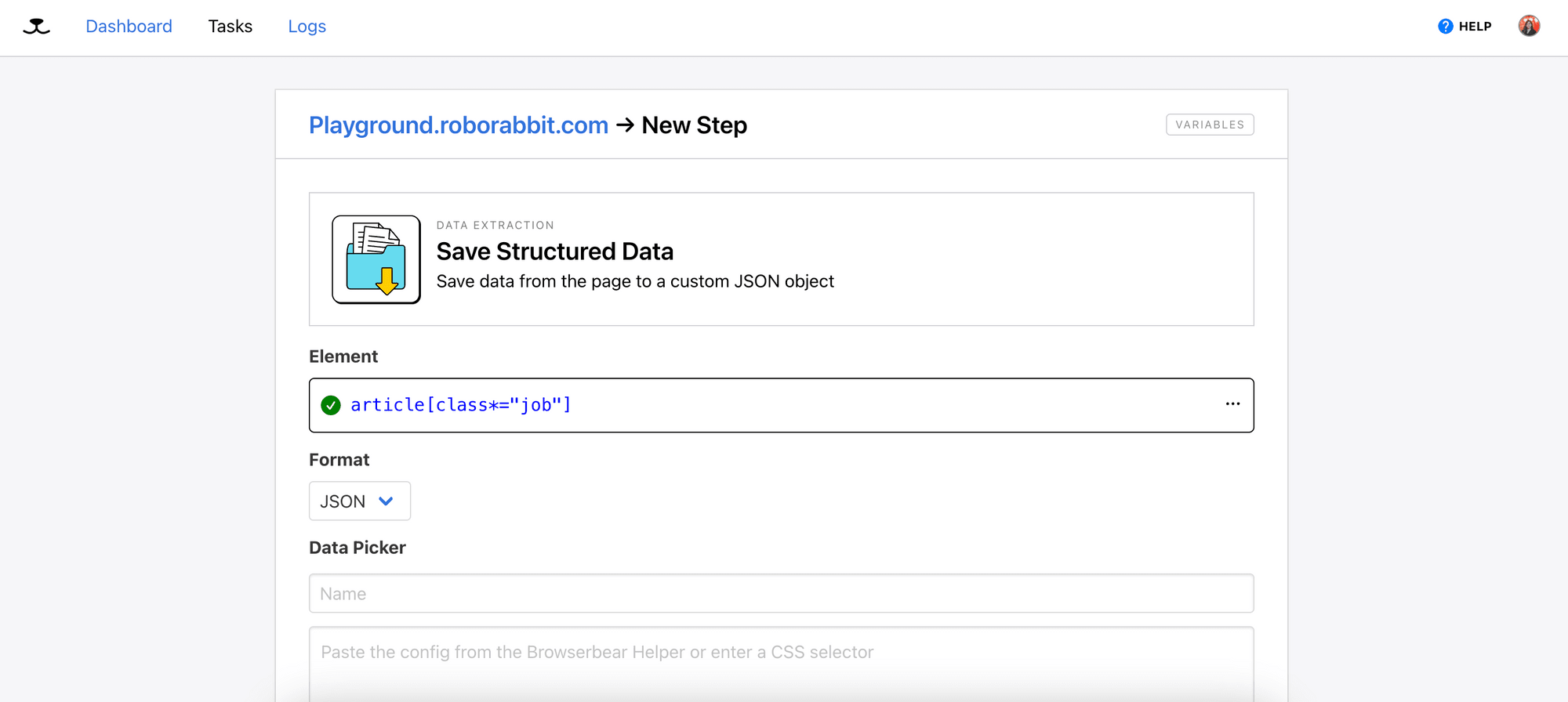
This will look for every HTML element with the article tag and the job class (parent container). However, it doesn’t tell Roborabbit which HTML element, in particular, to retrieve the data from.
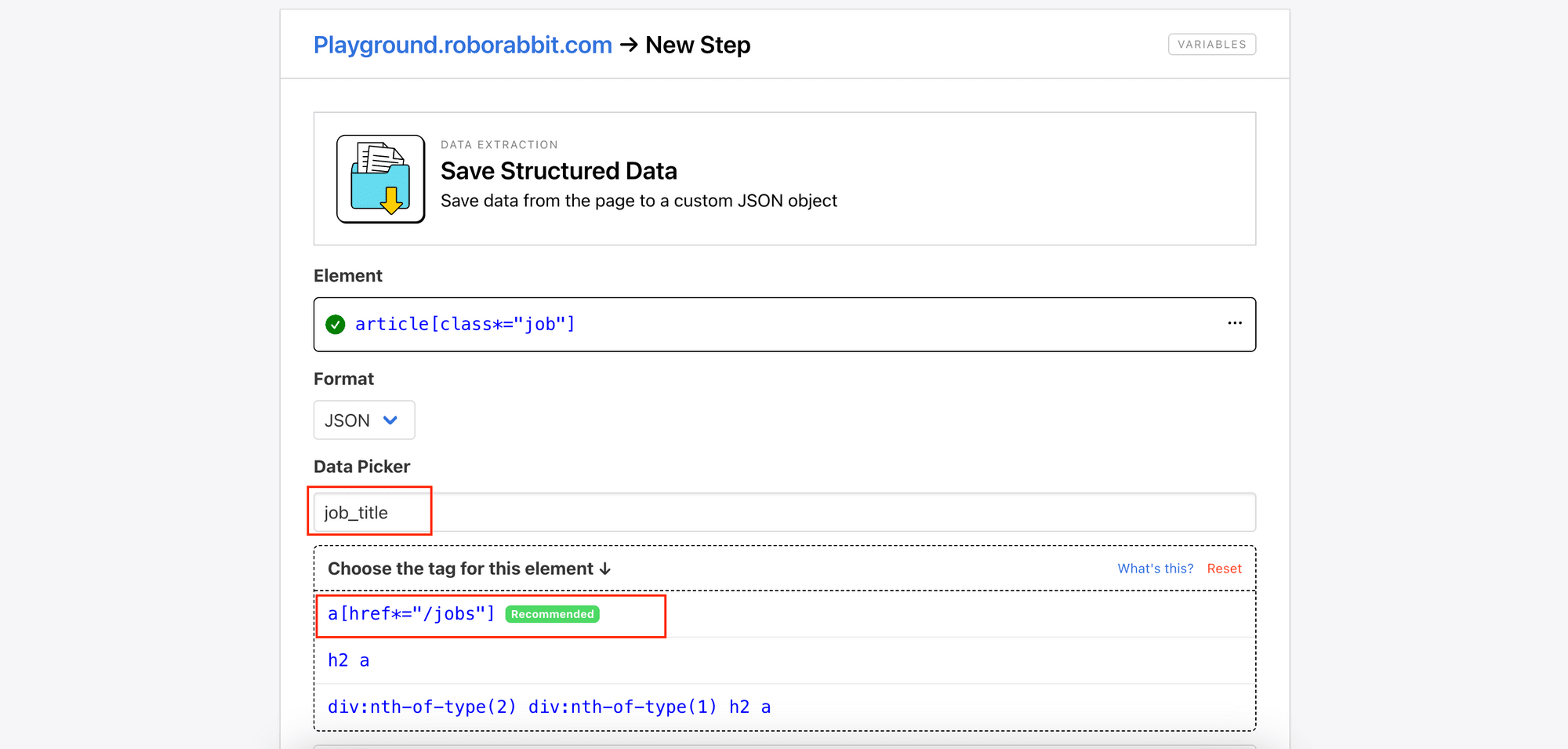
Therefore, we need to further specify the children HTML elements in the Data Picker. On the job board, click on the job title to get the helper config that refers to it.
Then, enter a name for the data (job_title), paste the config, and select a tag for the element from the tag list:
Click “Add Data” to add it to your structured data’s result (as shown in Data Preview):

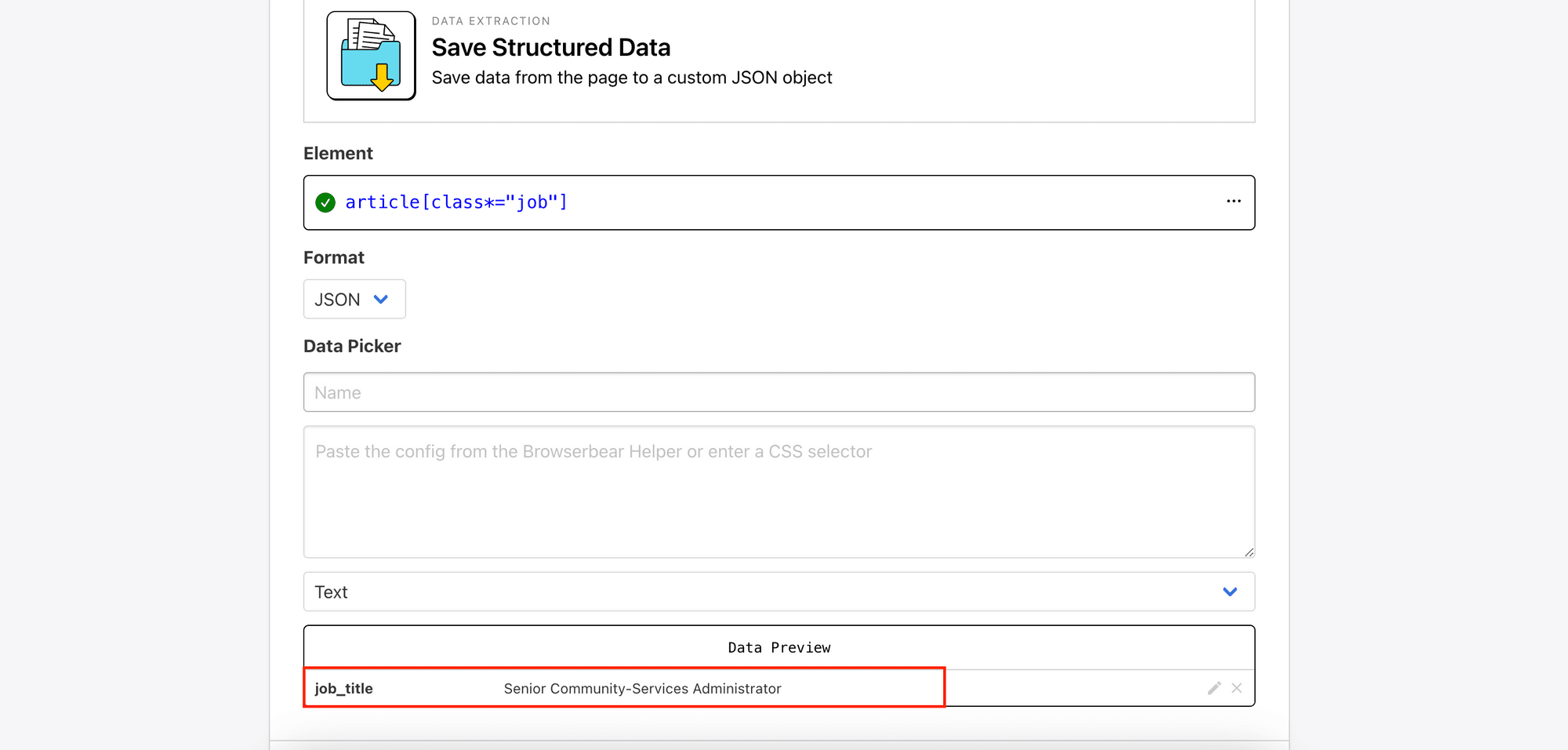
Repeat the same process for other texts like company , location , and salary. For the link to the job, choose href to retrieve the URL.
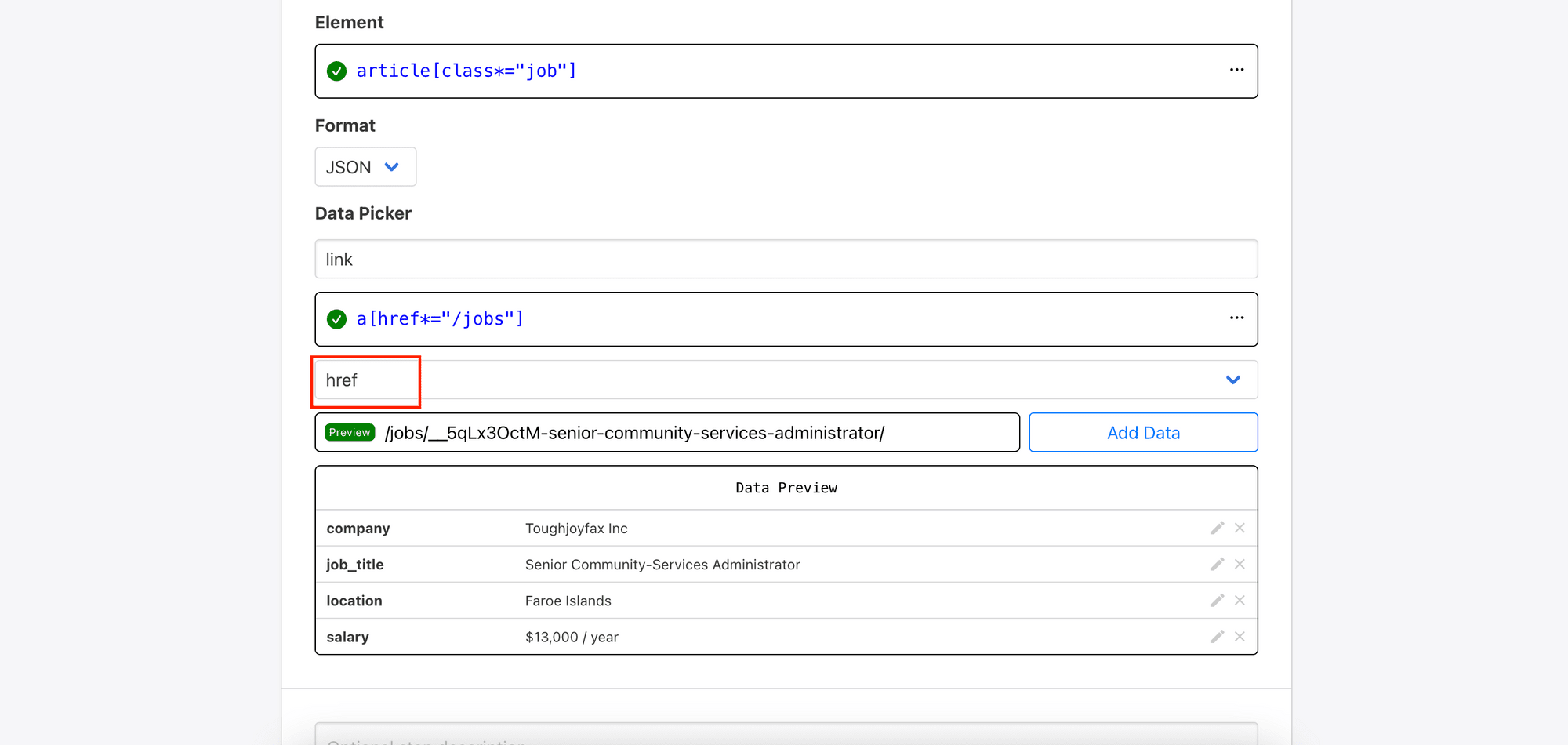
After selecting all the data, click the “Save” button to save the step.
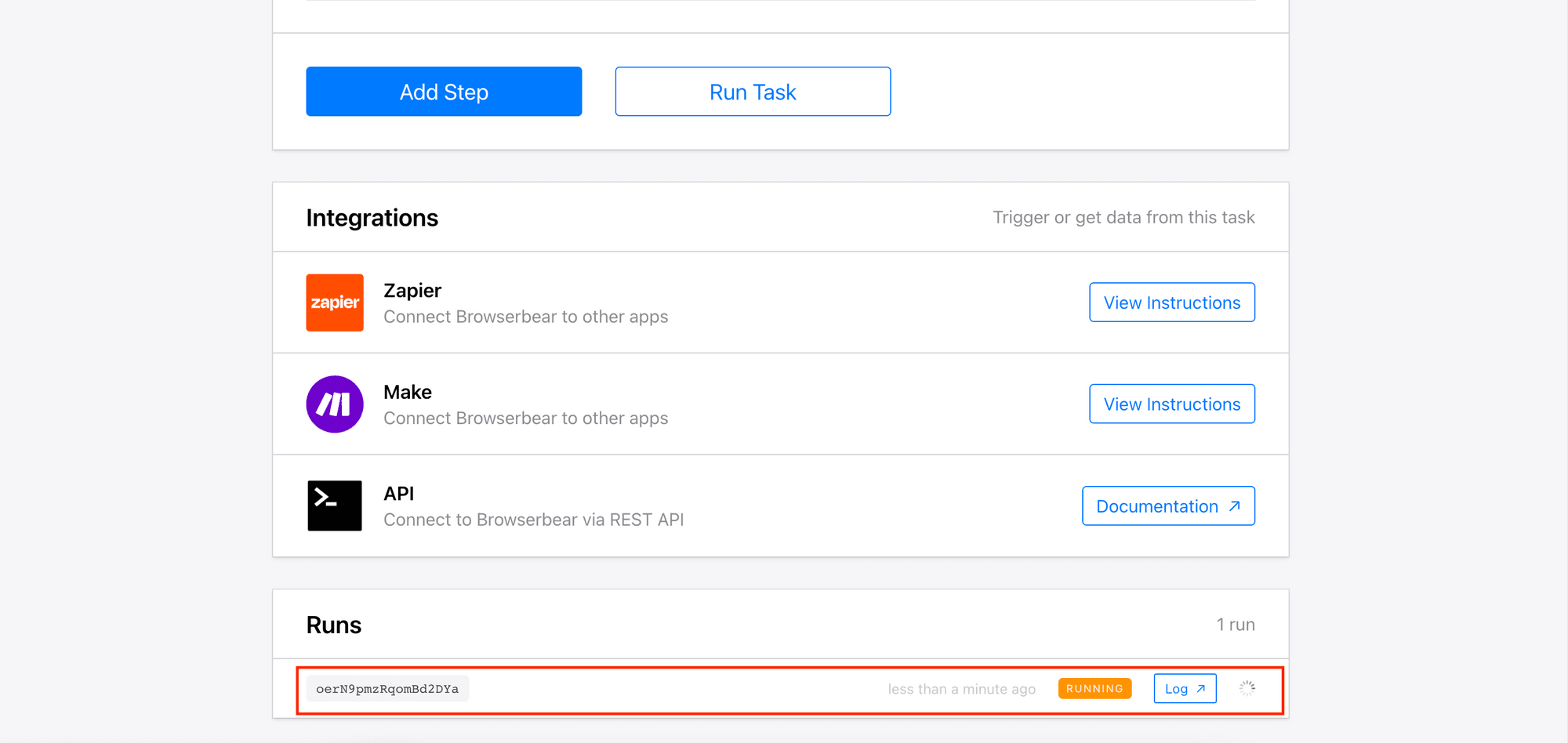
4. Run the Task
Click “Run Task” to start scraping data from the URL. You will see the task running when you scroll to the bottom of the page.
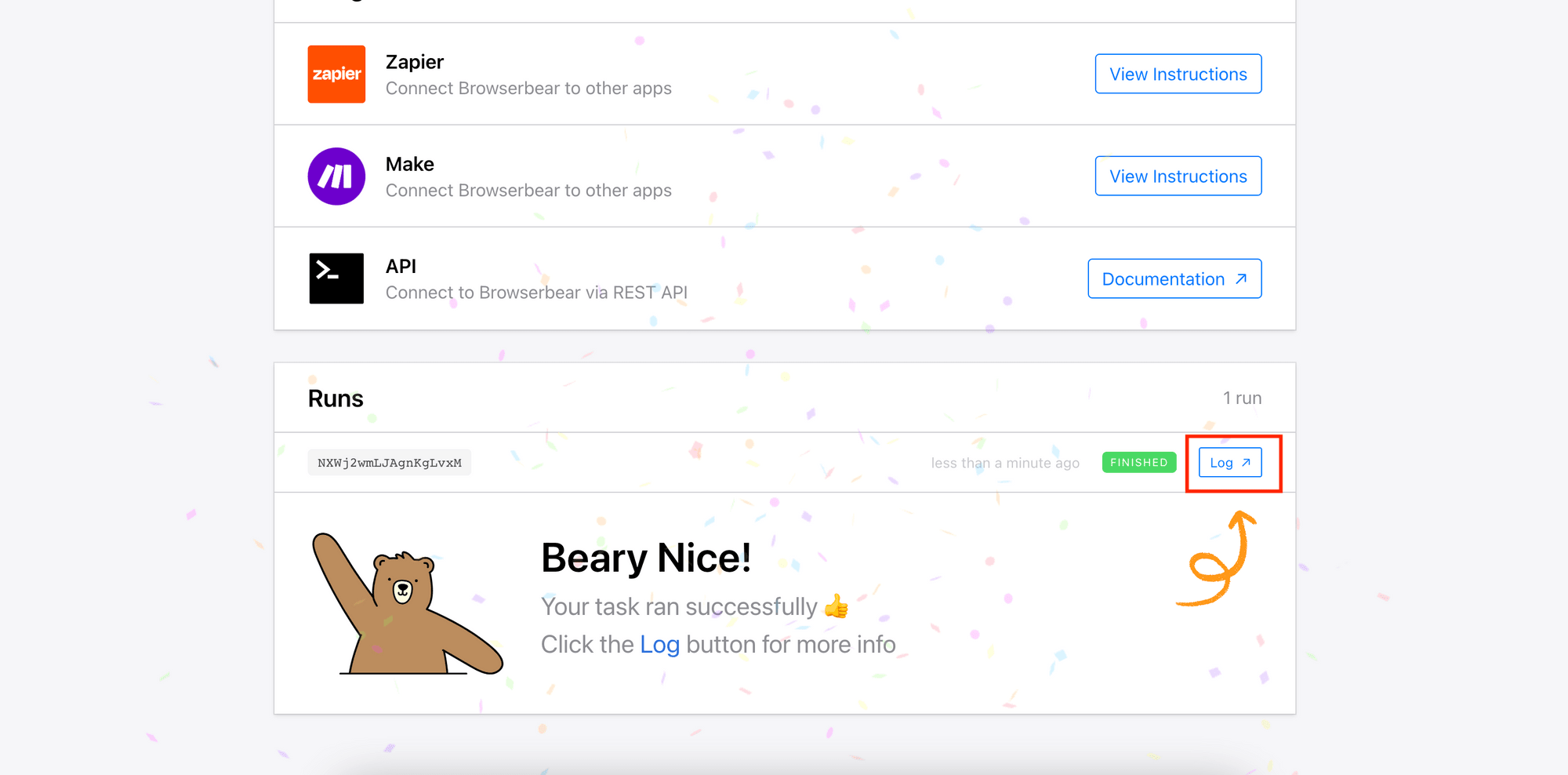
5. View the Log/Result
When the task has finished, you can click on the “Log” button to view the result.
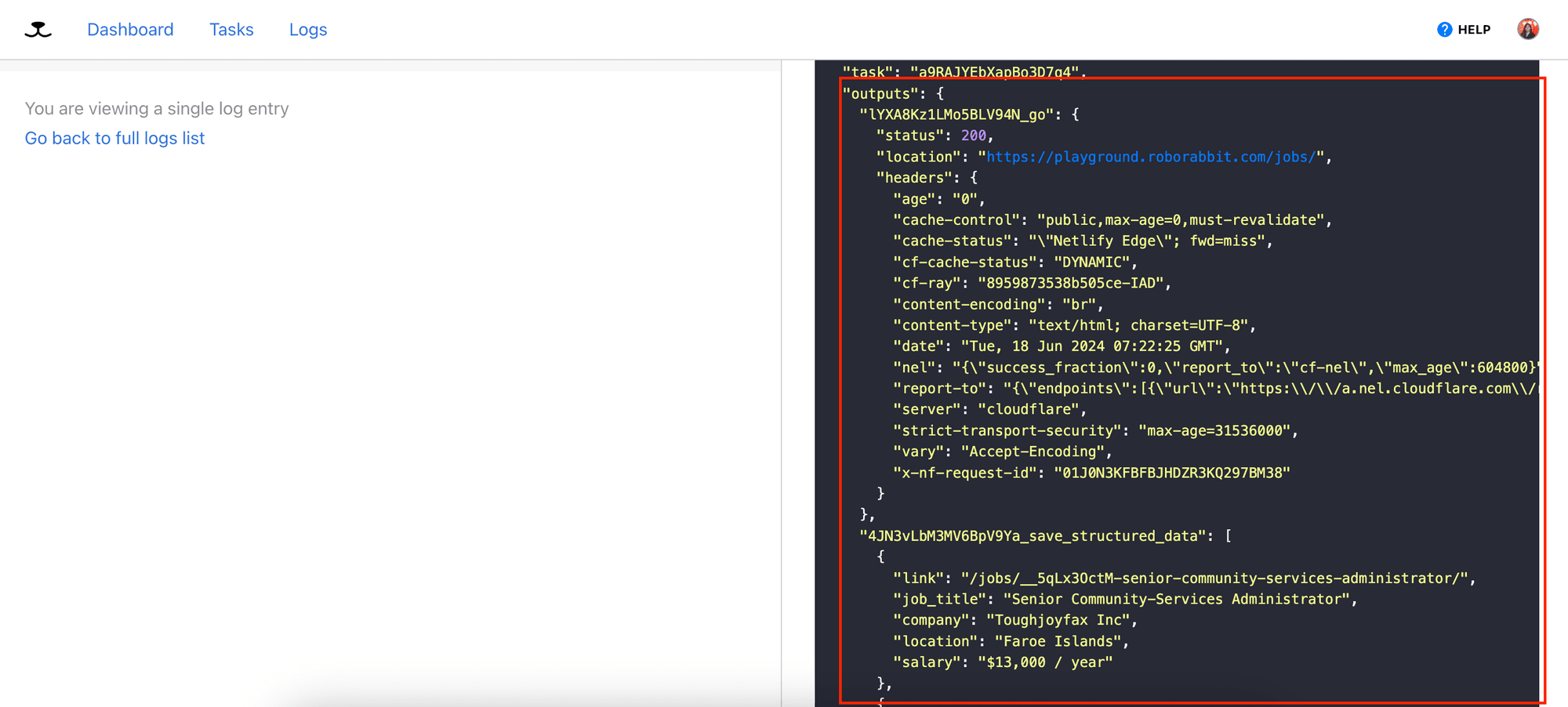
The result will be a Run Object that contains the outputs from various steps in your task. All outputs will be saved in the outputs object and named in the format of [step_id]_[action_name]:
Congrats, you have created your first web scraping task on Roborabbit and run it successfully!
Scraping Multiple Pages
If the website that you want to scrape has a pagination, you can add a few more steps to the task to scrape data from the next page.
Add a new step to the task and select the “Click” action. As before, use the Roborabbit Helper extension and click on the button that brings you to the next page to get the config.
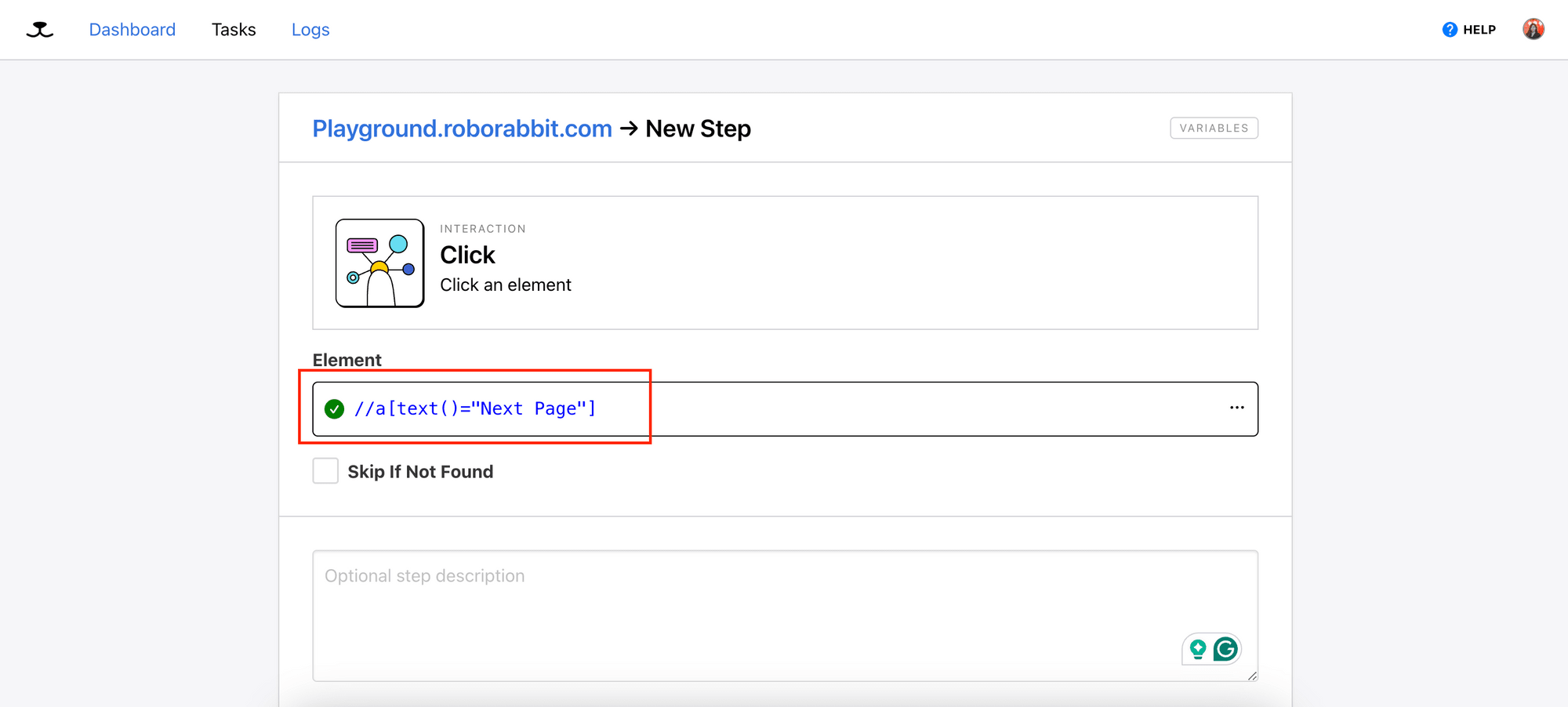
Next, we will add a new step for repeating the “Save Structured Data” step.
Select the “Go To Step” action and choose “save_structured_data”. Then, enter how many times you want to repeat the selected step.
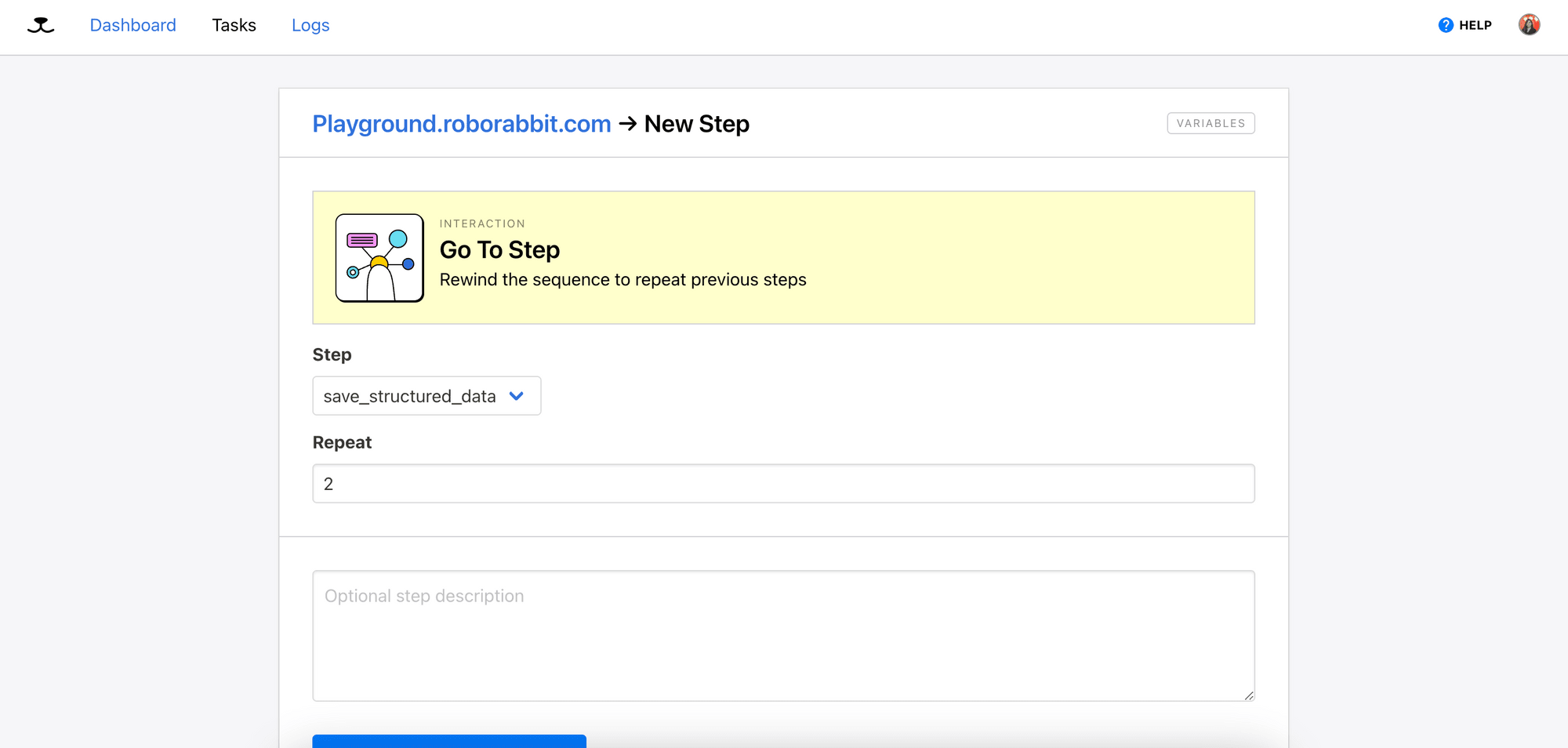
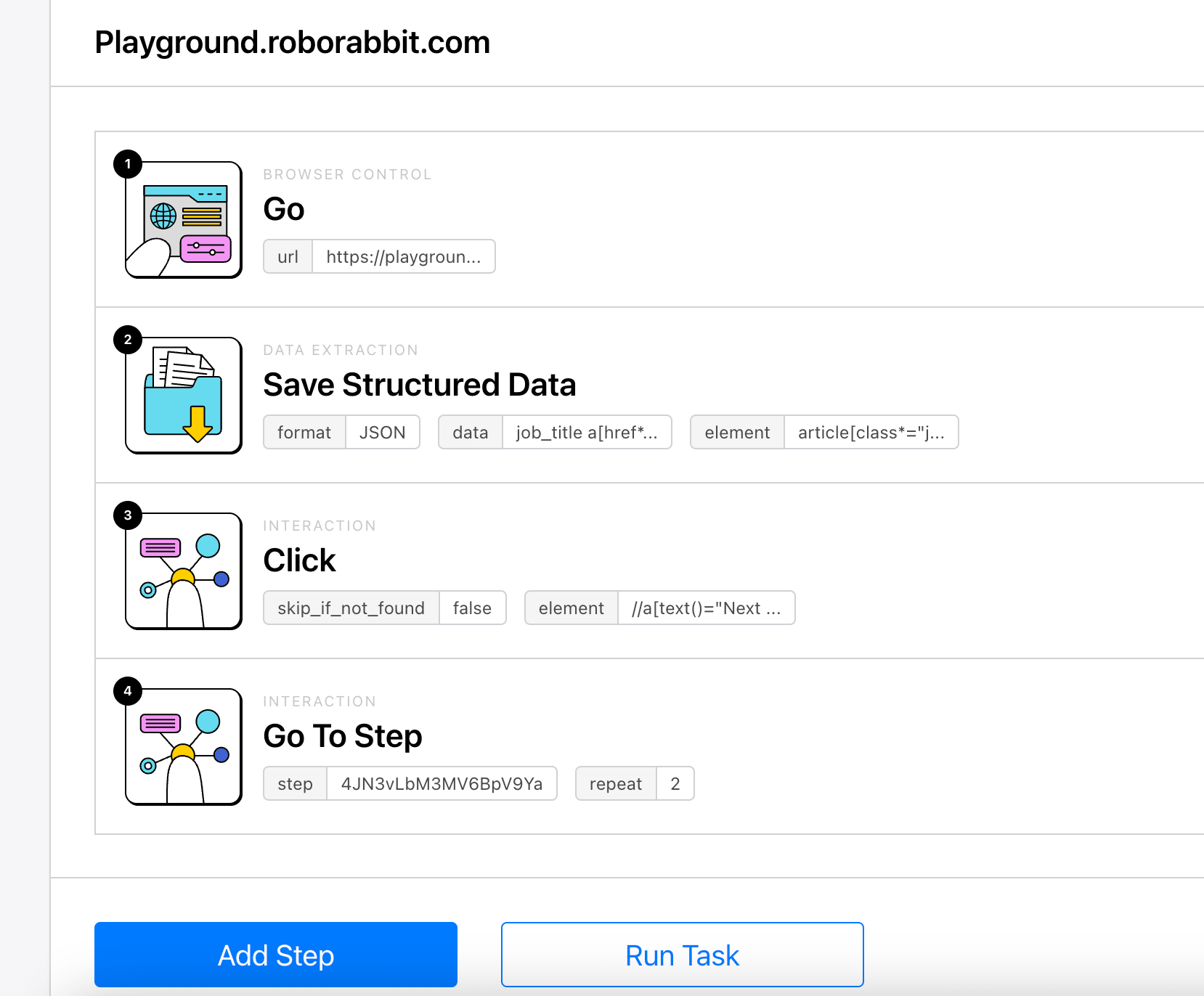
The task will now look like this:
Running the Task Using REST API
Once you have created a task and run it successfully from your Roborabbit dashboard, you can trigger it by making a POST request to the Roborabbit API.
You will need the API Key and Task ID:
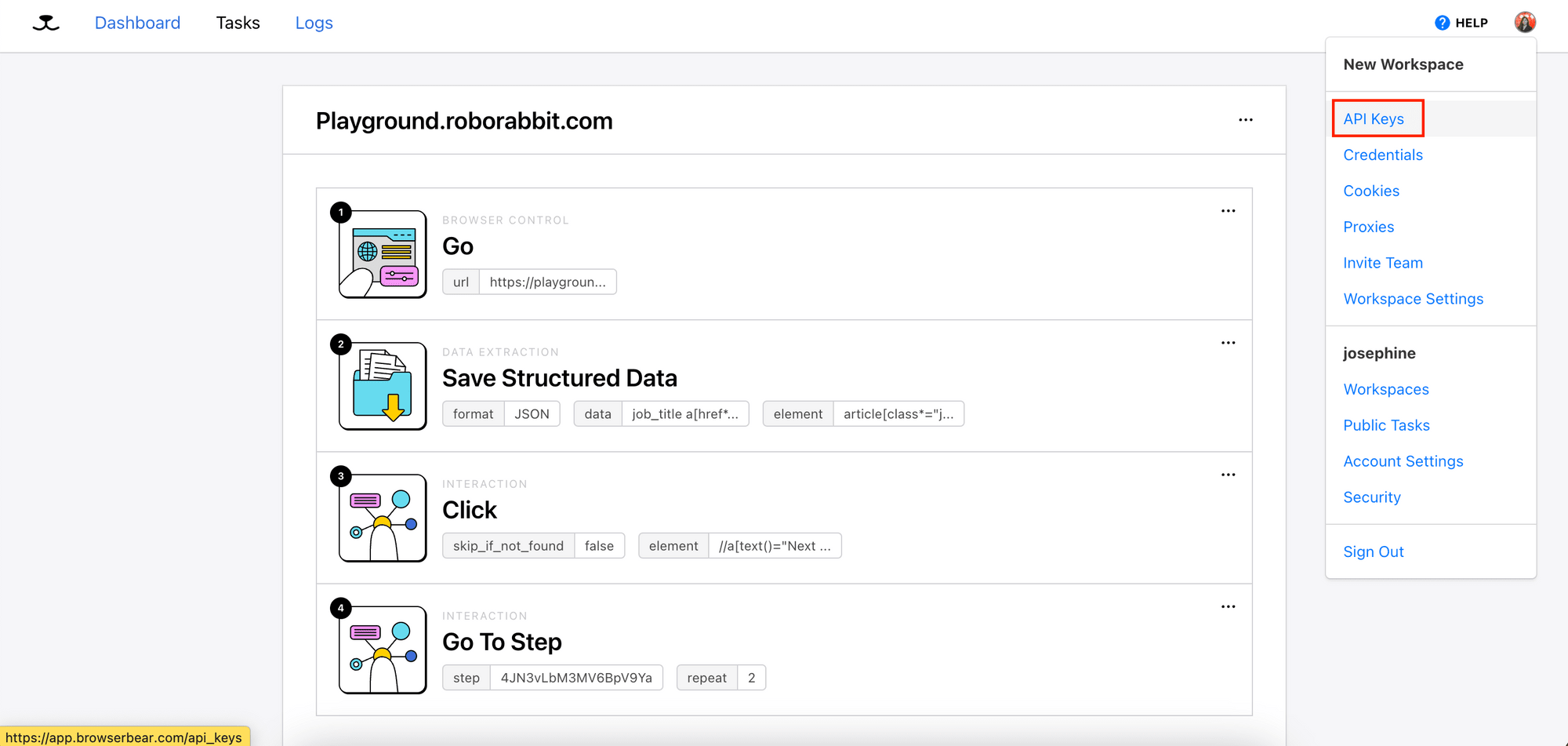
After getting the API Key and Task ID, you can make a POST request to the API:
async function runTask(body) {
const res = await fetch(`https://api.roborabbit.com/v1/tasks/${TASK_UID}/runs`, {
method: 'POST',
body: body
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${API_KEY}`,
},
});
return await res.json();
}
const run = await runTask(body);
The Roborabbit API is asynchronous. To receive the result, you can use either webhook or polling.
You will need the ID of the run to get the result via API. As the result of the ‘save_structured_data’ step will be saved as an array with its name following the format of [step_id]_save_structured_data, you need to get the step’s ID too.
Both of them can be retrieved from the POST request’s response:
{
created_at: '2024-06-18T07:58:00.717Z',
video_url: null,
webhook_url: null,
metadata: null,
uid: 'Oje6ZEm5pa1jQxLMwV',
steps: [
{
action: 'go',
enabled: true,
uid: 'lYXA8Kz1LMo5BLV94N',
config: [Object]
},
{
action: 'save_structured_data',
enabled: true,
uid: '4JN3vLbM3MV6BpV9Ya',
config: [Object]
}
],
status: 'running',
finished_in_seconds: null,
percent_complete: 0,
self: 'https://api.roborabbit.com/v1/tasks/a9RAJYEbXapBo3D7q4/runs/Oje6ZEm5pa1jQxLMwV',
task: 'a9RAJYEbXapBo3D7q4',
outputs: []
}
To get the result, send a GET request to the API:
async function getRun(runId) {
const res = await fetch(`https://api.roborabbit.com/v1/tasks/${TASK_UID}/runs/${runId}`, {
method: 'GET',
headers: {
Authorization: `Bearer ${API_KEY}`,
},
});
return await res.json();
}
const runResult = await getRun(run.uid);
const structuredData = runResult.outputs[`${SAVE_STRUCTURED_DATA_STEP_ID}_save_structured_data`];
This will be part of the /array when you log structuredData:
[
{
job_title: 'Education Representative',
company: 'Wildebeest Group',
location: 'Angola',
link: '/jobs/P6AAxc_iWXY-education-representative/',
salary: '$51,000 / year'
},
{
job_title: 'International Advertising Supervisor',
company: 'Fix San and Sons',
location: "Democratic People's Republic of Korea",
link: '/jobs/_j_CPB1RFk0-international-advertising-supervisor/',
salary: '$13,000 / year'
},
{
job_title: 'Farming Strategist',
company: 'Y Solowarm LLC',
location: 'Poland',
link: '/jobs/ocXapDzGUOA-farming-strategist/',
salary: '$129,000 / year'
}
...
]
🐻 View the full code that shows you how to receive the result using both webhook and API polling on GitHub.
Conclusion
Congratulations! You have successfully learned how to scrape data from a website using Roborabbit. With the steps outlined above, you can easily scrape data from any website with a few clicks and minimum coding. To know about the Roborabbit API in details, refer to the API Reference.
🐻 If you'd like to learn the advanced method of using Roborabbit to scrape a website, continue with How to Scrape Data from a Website Using Roborabbit (Part 2).
