


How to Improve Web Scraping Reliability (7 Tips for Nocoders)
Contents
Web scraping—also known as data extraction—is a powerful way to gather data from online sources quickly. It’s most often used in situations where information needs to be pulled from many data points, sources, and webpages for purposes like market research, competitor analysis, and content aggregation.
You can extract a wide variety of data types with scraping tools, including text, images, and links. What you do with the output is up to you—the data can be routed to different tasks, saved to a database for further processing, or delivered to other stakeholders.
Data extraction is a powerful tool for businesses and individuals. To make the most of it, understanding how to create an effective workflow is crucial. That’s why in this article, we’ll be exploring ways you can improve the efficiency of your web scraping processes.
7 Tips for Efficient Data Extraction
Setting up your web scraping processes to work efficiently is key to using your resources wisely. A poorly set up scraper can cost more money, yield inconsistent results, and result in more work repeating or processing output.
Automated processes aim to save time and improve efficiency by eliminating manual work. Therefore, it’s essential that your data extraction workflow does not create more work than it saves. Streamline your web scraping with some of the following tips:
1 - Set Up Triggers
Probably the simplest way to improve the efficiency of your web scraper is to set it up to run as needed. Aside from saving you the effort of having to manually run your task, triggers improve accuracy by ensuring data is collected at the correct point in time.
Triggers can be both time and action-based, and they can be set up various ways without code. You can trigger an action from a database like Airtable, a workflow automation tool like Zapier…

…or even directly in Roborabbit.
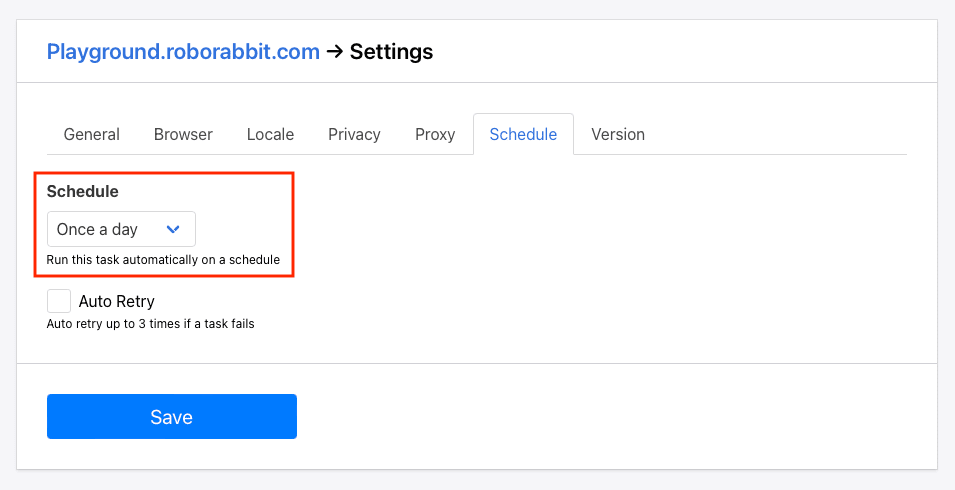
You can also write a custom script that uses conditions to launch the task.
The best trigger depends on your goals and the apps you plan to use. Consider data extraction frequency and usage to set up an efficient trigger that meets your needs while avoiding unnecessary extraction.
2 - Identify Data Points Accurately
No matter what tool you use, a key part of setting up a browser automation is identifying the elements you want to interact with. The more accurately an element is selected, the more reliably you will get the expected automation output.
There are several methods you can use to identify a webpage element: XPath, CSS selectors, JS selectors, and so on. Roborabbit’s Helper extension generates config for a selected element.
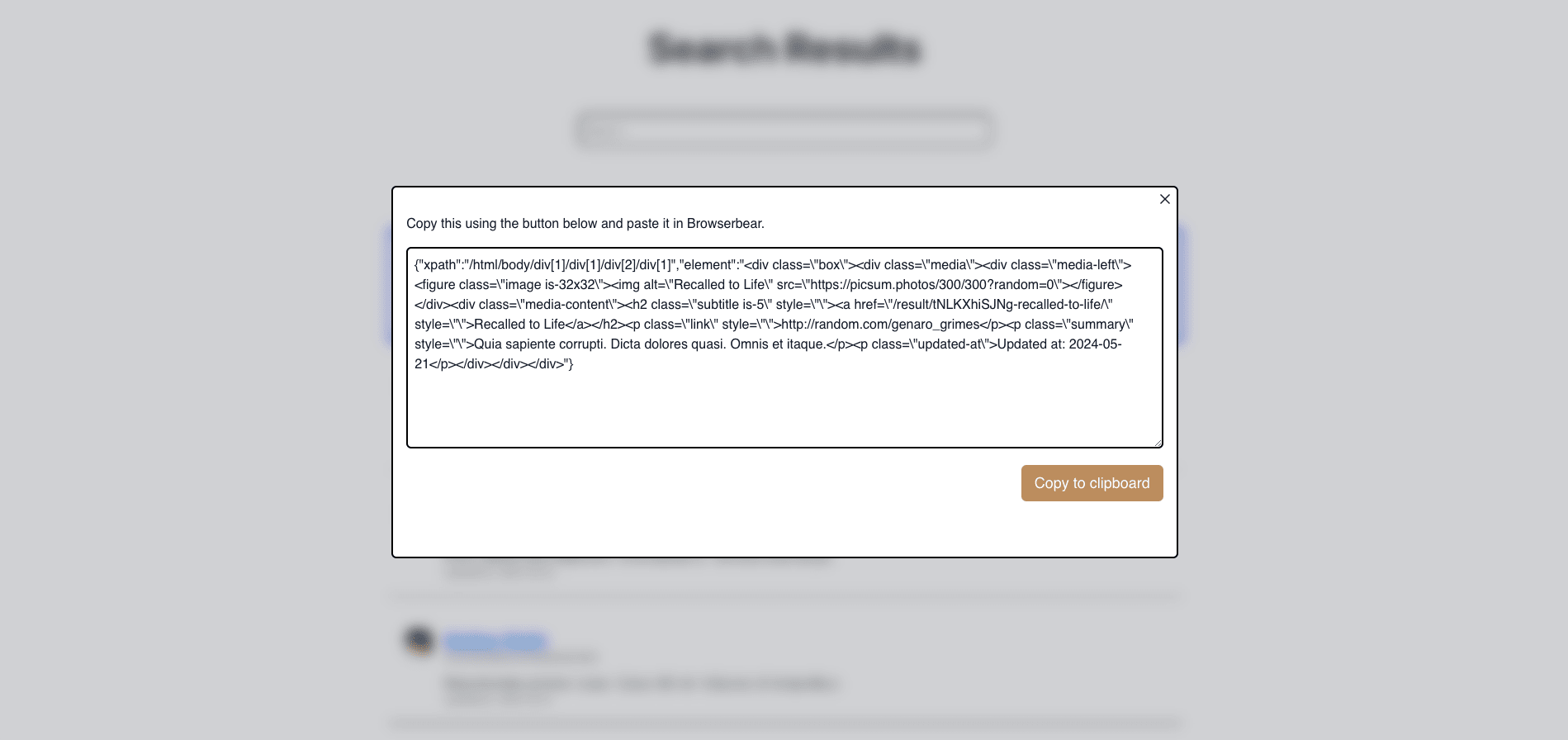
Even so, it doesn’t always produce exactly what you need. Some use cases may call for identifying a class or group instead of a specific item.
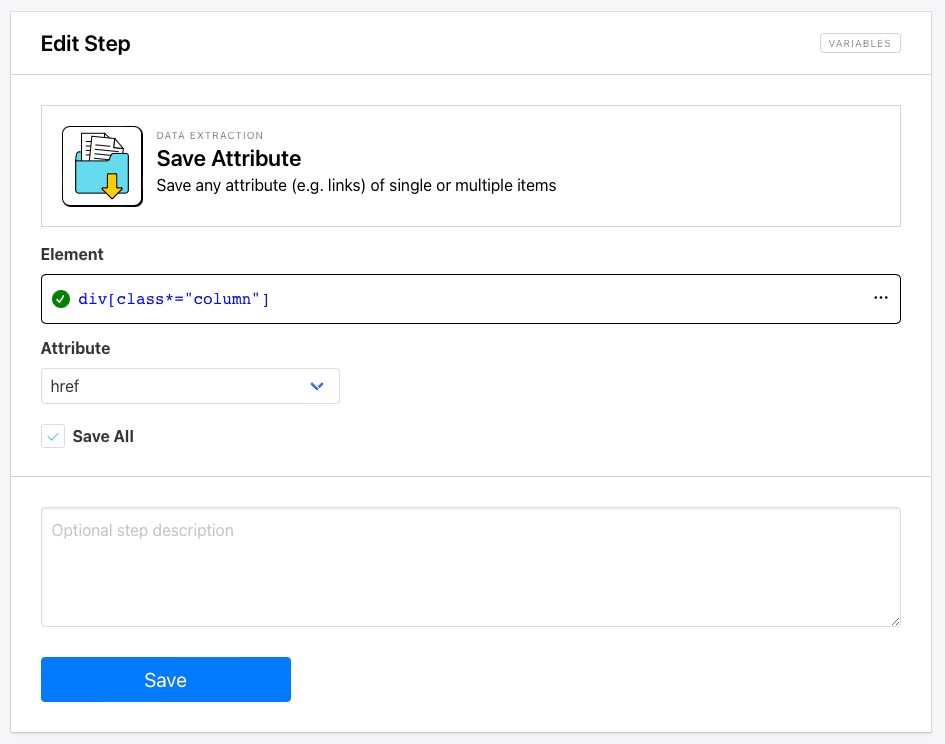
Using the most accurate selector will minimize mistakes. It’s wise to test a task several times with different sample data in order to ensure you get the output you expected. You may find Helper config to be best in some cases, and XPath to be better in others. It all comes down to what you’re looking to scrape.
🐰 Hare Hint : Roborabbit’s task builder helps to recommend what might be the best selector for element you’re looking to identify. This is a great starting point, but you can also choose something else or add custom config if it better suits your needs!
3 - Implement Error-handling Strategies
Sometimes automations don’t work as expected. Whether due to changes to site structure or connectivity issues, it’s important to have a plan in place for when a task fails. This usually starts with alerts that prompt you to check in and see whether the automation needs your attention.
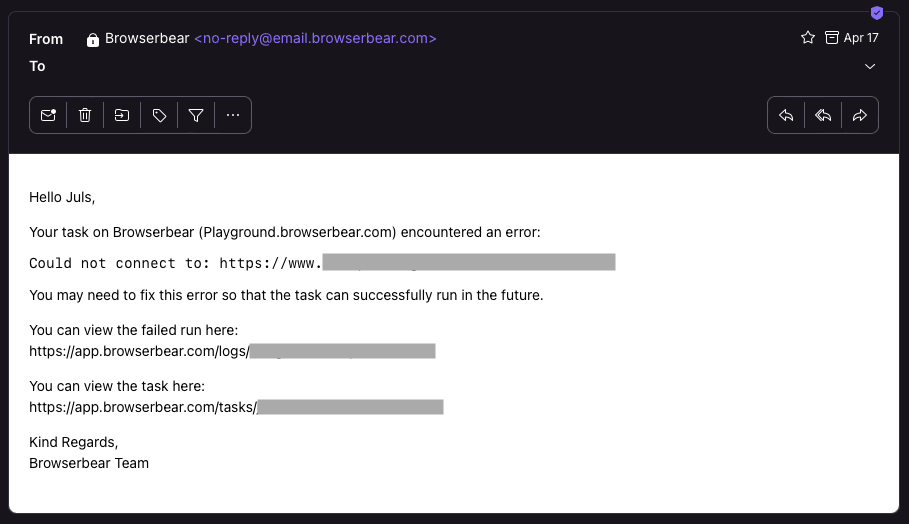
To prevent task failures, consider setting them up to automatically retry if they don't complete successfully. This enhances the reliability of your workflow and reduces the error notifications you might otherwise receive. Some issues—like server connectivity—are sometimes easily resolved by re-running the task and don’t require your personal attention.
🐰 Hare Hint : Roborabbit sends you email notifications when a task fails. You can also set a task up to auto-retry for a maximum of three times.
4 - Scrape Multiple Pages at Once
Some use cases call for extracting data from multiple pages. With Roborabbit, this is fairly simple with a consistent site structure: you can interact with “next” buttons to navigate to the following page, then extract from as many pages as you need. However, the data you need isn’t always on the initial page being scraped. This is where looping iterations come in handy.
Combining a link extraction step with a structured data extraction step creates a loop where each link is accessed, then the specified information scraped until the entire set is completed.
If your needs call for scraping multiple pages, setting up a looping iteration is much more efficient than manually running the task over each new link.
🐰 Hare Hint : Learn more about creating looping iterations with Roborabbit at our Knowledge Base and Academy.
5 - Clean and Process Data as It is Scraped
Data often doesn’t meet formatting needs at point of extraction. Depending on how the source site is structured, the information can be excessive, incomplete, or poorly organized.
There are several ways you can clean and process data at different points in your workflow, such as by using your database, workflow automation, or web scraping tools. Carefully laying out your tools and choosing when and how to format data results in cleaner, more accurate output.
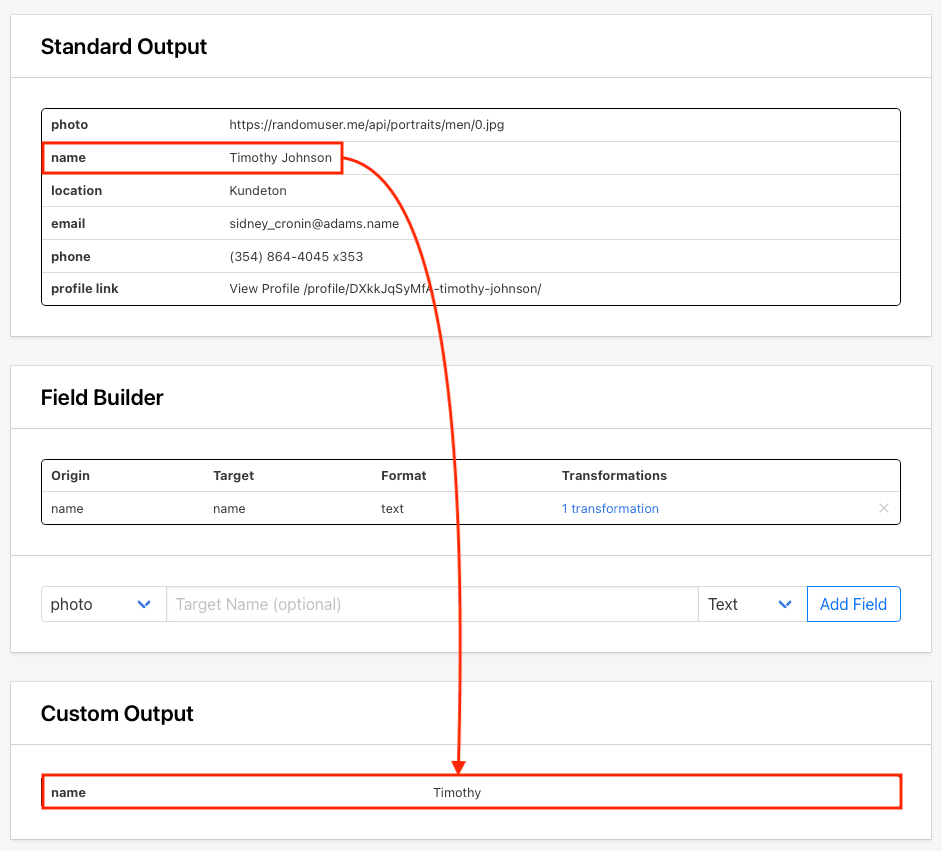
Complex data manipulation may call for database transformation, but small formatting tweaks here and there can be promptly handled using data massaging features built into some extraction tools. Cleaning data as it is scraped reduces the complexity of your storage solution and can be more efficient.
🐰 Hare Hint : To clean data extracted using Roborabbit, create a custom JSON feed and use the field builder to set up the transformations you need.
6 - Employ Anti-blocking Measures
Site blocking is a fairly common occurrence in web scraping, and it can both prevent you from acquiring the data you need and waste your resources on failed task runs. Putting anti-blocking measures in place improves the chances of successfully gaining access.
Anti-blocking measures look different from one site to another, and it will often evolve along with website security measures. You can employ techniques like:
- Rotating IP addresses
- Adding delays
- Implementing CAPTCHA solvers
The solution can be one or a combination of things. Employing anti-blocking measures enhances the efficiency and reliability of your web scraping processes. That said, sites continually update their anti-scraping measures and you will often have to update your methods in response.
7 - Think As a Human
Suspicious bot activity will only increase the chances of being blocked, so setting up tasks to appear human can improve their effectiveness, even if each run isn’t as streamlined as it could have been.
Some ways to build a more human-like automation are:
- Using cookies
- Using custom proxies
- Simulating natural browsing behavior
- Randomizing user agents and fingerprints
Trial and error will be necessary as every use case is different. One or a combination of these things may enhance the likelihood of your automation going undetected and prevent disruptions in the scraping workflow.
🐰 Hare Hint : Toggle Roborabbit’s Use Stealth setting on to randomize user agents and fingerprints, which reduces the chances of being flagged as a bot.
Increase the Chances of Successful Data Extraction Runs
Ensuring the success of your web scraping efforts involves a combination of technical strategies and mindful practices. By implementing the tips mentioned above, you can significantly improve the efficiency and reliability of your data extraction workflows.
Remember: web scraping is a valuable tool, but it's essential to approach it strategically to avoid potential pitfalls. Continuous monitoring and fine-tuning of your processes will help you stay ahead of any challenges that may arise.
By staying proactive and adaptable in your approach to web scraping, you can harness the full potential of this technology to enhance decision-making, drive innovation, and gain a competitive edge in your industry.
