


How to Debug Your Roborabbit Tasks (A Nocode Guide)
Contents
When you’re working with dynamic websites, there’s always a chance that your automated tasks will malfunction. So many factors are at play—server connection, structural updates, and safety measures implemented by websites, not to mention the way your scraping task is set up. You will inevitably run into some issues while setting a task up for the first time and while maintaining it over time.
While a whole host of things can go wrong, there are a few issues that crop up a bit more frequently with automated browser tasks like web scraping. Some of these are:
- Network connectivity : Internet or server connectivity issues can cause browser tasks to fail.
- Missing, incomplete, or incorrect data : Inaccurate identifiers, dynamic page structure, or scraper malfunctions can result in missing, incomplete, or incorrect extracted data.
- Anti-bot measures : Some websites employ protective measures to discourage scrapers, which can be challenging to get around.
Bulletproofing your task is a tall order, but there are things you can do to reduce the chances of failure and troubleshoot inconsistent tasks.
Debugging these issues can be challenging, especially for those unfamiliar with browser automation tools. That’s why in this article, we’ll explore some common issues Roborabbit users might encounter and what to do when things go wrong.
How to Troubleshoot a Failed Task
Tasks can fail for a variety of reasons. Even those that show successful task runs may yield unexpected results and need troubleshooting. Before you can fix the issue, you need to understand what went wrong. There are a few ways to do this:
Check for an Error Code
One of the first things to do when debugging a task is to check for an error code. This can give you a clear solution in some cases, and in others, it will rule out what isn’t an issue.
Here are the status codes that the Roborabbit API might return:
| Status Code | Main Description | Explanation |
|---|---|---|
| 202 | Accepted | Your request is has been accepted for processing |
| 200 | OK | |
| 400 | Bad Request | Your request is invalid. |
| 401 | Unauthorized | Your API key is wrong. |
| 402 | Payment Required | Your have run out of quota. |
| 404 | Not Found | The specified request could not be found. |
| 429 | Too Many Requests | Slow down! |
| 500 | Internal Server Error | We had a problem with our server. Try again later. |
| 503 | Service Unavailable | We're temporarily offline for maintenance. Please try again later. |
You can find status updates in both the overview and response body of task runs:
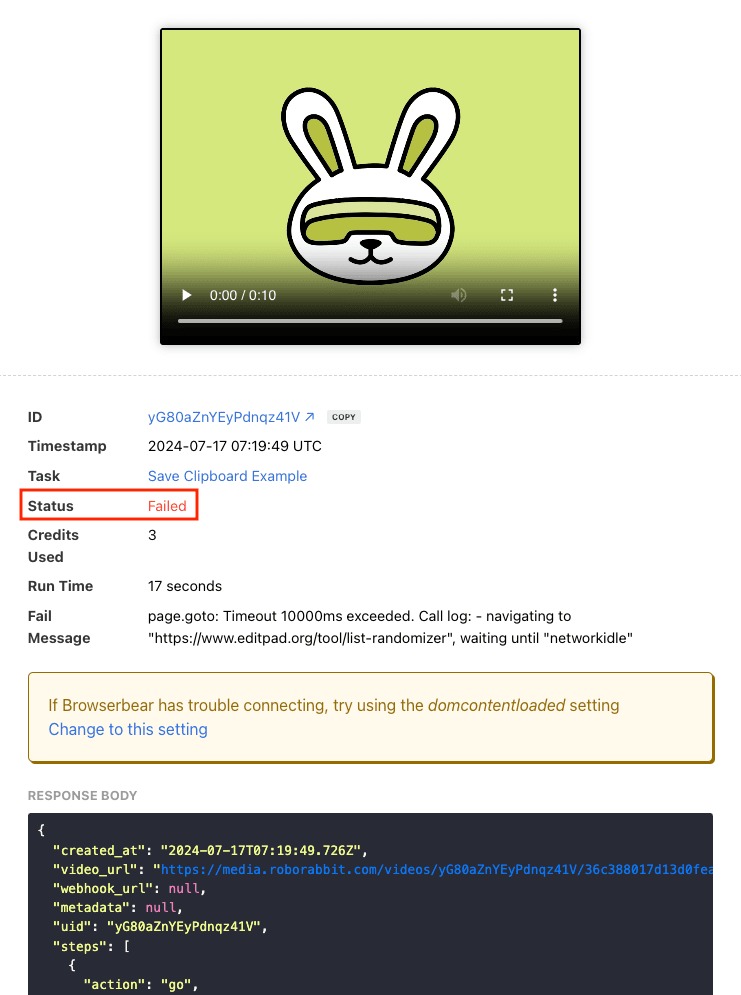
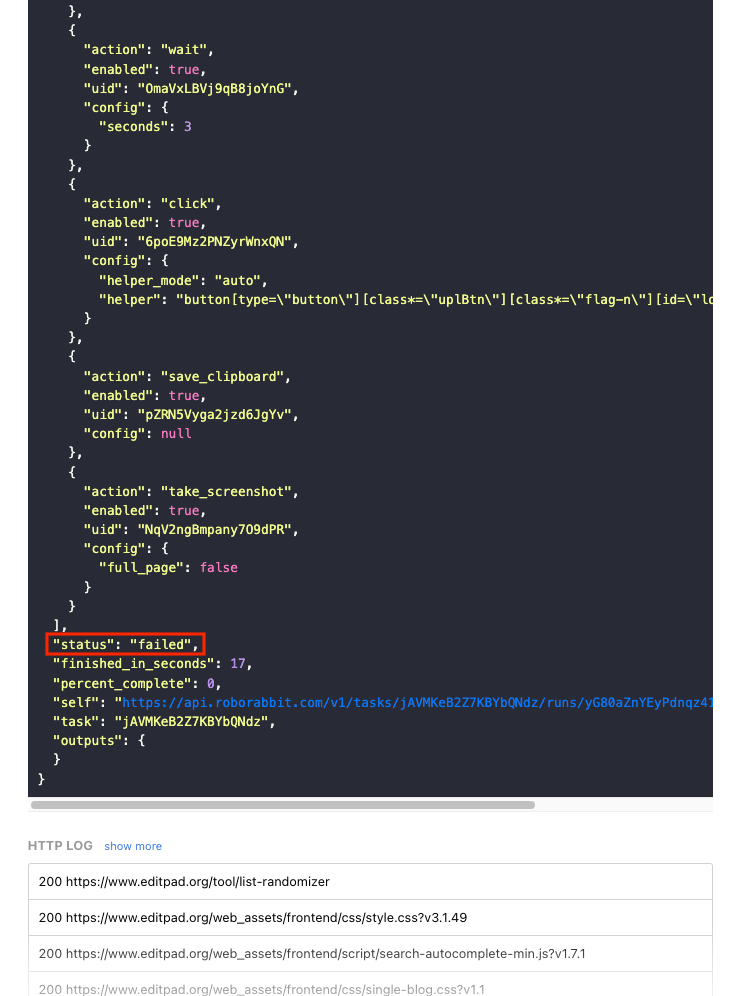
The console log returns status codes and helps you identify exactly when a task acted unexpectedly.
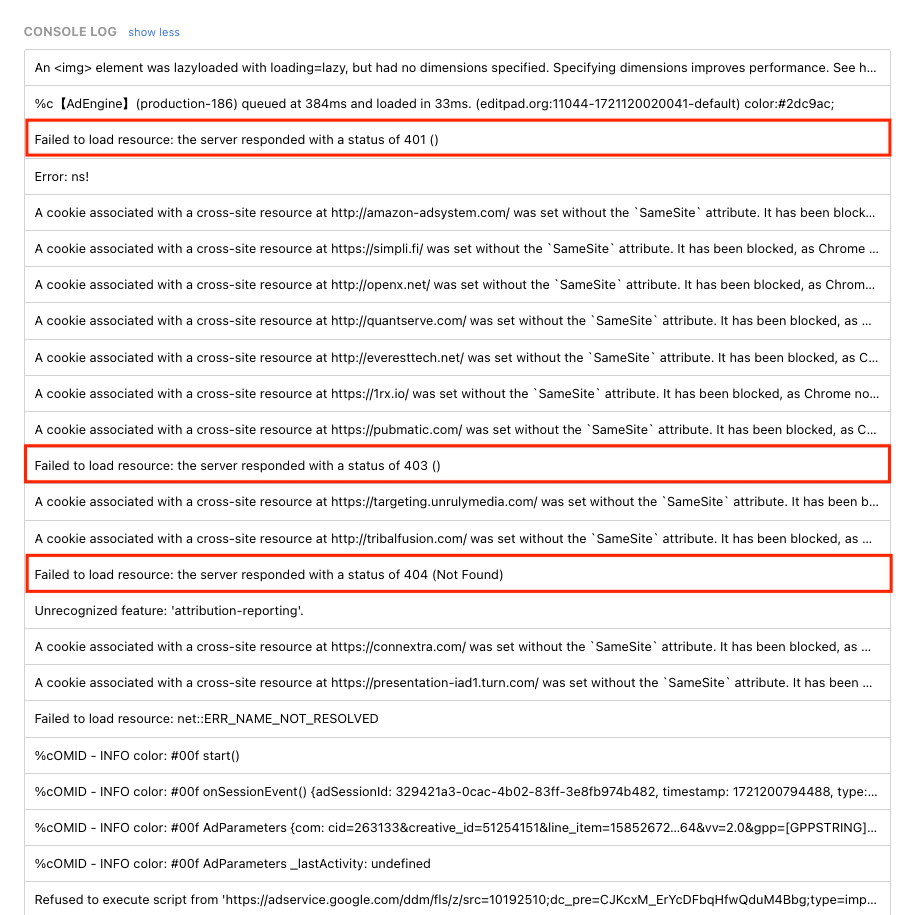
Some errors—like 401 and 402—are very straightforward and will need to be addressed before the task can proceed. Others—like 400—will require more troubleshooting.
Read the Fail Message
When tasks fail, output logs also contain fail messages which can be helpful for tracing the root of the issue.
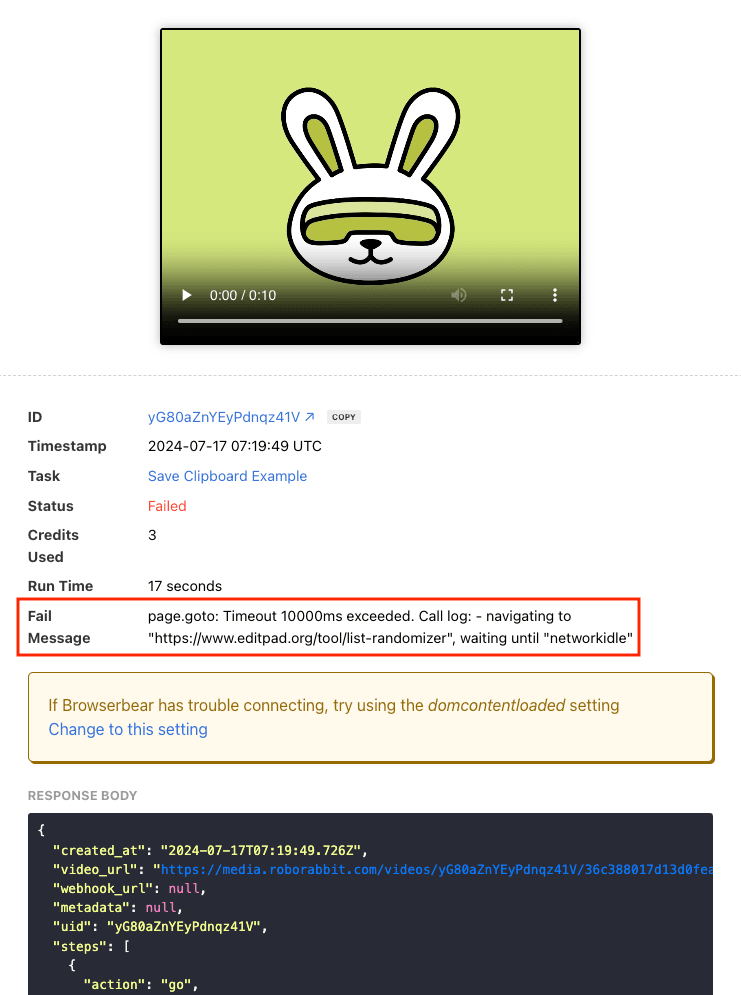
Some examples of messages you might encounter are:
- locator.count: Unsupported token "{" while parsing selector “{step_xxxxxxxxxxx}”
- No elements found for step 3
- locator.fill: Error: Element is not an <input>, <textarea> or [contenteditable] element
- Could not connect to: https://examplewebsite.com/
These can help you identify the issue and make the necessary changes to your task.
Watch the Log Video
Roborabbit creates a video of each task, allowing you to observe the process and hone in on issues. You can view this in Logs.
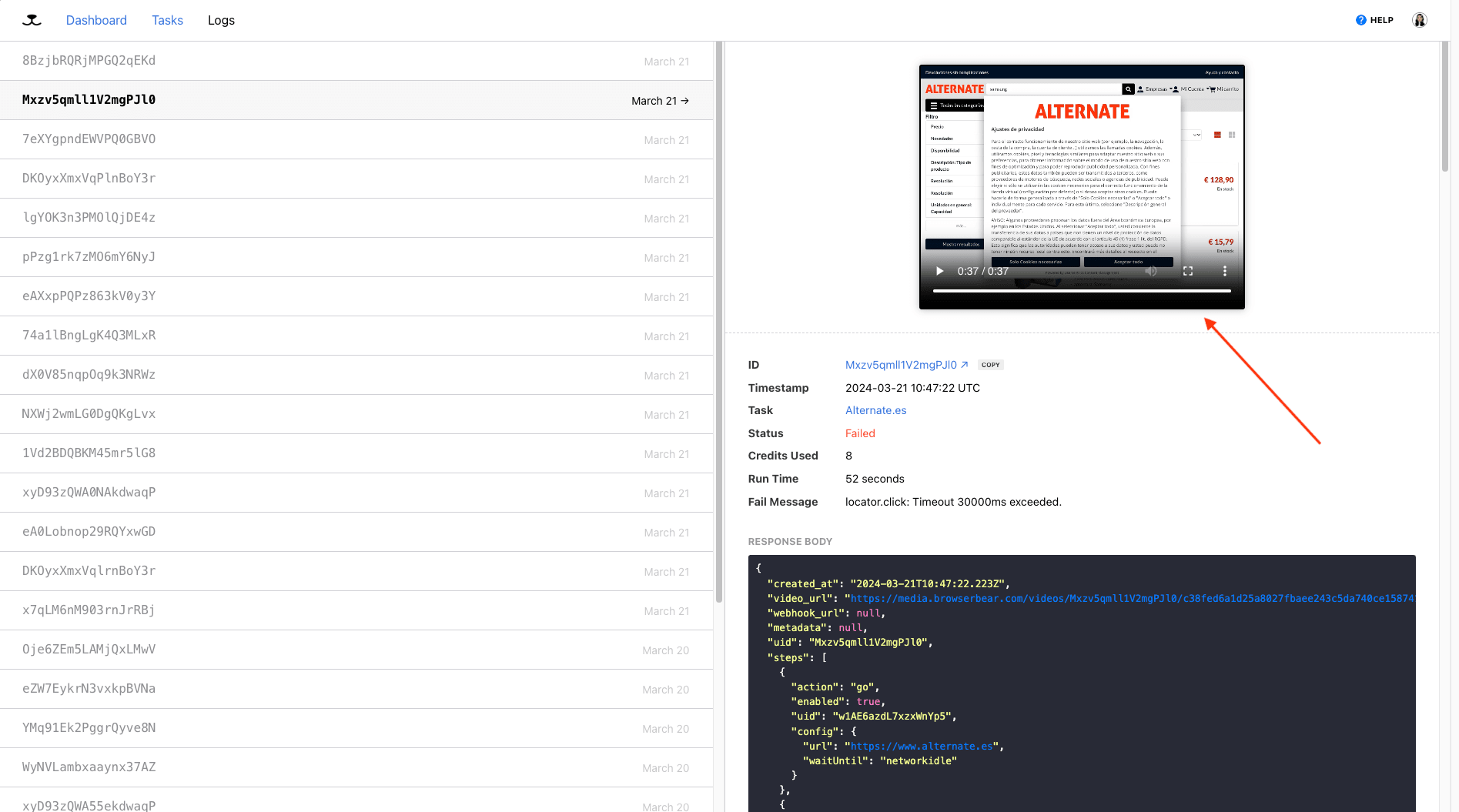
Often, the video will indicate things like connection issues or inaccurate element selection.
Common Task Issues and How to Solve Them
Since automating a browser task is unique to every site, troubleshooting an issue isn’t always easy. But there are a few common problems that many people run into. Knowing where to start while troubleshooting can help you make adjustments without wasting too much time. Let’s go over a few problems you might encounter:
Problem #1: The Target Website Isn’t Loading
An issue loading your starting URL can be recognized by a task failing and yielding an error message. You might watch task video to find the page failing to load, showing a block message, or timing out entirely.
One potential cause of slow site loading is poor connectivity. The task video might show the page loading very slowly due to server performance, internet connection, or other factors. Retrying the task might resolve the issue. You can proactively reduce the impact of connectivity issues by setting your task to re-run if it fails initially.
Another potential explanation for website load failure is anti-bot blocking measures. This can yield an error message, and the task video might show a site loading, only to halt before browser actions can take place. You can improve your chances of gaining access by activating stealth mode, adding a CAPTCHA-solving step if necessary, and implementing rotating proxies.
Hare Hint 🐰: While there’s no foolproof way to gain access to sites 100% of the time, you can certainly improve your chances by learning to web scrape without getting blocked.
Problem #2: The Task is Timing Out
A recurrent timeout issue an be recognized by a fail status and error message that might look something like locator.click: Timeout 30000ms exceeded. Watching the video might show a site loading, then all or some actions taking place before the task stalls and fails to complete.
A task that shows signs of loading but times out before it is completed might be affected by factors like server performance, page size, network latency, or the amount of JavaScript and other resources that need to load. If this is the case, you might be able to increase chances of success by increasing the task’s timeout and/or adding wait actions between steps. If the images on the webpage are unimportant, disabling them in your task settings can also reduce load times.
Hare Hint 🐰: Learn more about data extraction on Roborabbit by reading this article.
Problem #3: Scraped Elements are Missing or Incorrect
While checking the output log of a completed data extraction task, you may see some elements missing, incomplete, or incorrect. This can be the case even when the status indicates the task was successfully finished. Reviewing the video can help you pinpoint where in the process extraction failed, but this should also be quite clear in the output and console logs.
Inconsistent data scraping is often caused by inaccurate selectors in your configuration. The selectors might be too specific, too general, or simply wrong. Additionally, the structure of the target website can affect compatibility with Roborabbit, such as when the desired element is within an inline frame. Inspecting the site structure can determine whether this is the case.
There are also cases when scraped elements are incomplete due to an error in the way looping is set up. If you’re scraping multiple pages or looping through links, double check whether your structured data steps are set up correctly.
Hare Hint 🐰: Setting up paginating or looping tasks can help you gather large payloads of data in a single task run.
If your data extraction task suddenly stops working correctly, it's likely due to changes in the website's page structure. In such cases, you'll need to update your selectors to match the new page layout. Closely monitoring your tasks and updating them as needed is the best way to ensure reliable data extraction over time.
There are, of course, situations where output just isn’t reliable due to an inconsistent site layout. This is not something a different selector can solve and will probably have to be addressed during data processing.
Problem #4: The Target Website is Loading but No Browser Actions are Taking Place
The first step of any browser task is to load a destination site, but there are times when that’s as far as it goes. The output log and video might show movement through the site, but no interaction and data extraction taking place. Depending on the task, the status could show as Finished or Failed.
Actions not being executed as expected could be due to inaccurate selectors or Roborabbit not being able to interact with your desired element. You can use the Helper extension to ensure config is correct and inspect the site to better understand structure. The HTTP and console logs will also reveal which specific actions are failing.
Another possible explanation for action failure is timing. If the page takes too long to load or render certain elements, your task may attempt to interact with elements before they are ready, causing the steps to fail. Adding a delay or extending timeout might resolve the issue.
Troubleshooting Browser Automations
Debugging automated browser tasks can be a challenge, but with the right troubleshooting approach, you can get to the root of the issue and get your Roborabbit tasks running smoothly again. By checking for error codes, reviewing fail messages, and watching the provided video, you can quickly identify what's causing the problem. And being familiar with some of the most common issues, like website loading failures, timeouts, missing data, and failed browser actions, will help you know where to focus your troubleshooting efforts.
The key is to stay patient and methodical. Automating web interactions is complex, and there will always be some unpredictability involved. But by understanding your tools, monitoring your tasks closely, and making incremental improvements, you can build robust and reliable browser automations that save you time and effort in the long run.
Remember: the Roborabbit team is also here to help if you get stuck. Don't hesitate to email [email protected] if you need additional guidance on troubleshooting your tasks. With a better understanding of your needs and the Roborabbit’s capabilities, you'll have your workflows humming along in no time.
