


How to Automatically Save Images with Roborabbit
Contents
The ability to quickly and efficiently extract images from websites can be incredibly valuable in different situations. Whether you’re a researcher gathering visual data, a marketer curating content for social media, or a developer archiving images on a long-term project, having a reliable way to automatically save images can save you time and effort.
Browser automation tools like Roborabbit offer a powerful solution, allowing you to programmatically navigate websites, identify and extract relevant images, and save them for later use. This can be useful for use cases like:
- Collecting a dataset of product images for e-commerce analysis
- Downloading illustrations, icons, or other visual assets for a design project
- Capturing screenshots for software documentation or app testing
This guide will explore several methods for leveraging Roborabbit's image extraction capabilities. We'll cover techniques such as saving image source links, taking screenshots, and downloading files directly. The best approach will depend on your specific use case, so we'll also discuss the considerations to keep in mind.
4 Ways to Extract Images with Roborabbit
You can use different techniques to save data automatically, and the best method depends on your desired output and the website you’re working with. Ultimately, the goal is to obtain direct links to the images you need.
You can store these image links as-is for later use. Alternatively, expand the automation by uploading and managing the images as files in a storage system of your choice.
But before we get to image management and storage, let’s explore the methods of automatic image extraction.
Option #1: Save Image
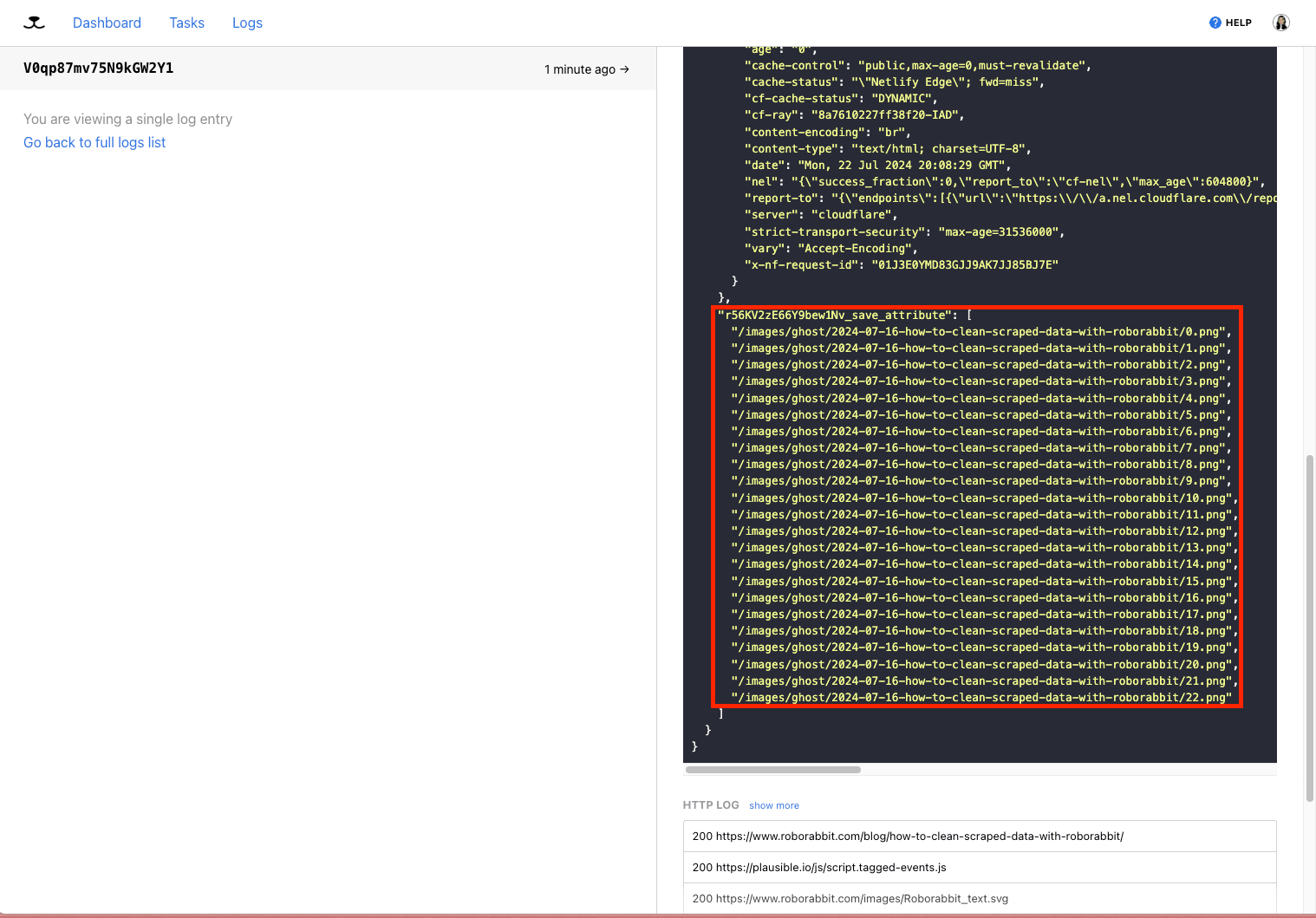
The most straightforward way to extract photos is by using Roborabbit’s Save Image action. This action can extract one or multiple image links from the area you select. You can target a specific element containing a single image, or use a more general identifier to capture all images at once.
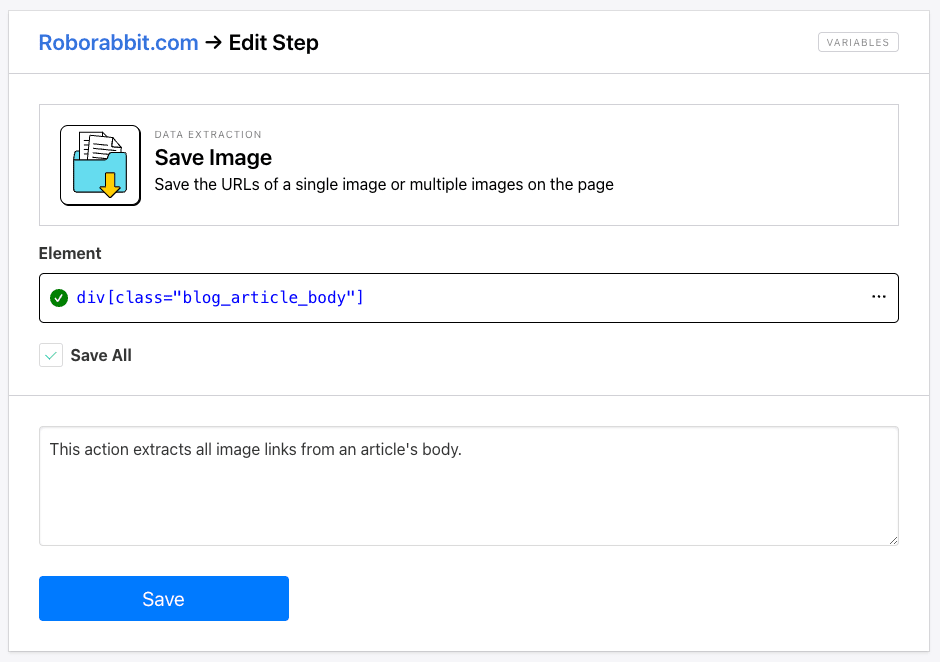
This action delivers output in the form of links, which you can view from the Log.
Since the images are hosted on the destination site’s servers, consider the importance of longevity in your use case. If you require archiving or long-term access, it may be better to host the images yourself. Fortunately, this method allows you to extract the full-resolution image links, ensuring quality is preserved.
Hare Hint 🐰: Depending on your destination site’s structure, the data may need some cleaning before it is ready for use.
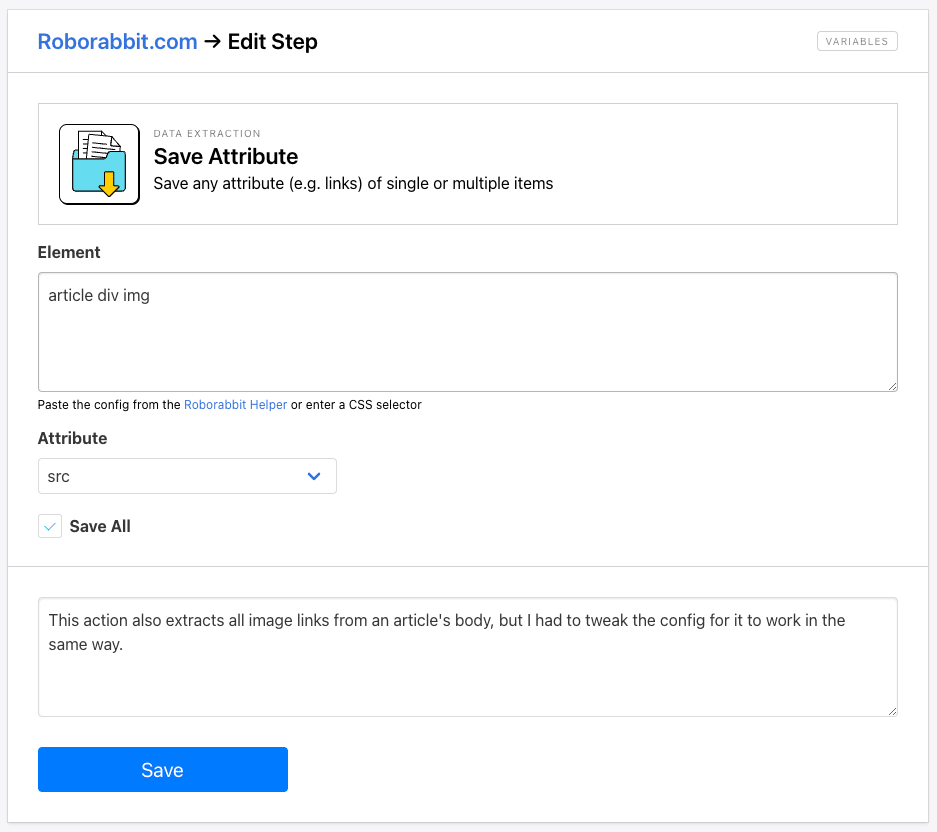
Option #2: Save Attribute
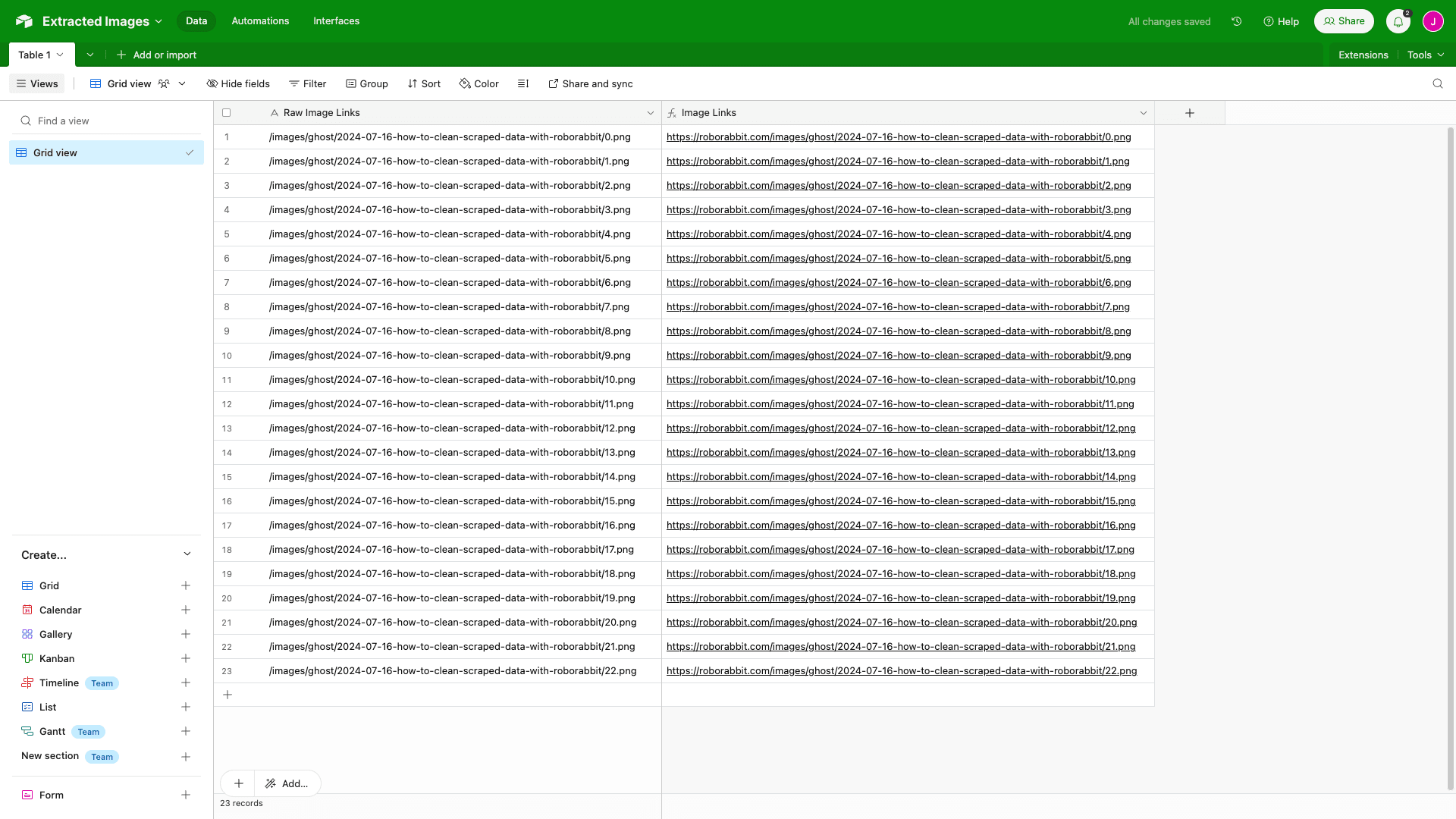
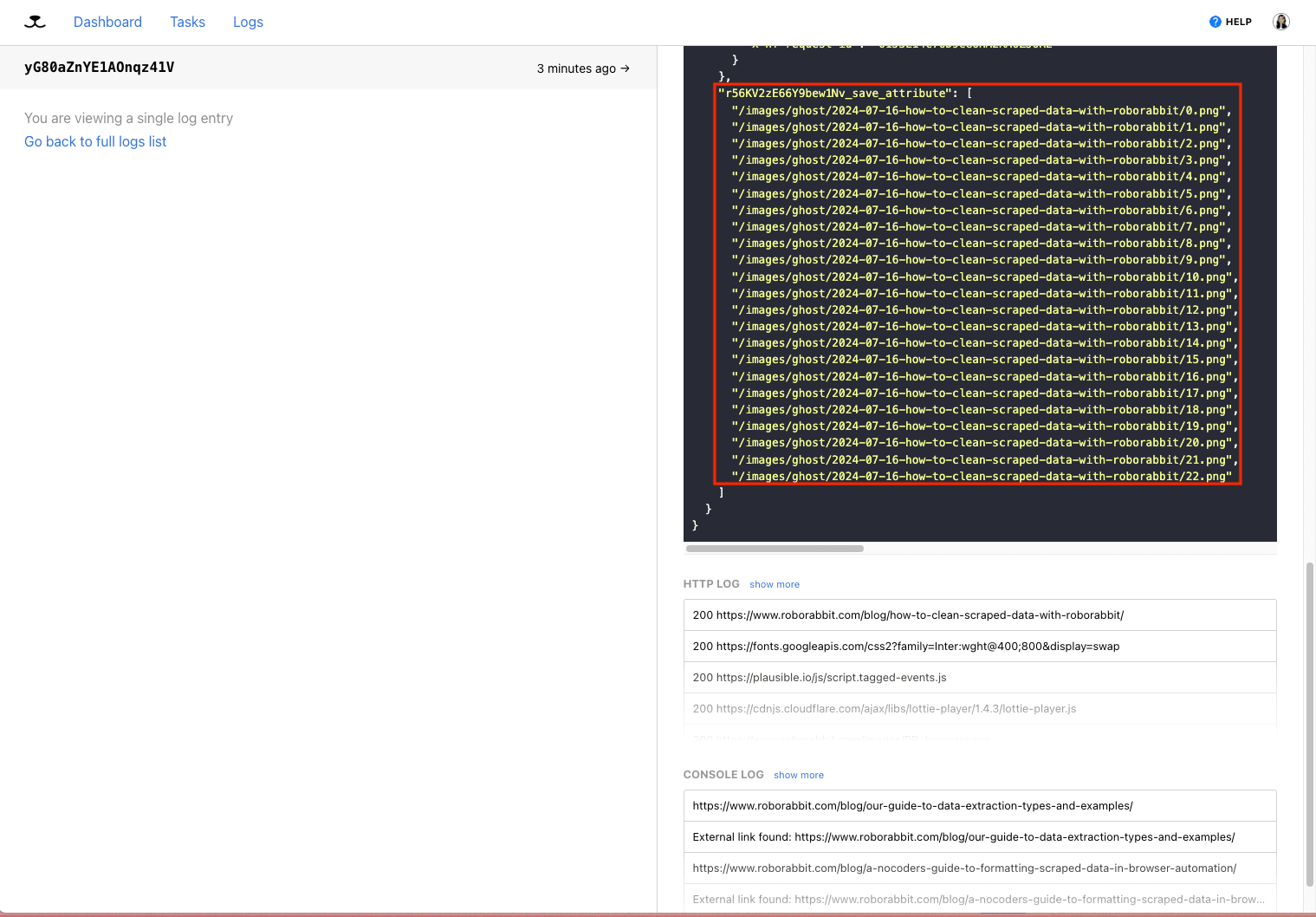
The Save Attribute action is similar to the previous option. It allows you to scrape one or multiple attributes of elements within the selected area. The key difference is that Save Attribute lets you choose from a list of attributes. Since the action doesn’t explicitly target images, you might have to tweak the config to include this information. Otherwise, the setup process is identical and should produce the same results.
Viewing log output should also reveal links to the images you need.
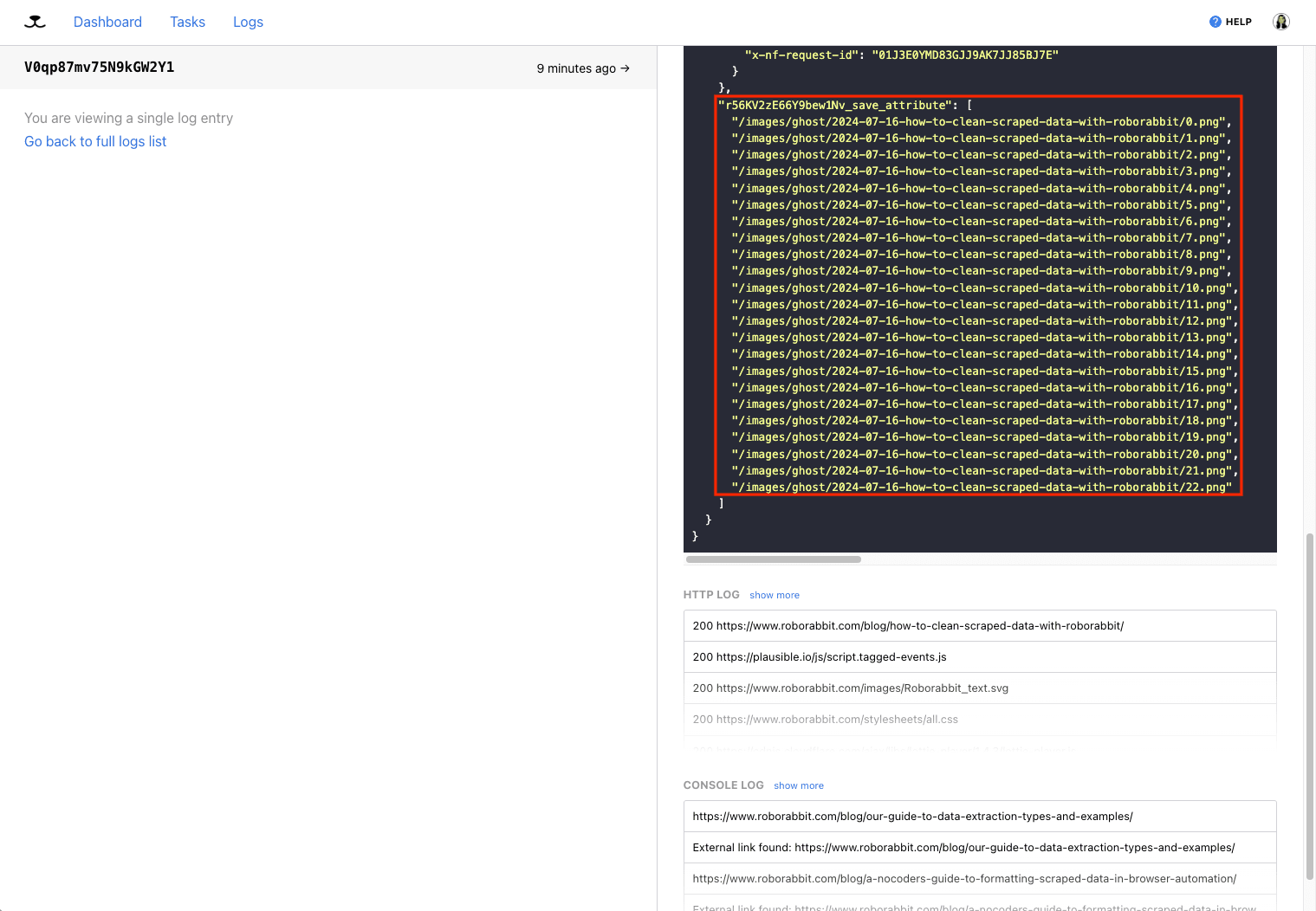
Just like with the Save Image action, you can use this to extract full-resolution links and maintain original quality. However, you may want to add a more durable storage step to your automation.
Hare Hint 🐰: The
srcattribute will most often be the type used for extracting images, but there are situations wheresrcset,href, or another attribute might be more suitable.
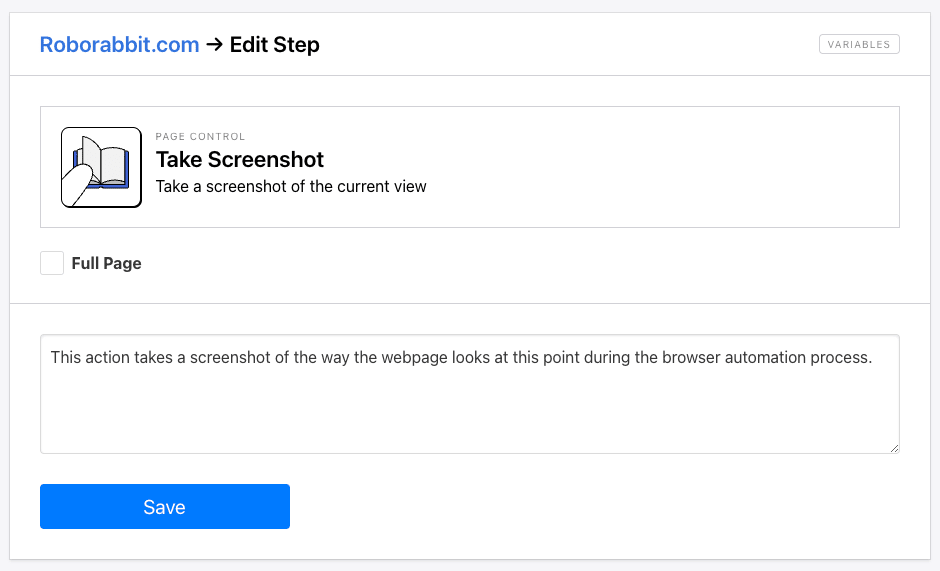
Option #3: Take Screenshot
Not every use case calls for original images. When context is needed, the Take Screenshot action can be helpful. It allows you to capture the way a webpage looks at a given moment. Customizing the viewport height and width in the task’s settings gives you more control over the output.
Output from this step is in the form of a link, which can be accessed in the log.
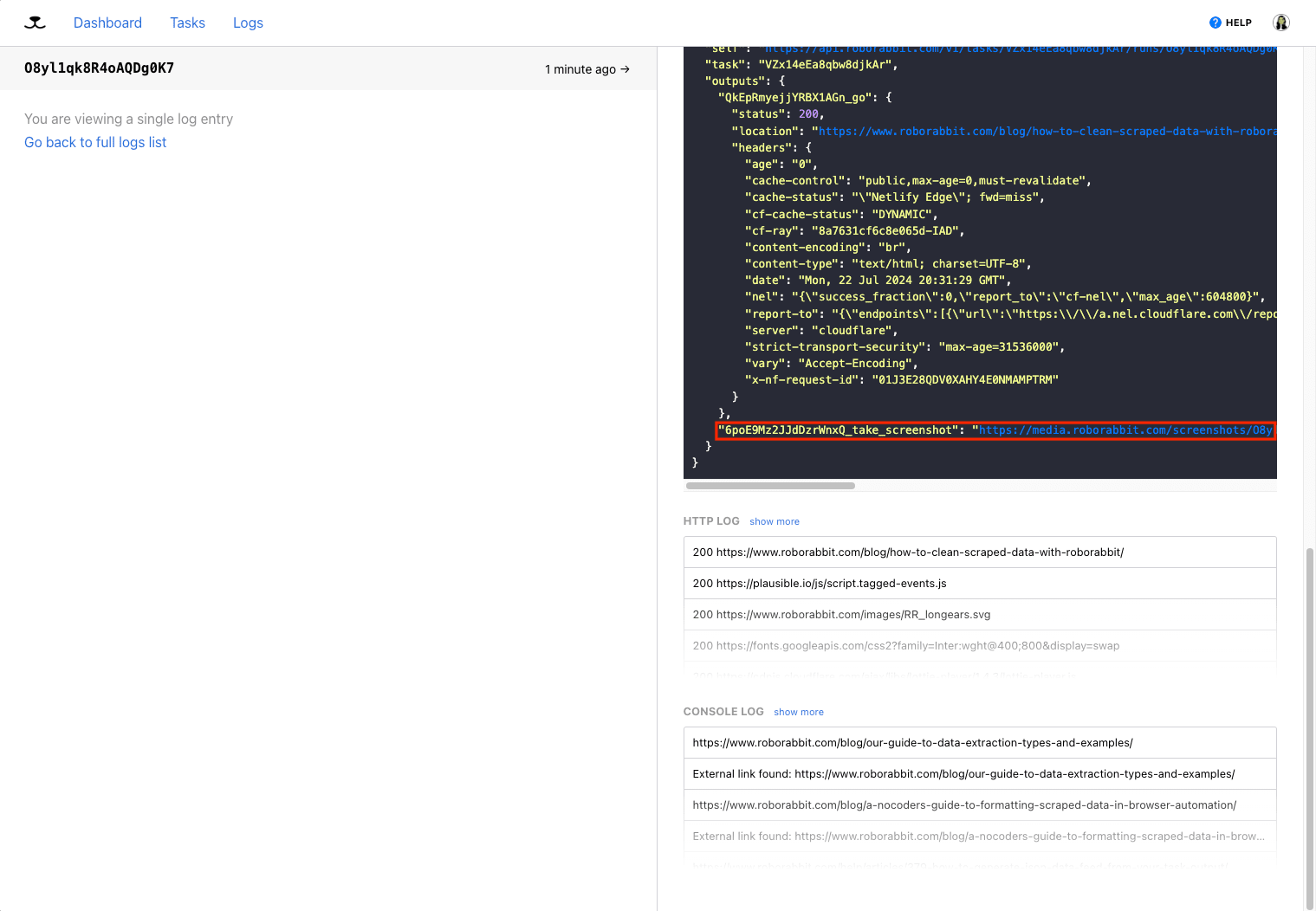
The screenshot will look something like this:
This method may not produce the highest quality images, but it is suitable for many situations, such as testing and archiving. It can provide more context on the webpage and may be more appropriate when access to the original images is unimportant. Additionally, the smaller file sizes require less storage space.
Option #4: Download
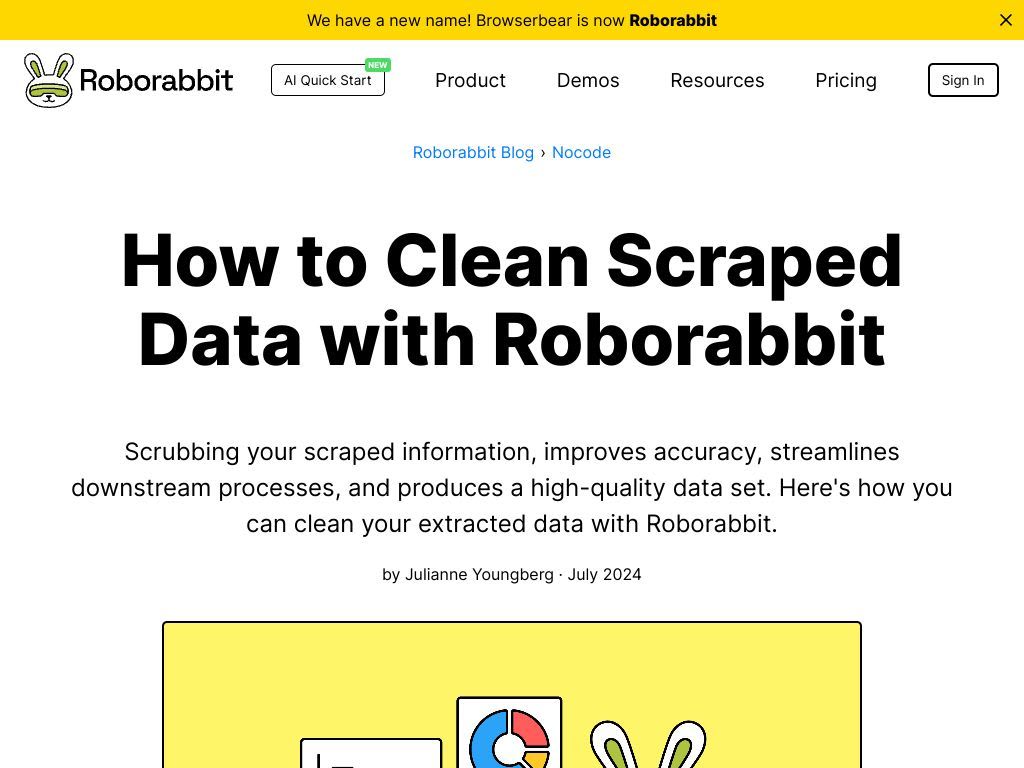
A less common but still incredibly helpful method of extracting images is with Roborabbit’s Download action. This is only relevant in use cases where the web page has an element (button or link) that initiates a download prompt. The file is downloaded, temporarily stored on Roborabbit servers, and can be accessed with a link.
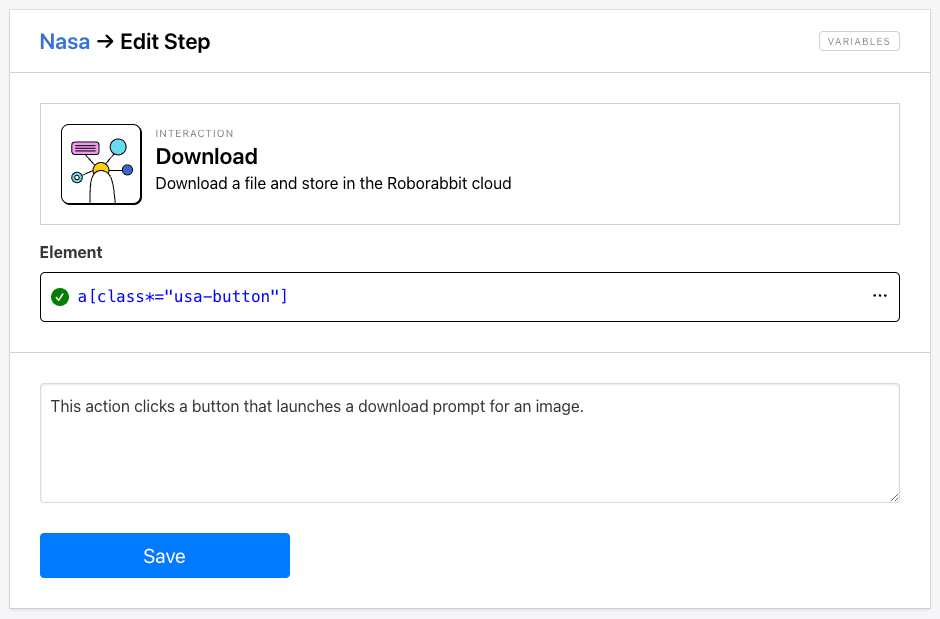
The link to the downloaded asset can be viewed in the log.
Hare Hint 🐰: Downloads are stored on Roborabbit servers for 24 hours, so it’s important to move them to a more durable storage location. You can do this manually for one-off use cases or automatically with a Zapier workflow.
The downloaded asset can look something like this:

Since original quality is preserved, using this action is ideal when you’re gathering visual assets or storing large quantities of images. You can then expand the automation according to your needs, which could mean storing and managing the files or routing them to another automated process.
Conclusion
Automatically extracting images from websites can be a powerful tool for a variety of use cases. With Roborabbit's browser automation capabilities, you have several options to quickly and efficiently save the images you need.
The Save Image and Save Attribute actions allow you to capture direct links to the original image files, preserving quality. This is great for building image datasets or curating visual assets. The Take Screenshot method is better suited for capturing webpage context, such as for testing or documentation purposes. And the Download action is ideal when you need to save large, high-quality image files.
Whichever approach you choose, Roborabbit makes it easy to integrate image extraction into your automated workflows. This can save you significant time and effort compared to manual web scraping. By understanding the strengths of each technique, you can select the right method to meet the needs of your specific project.
With Roborabbit's flexible image extraction tools at your fingertips, you'll be able to efficiently build up your visual assets and elevate your work to new heights. Happy automating!
